
本指南說明如何使用 TensorFlow 分析器提供的工具,追蹤 TensorFlow 模型的效能。您將瞭解如何理解模型在主機 (CPU)、裝置 (GPU) 或主機與裝置組合上的效能表現。
效能分析有助於瞭解模型中各種 TensorFlow 運算 (op) 的硬體資源耗用量 (時間和記憶體),並解決效能瓶頸,最終加快模型執行速度。
本指南將逐步說明如何安裝分析器、可用的各種工具、分析器收集效能資料的不同模式,以及一些最佳化模型效能的建議最佳做法。
如要分析模型在 Cloud TPU 上的效能,請參閱Cloud TPU 指南。
安裝分析器和 GPU 必要條件
使用 pip 安裝 TensorBoard 適用的分析器外掛程式。請注意,分析器需要最新版本的 TensorFlow 和 TensorBoard (>=2.2)。
pip install -U tensorboard_plugin_profile
如要在 GPU 上進行分析,您必須
- 符合 TensorFlow GPU 支援軟體需求中列出的 NVIDIA® GPU 驅動程式和 CUDA® Toolkit 需求。
確認路徑中存在 NVIDIA® CUDA® Profiling Tools Interface (CUPTI)
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
如果路徑中沒有 CUPTI,請執行以下指令,將 CUPTI 的安裝目錄新增至 $LD_LIBRARY_PATH 環境變數的最前面
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
然後,再次執行上方的 ldconfig 指令,確認已找到 CUPTI 程式庫。
解決權限問題
在 Docker 環境或 Linux 中使用 CUDA® Toolkit 執行效能分析時,您可能會遇到與 CUPTI 權限不足 (CUPTI_ERROR_INSUFFICIENT_PRIVILEGES) 相關的問題。前往NVIDIA 開發人員文件,進一步瞭解如何在 Linux 上解決這些問題。
如要解決 Docker 環境中的 CUPTI 權限問題,請執行
docker run option '--privileged=true'
分析器工具
從 TensorBoard 的「Profile」(分析) 標籤存取分析器,該標籤只有在您擷取一些模型資料後才會顯示。
分析器提供多種工具,可協助進行效能分析
- 總覽頁面
- 輸入管線分析器
- TensorFlow 統計資料
- 追蹤檢視器
- GPU 核心統計資料
- 記憶體分析工具
- Pod 檢視器
總覽頁面
總覽頁面提供模型在效能分析執行期間表現方式的頂層檢視畫面。此頁面會顯示主機和所有裝置的彙總總覽頁面,以及改善模型訓練效能的一些建議。您也可以在「Host」(主機) 下拉式選單中選取個別主機。
總覽頁面會以下列方式顯示資料
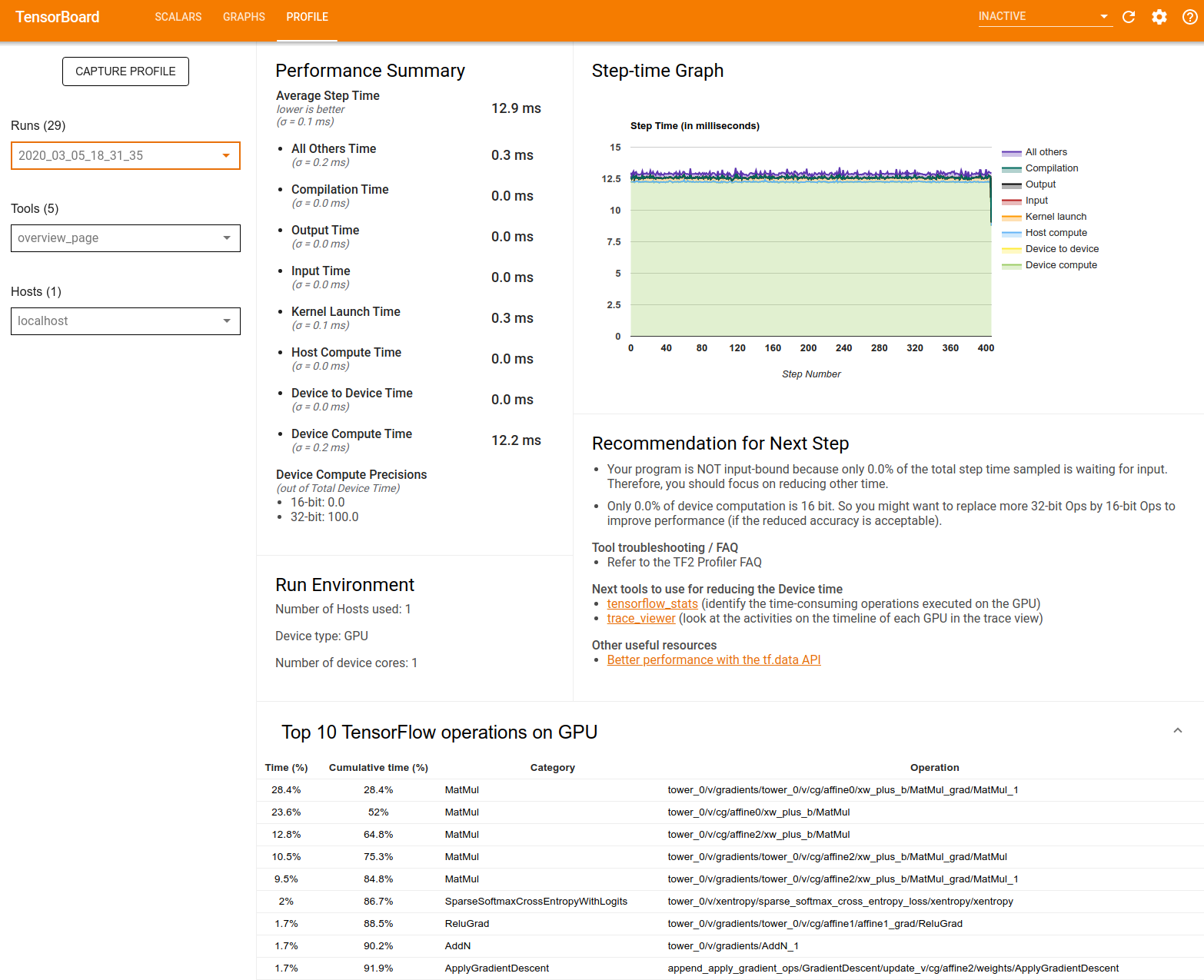
效能摘要:顯示模型效能的高階摘要。效能摘要包含兩個部分
步驟時間細分:將平均步驟時間細分為多個類別,指出時間花費在哪裡
- 編譯:編譯核心所花費的時間。
- 輸入:讀取輸入資料所花費的時間。
- 輸出:讀取輸出資料所花費的時間。
- 核心啟動:主機啟動核心所花費的時間
- 主機運算時間。
- 裝置對裝置通訊時間。
- 裝置端運算時間。
- 所有其他時間,包括 Python 額外負荷。
裝置運算精確度 - 報告使用 16 位元和 32 位元運算的裝置運算時間百分比。
步驟時間圖表:顯示所有取樣步驟的裝置步驟時間 (以毫秒為單位) 圖表。每個步驟都細分為多個類別 (以不同顏色表示),指出時間花費在哪裡。紅色區域對應於裝置閒置等待主機輸入資料的步驟時間部分。綠色區域顯示裝置實際運作的時間。
裝置 (例如 GPU) 上前 10 大 TensorFlow 運算:顯示裝置上執行時間最長的運算。
每一列都會顯示運算的自我時間 (以所有運算所花費時間的百分比表示)、累計時間、類別和名稱。
執行環境:顯示模型執行環境的高階摘要,包括
- 使用的主機數量。
- 裝置類型 (GPU/TPU)。
- 裝置核心數量。
後續步驟建議:報告模型是否受輸入限制,並建議您可用來找出及解決模型效能瓶頸的工具。
輸入管線分析器
當 TensorFlow 程式從檔案讀取資料時,會以管線方式從 TensorFlow 圖的頂端開始。讀取程序分為多個串聯的資料處理階段,其中一個階段的輸出是下一個階段的輸入。這種讀取資料的系統稱為輸入管線。
從檔案讀取記錄的典型管線包含下列階段
- 檔案讀取。
- 檔案預先處理 (選用)。
- 從主機到裝置的檔案傳輸。
效率低落的輸入管線可能會嚴重拖慢應用程式速度。當應用程式在輸入管線中花費大量時間時,即視為受輸入限制。使用從輸入管線分析器取得的深入分析,瞭解輸入管線效率低落的原因。
輸入管線分析器會立即告訴您程式是否受輸入限制,並逐步引導您進行裝置端和主機端分析,以偵錯輸入管線任何階段的效能瓶頸。
查看輸入管線效能指南,瞭解最佳化資料輸入管線的建議最佳做法。
輸入管線儀表板
如要開啟輸入管線分析器,請依序選取「Profile」(分析)、「Tools」(工具) 下拉式選單中的「input_pipeline_analyzer」。
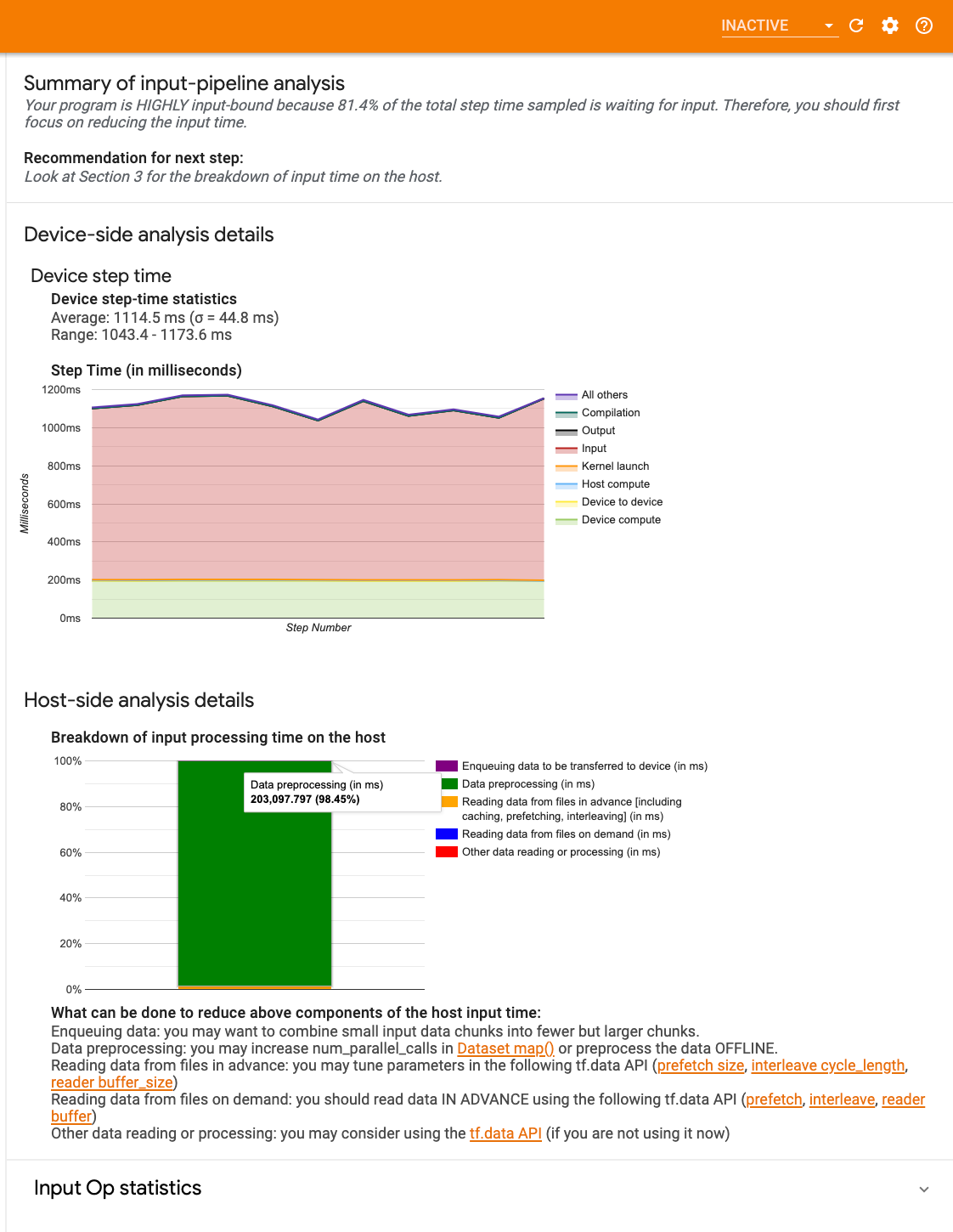
儀表板包含三個部分
- 摘要:摘要說明整體輸入管線,包含應用程式是否受輸入限制的相關資訊,以及受輸入限制的程度。
- 裝置端分析:顯示詳細的裝置端分析結果,包括裝置步驟時間,以及每個步驟中各核心等待輸入資料所花費的裝置時間範圍。
- 主機端分析:顯示主機端的詳細分析,包括主機端輸入處理時間的細分。
輸入管線摘要
「Summary」(摘要) 會報告程式是否受輸入限制,方法是呈現裝置等待主機輸入所花費的時間百分比。如果您使用的是已檢測的標準輸入管線,此工具會報告大部分輸入處理時間花費在哪裡。
裝置端分析
裝置端分析提供裝置端與主機端所花費時間的深入分析,以及裝置等待主機輸入資料所花費的時間。
- 步驟時間與步驟編號的關係圖:顯示所有取樣步驟的裝置步驟時間 (以毫秒為單位) 圖表。每個步驟都細分為多個類別 (以不同顏色表示),指出時間花費在哪裡。紅色區域對應於裝置閒置等待主機輸入資料的步驟時間部分。綠色區域顯示裝置實際運作的時間。
- 步驟時間統計資料:報告裝置步驟時間的平均值、標準差和範圍 ([最小值、最大值])。
主機端分析
主機端分析會報告主機端輸入處理時間 (在 tf.data API 運算中花費的時間) 的細分,分為多個類別
- 依需求從檔案讀取資料:在未快取、預先擷取和交錯的情況下,從檔案讀取資料所花費的時間。
- 提前從檔案讀取資料:讀取檔案所花費的時間,包括快取、預先擷取和交錯。
- 資料預先處理:在預先處理運算 (例如圖片解壓縮) 中花費的時間。
- 將資料排入佇列以傳輸到裝置:在將資料傳輸到裝置之前,將資料放入饋入佇列所花費的時間。
展開「Input Op Statistics」(輸入運算統計資料) 以檢查個別輸入運算及其類別的統計資料 (依執行時間細分)。
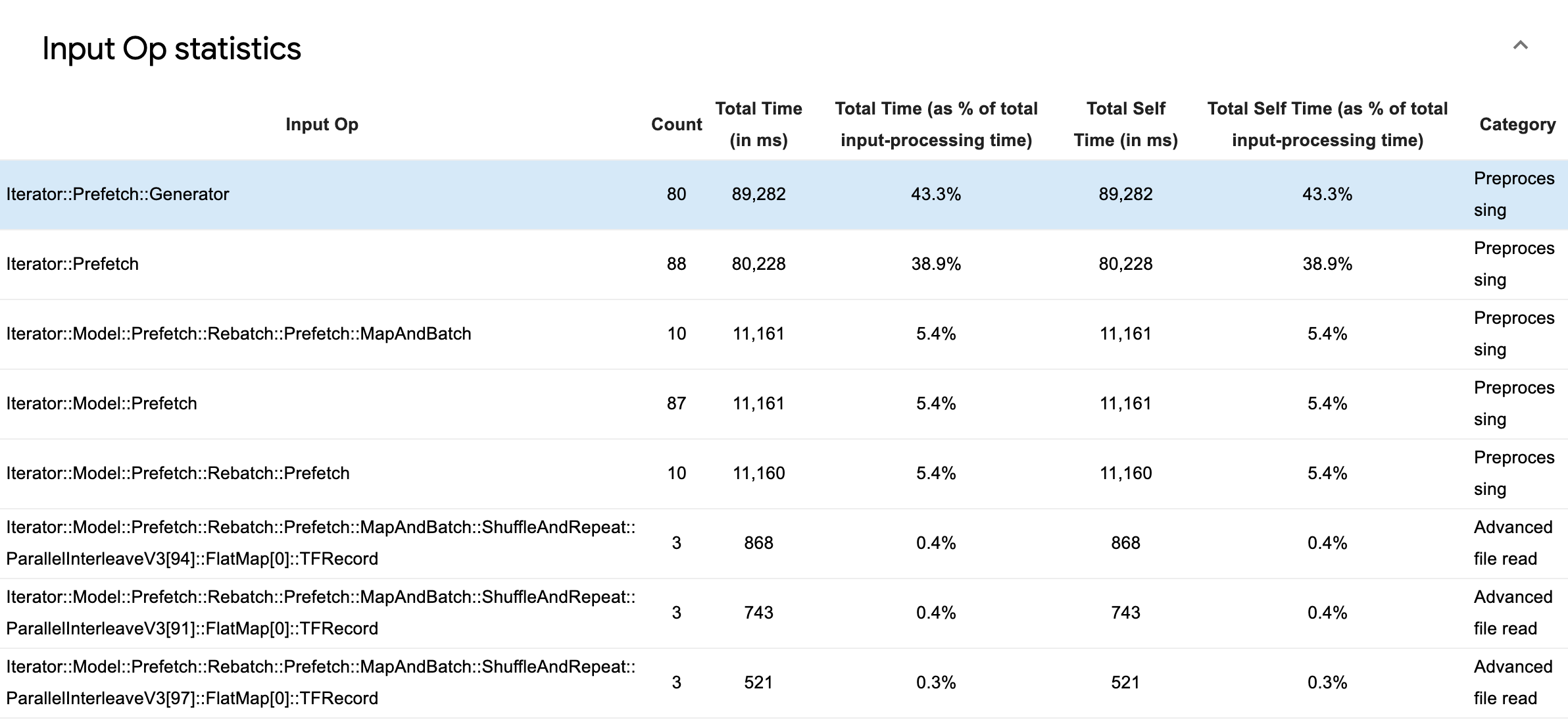
隨即會顯示來源資料表,每個項目都包含下列資訊
- Input Op (輸入運算):顯示輸入運算的 TensorFlow 運算名稱。
- Count (計數):顯示效能分析期間運算執行個體的總數。
- Total Time (in ms) (總時間 (毫秒)):顯示在每個執行個體中花費的時間累計總和。
- Total Time % (總時間百分比):顯示運算所花費的總時間,以輸入處理所花費總時間的分數表示。
- Total Self Time (in ms) (總自我時間 (毫秒)):顯示在每個執行個體中花費的自我時間累計總和。此處的自我時間是指在函式主體內花費的時間,不包括在函式呼叫的函式中花費的時間。
- Total Self Time % (總自我時間百分比)。顯示總自我時間,以輸入處理所花費總時間的分數表示。
- Category (類別)。顯示輸入運算的處理類別。
TensorFlow 統計資料
「TensorFlow Stats」(TensorFlow 統計資料) 工具會顯示在效能分析工作階段期間,主機或裝置上執行的每個 TensorFlow 運算 (op) 的效能。
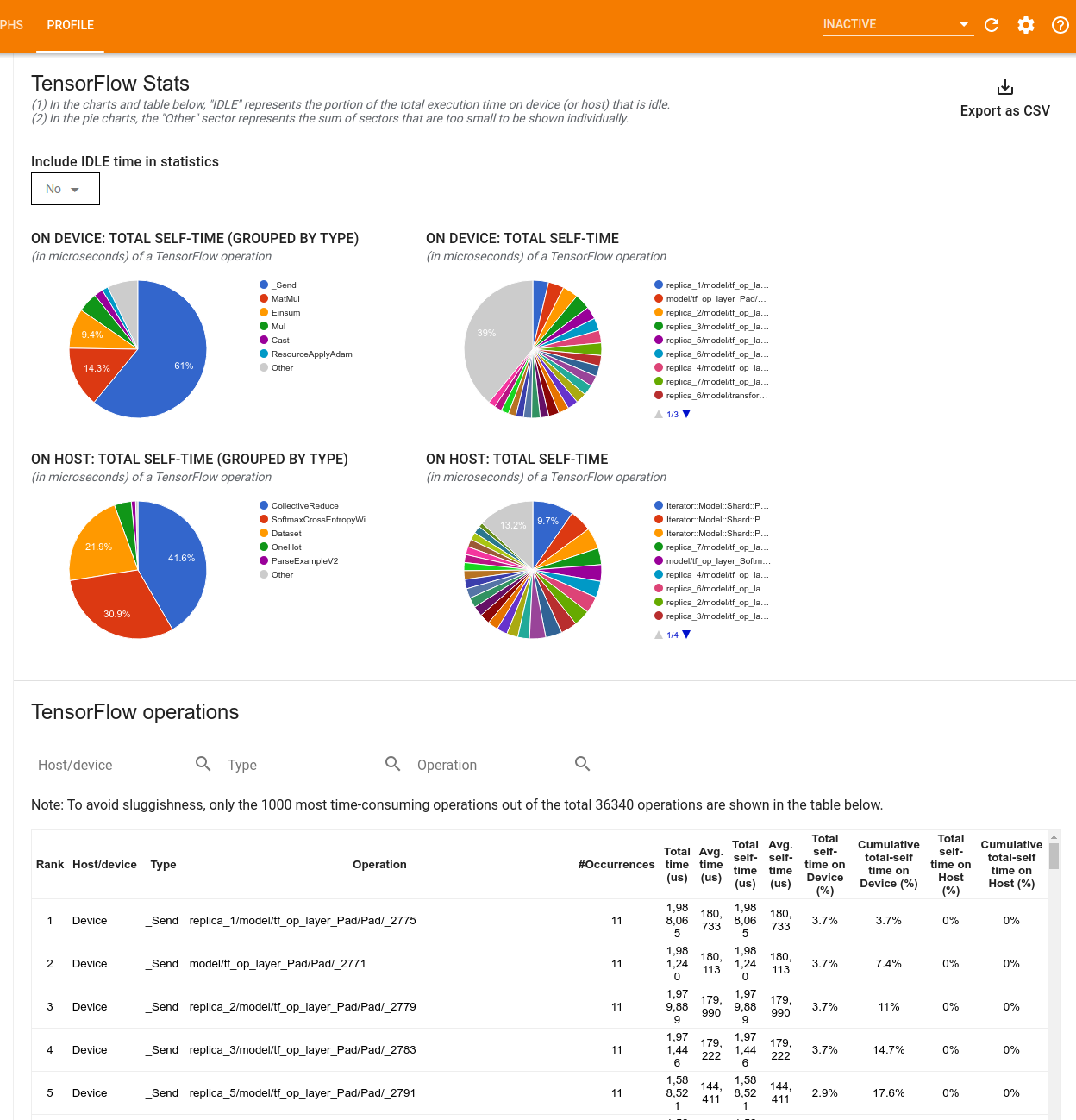
此工具會在兩個窗格中顯示效能資訊
上方窗格最多顯示四個圓餅圖
- 主機上每個運算的自我執行時間分佈。
- 主機上每個運算類型的自我執行時間分佈。
- 裝置上每個運算的自我執行時間分佈。
- 裝置上每個運算類型的自我執行時間分佈。
下方窗格會顯示一個表格,其中報告 TensorFlow 運算的相關資料,每個運算各佔一列,每種資料類型各佔一欄 (按一下欄標題即可排序欄)。按一下上方窗格右側的「Export as CSV button」(匯出為 CSV 按鈕),即可將此表格中的資料匯出為 CSV 檔案。
請注意,
如果有任何運算具有子運算
- 運算的總「累計」時間包括在子運算內花費的時間。
- 運算的總「自我」時間不包括在子運算內花費的時間。
如果運算在主機上執行
- 運算在裝置上產生的總自我時間百分比會是 0。
- 截至這個運算 (含) 為止,裝置上總自我時間的累計百分比會是 0。
如果運算在裝置上執行
- 這個運算在主機上產生的總自我時間百分比會是 0。
- 截至這個運算 (含) 為止,主機上總自我時間的累計百分比會是 0。
您可以選擇在圓餅圖和表格中納入或排除閒置時間。
追蹤檢視器
追蹤檢視器會顯示時間軸,其中顯示
- TensorFlow 模型執行的運算持續時間
- 系統的哪個部分 (主機或裝置) 執行了運算。一般來說,主機會執行輸入運算、預先處理訓練資料並將其傳輸到裝置,而裝置則會執行實際的模型訓練
追蹤檢視器可讓您找出模型中的效能問題,然後採取步驟解決這些問題。例如,在高階層級,您可以判斷輸入或模型訓練是否佔用大部分時間。深入探究後,您可以找出哪些運算的執行時間最長。請注意,追蹤檢視器每個裝置最多只能顯示 100 萬個事件。
追蹤檢視器介面
當您開啟追蹤檢視器時,畫面上會顯示您最近一次的執行
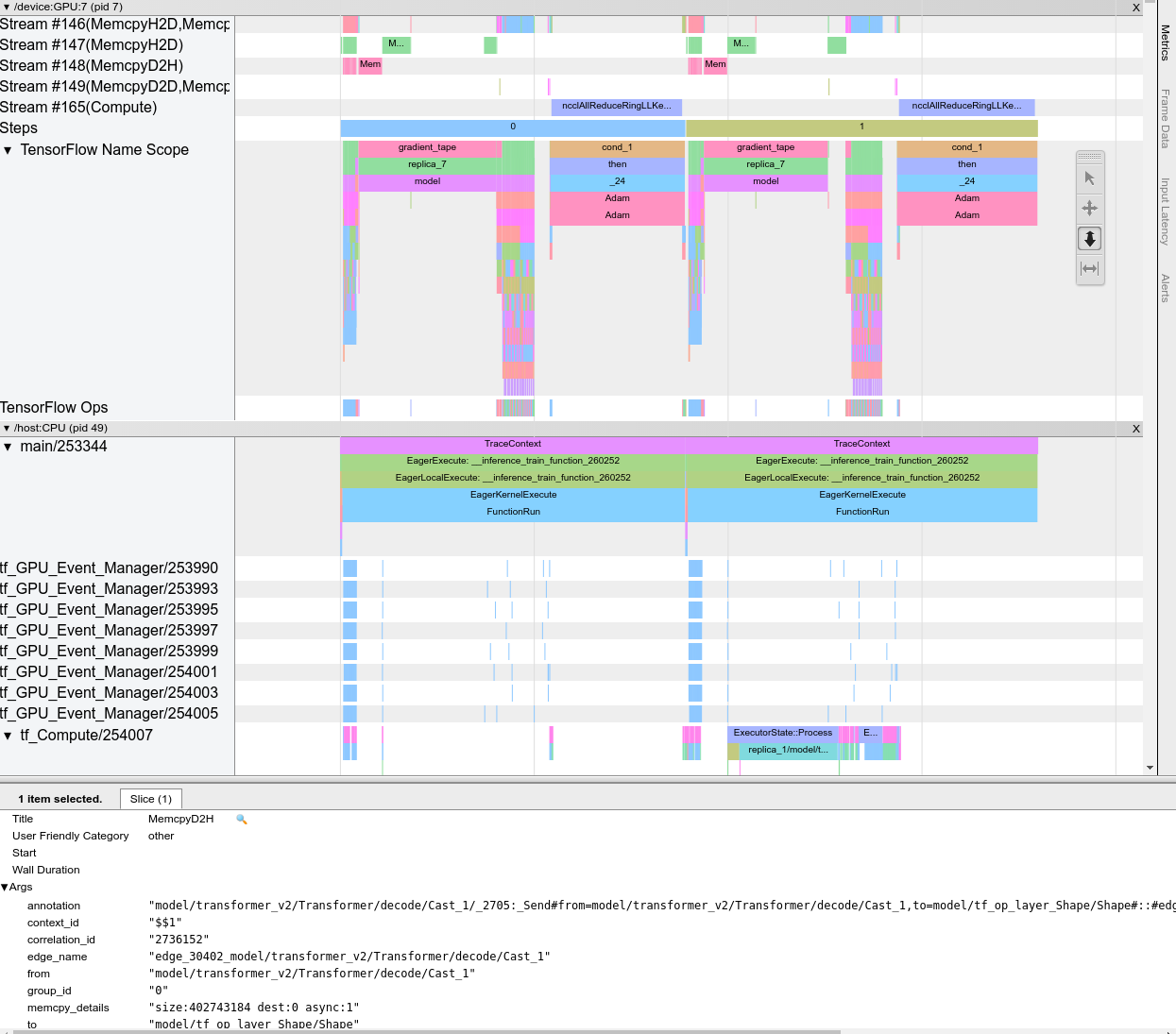
這個畫面包含下列主要元素
- 時間軸窗格:顯示裝置和主機隨著時間執行的運算。
- 詳細資料窗格:顯示時間軸窗格中所選運算的額外資訊。
時間軸窗格包含下列元素
- 頂端列:包含各種輔助控制項。
- 時間軸:顯示相對於追蹤開始時間的時間。
- 區段和軌跡標籤:每個區段都包含多個軌跡,且左側有一個三角形,您可以按一下三角形來展開和收合區段。系統中的每個處理元素都有一個區段。
- 工具選取器:包含各種與追蹤檢視器互動的工具,例如「Zoom」(縮放)、「Pan」(平移)、「Select」(選取) 和「Timing」(計時)。使用「Timing」(計時) 工具標記時間間隔。
- 事件:這些事件顯示運算的執行時間,或中繼事件 (例如訓練步驟) 的持續時間。
區段和軌跡
追蹤檢視器包含下列區段
- 每個裝置節點各有一個區段,標籤包含裝置晶片的編號和晶片內的裝置節點 (例如,
/device:GPU:0 (pid 0))。每個裝置節點區段都包含下列軌跡- Step (步驟):顯示裝置上執行的訓練步驟持續時間
- TensorFlow Ops (TensorFlow 運算):顯示裝置上執行的運算
- XLA Ops (XLA 運算):如果使用的編譯器是 XLA,則顯示裝置上執行的 XLA 運算 (每個 TensorFlow 運算都會轉譯為一或多個 XLA 運算。XLA 編譯器會將 XLA 運算轉譯為可在裝置上執行的程式碼)。
- 主機 CPU 上執行的每個執行緒各有一個區段,標籤為「Host Threads」(主機執行緒)。這個區段包含每個 CPU 執行緒的軌跡。請注意,您可以忽略區段標籤旁顯示的資訊。
事件
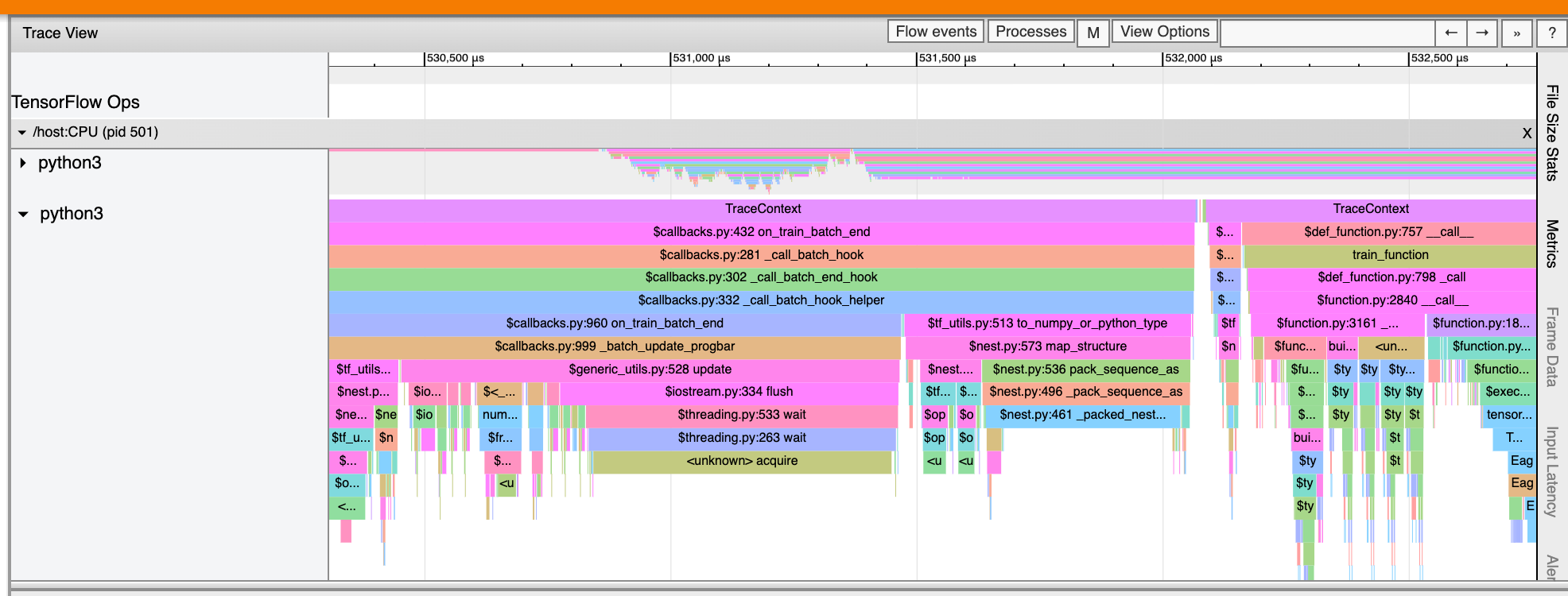
時間軸內的事件會以不同顏色顯示;顏色本身沒有特定意義。
追蹤檢視器也可以顯示 TensorFlow 程式中 Python 函式呼叫的追蹤記錄。如果您使用 tf.profiler.experimental.start API,則可以在啟動效能分析時使用 ProfilerOptions 具名元組啟用 Python 追蹤。或者,如果您使用取樣模式進行效能分析,則可以使用「Capture Profile」(擷取分析) 對話方塊中的下拉式選單選項來選取追蹤層級。
GPU 核心統計資料
這個工具會顯示每個 GPU 加速核心的效能統計資料和起始運算。
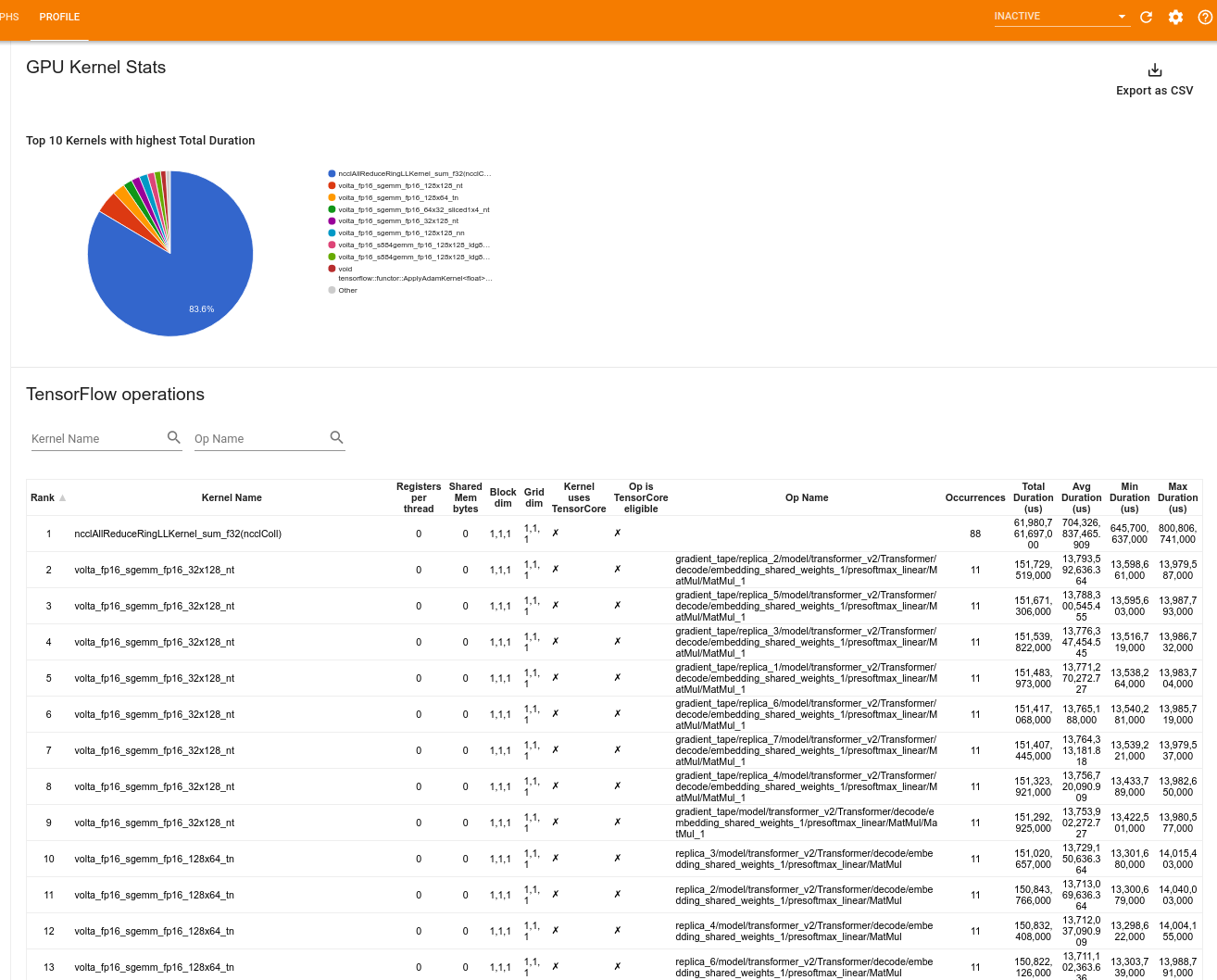
此工具會在兩個窗格中顯示資訊
上方窗格會顯示一個圓餅圖,其中顯示 CUDA 核心的總經過時間最長。
下方窗格會顯示一個表格,其中包含每個獨特核心運算配對的下列資料
- 依核心運算配對分組的 GPU 總經過時間降冪排序的排名。
- 已啟動核心的名稱。
- 核心使用的 GPU 暫存器數量。
- 以位元組為單位的共用記憶體 (靜態 + 動態共用) 總大小。
- 以
blockDim.x, blockDim.y, blockDim.z表示的區塊維度。 - 以
gridDim.x, gridDim.y, gridDim.z表示的格線維度。 - 運算是否符合使用 Tensor Core 的資格。
- 核心是否包含 Tensor Core 指令。
- 啟動這個核心的運算名稱。
- 這個核心運算配對的出現次數。
- GPU 總經過時間 (以微秒為單位)。
- GPU 平均經過時間 (以微秒為單位)。
- GPU 最短經過時間 (以微秒為單位)。
- GPU 最長經過時間 (以微秒為單位)。
記憶體分析工具
「Memory Profile」(記憶體分析) 工具會監控效能分析間隔期間裝置的記憶體用量。您可以使用這個工具來
- 偵錯記憶體不足 (OOM) 問題,方法是找出記憶體用量高峰,以及對應至 TensorFlow 運算的記憶體配置。您也可以偵錯執行 多租戶推論時可能發生的 OOM 問題。
- 偵錯記憶體片段化問題。
記憶體分析工具會在三個部分中顯示資料
- 記憶體分析摘要
- 記憶體時間軸圖表
- 記憶體細分表
記憶體分析摘要
這個部分會顯示 TensorFlow 程式記憶體分析的高階摘要,如下所示
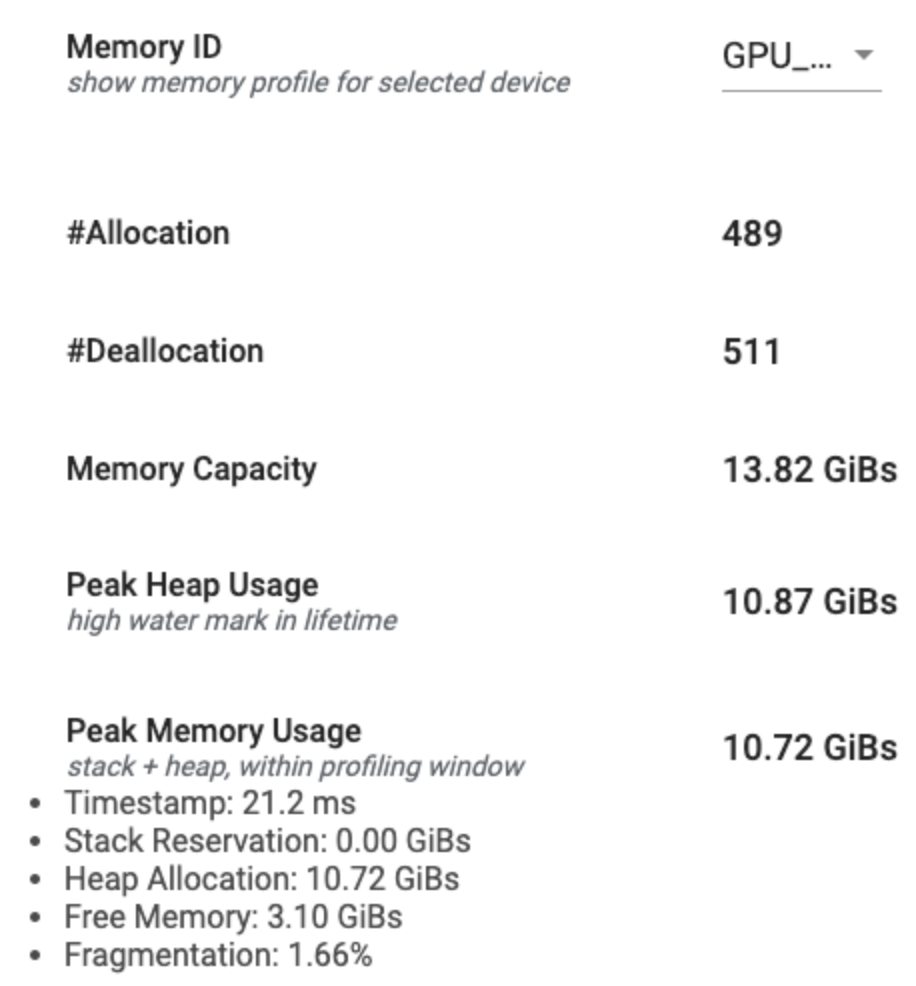
記憶體分析摘要包含六個欄位
- Memory ID (記憶體 ID):下拉式選單,列出所有可用的裝置記憶體系統。從下拉式選單中選取您要檢視的記憶體系統。
- #Allocation (配置次數):效能分析間隔期間進行的記憶體配置次數。
- #Deallocation (解除配置次數):效能分析間隔期間記憶體解除配置的次數
- Memory Capacity (記憶體容量):您選取的記憶體系統總容量 (以 GiB 為單位)。
- Peak Heap Usage (堆積用量高峰):自模型開始執行以來的記憶體用量高峰 (以 GiB 為單位)。
- Peak Memory Usage (記憶體用量高峰):效能分析間隔期間的記憶體用量高峰 (以 GiB 為單位)。此欄位包含下列子欄位
- Timestamp (時間戳記):時間軸圖表中記憶體用量高峰發生時的時間戳記。
- Stack Reservation (堆疊保留量):在堆疊上保留的記憶體量 (以 GiB 為單位)。
- Heap Allocation (堆積配置量):在堆積上配置的記憶體量 (以 GiB 為單位)。
- Free Memory (可用記憶體):可用記憶體量 (以 GiB 為單位)。記憶體容量是堆疊保留量、堆積配置量和可用記憶體的總和。
- Fragmentation (片段化):片段化百分比 (越低越好)。計算方式為
(1 - 最大可用記憶體區塊大小 / 可用記憶體總量)的百分比。
記憶體時間軸圖表
這個部分會顯示記憶體用量 (以 GiB 為單位) 和片段化百分比與時間 (以毫秒為單位) 的關係圖。
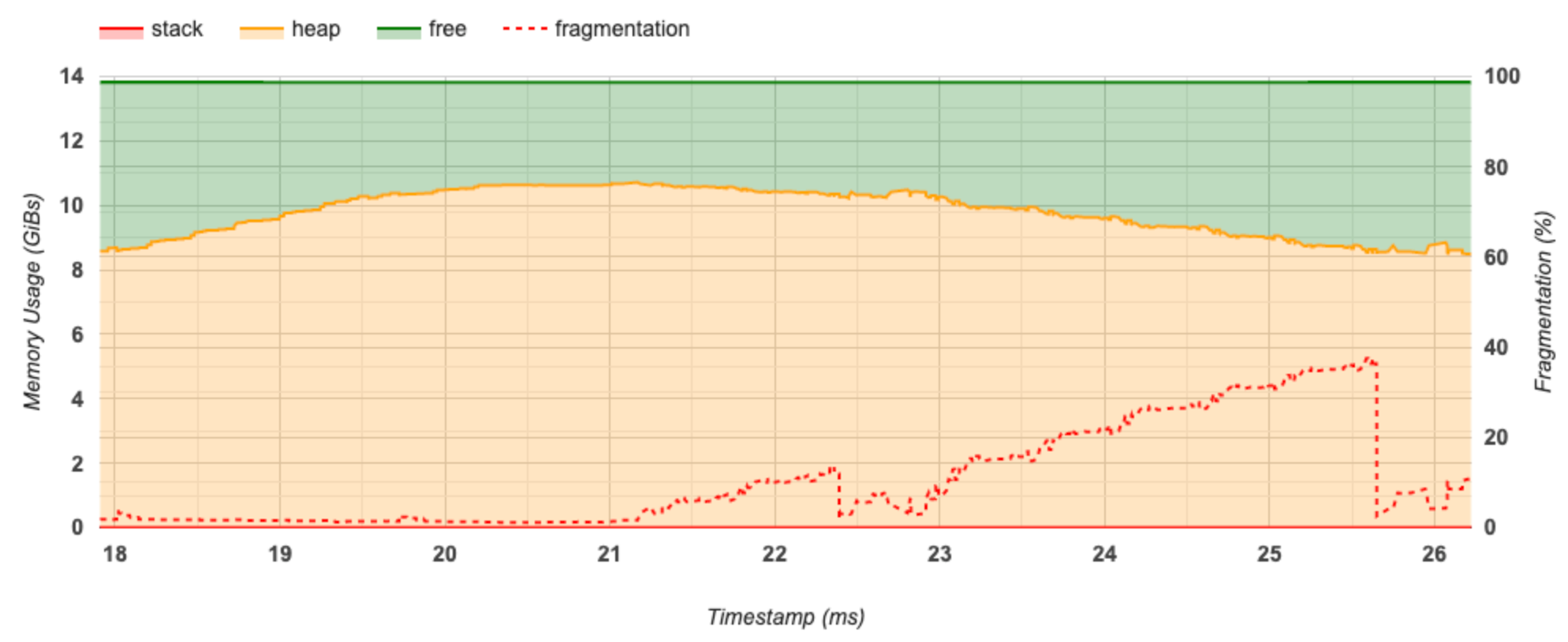
X 軸代表效能分析間隔的時間軸 (以毫秒為單位)。左側 Y 軸代表記憶體用量 (以 GiB 為單位),右側 Y 軸代表片段化百分比。在 X 軸上的每個時間點,總記憶體都會細分為三個類別:堆疊 (紅色)、堆積 (橘色) 和可用 (綠色)。將滑鼠游標停留在特定時間戳記上方,即可查看該點記憶體配置/解除配置事件的詳細資料,如下所示
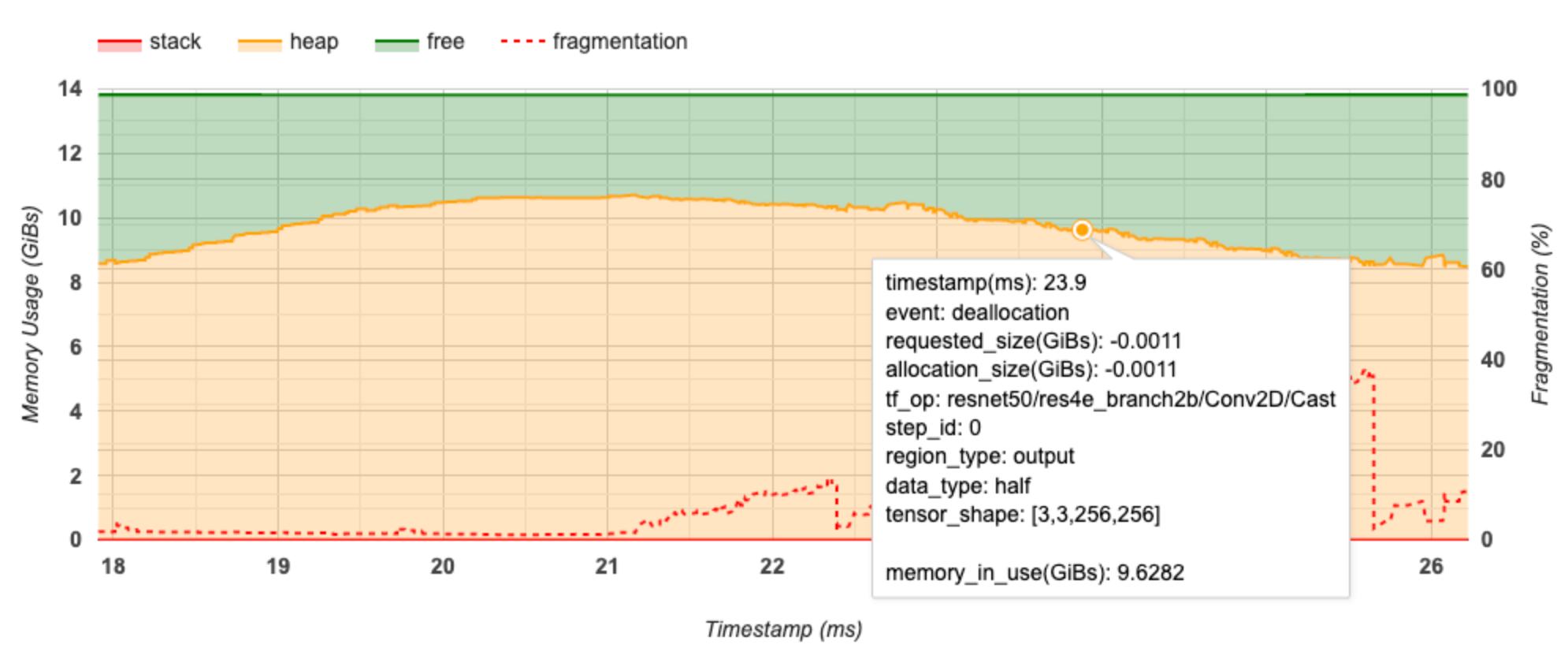
彈出式視窗會顯示下列資訊
- timestamp(ms) (時間戳記 (毫秒)):時間軸上所選事件的位置。
- event (事件):事件類型 (配置或解除配置)。
- requested_size(GiBs) (要求大小 (GiB)):要求的記憶體量。解除配置事件會是負數。
- allocation_size(GiBs) (配置大小 (GiB)):實際配置的記憶體量。解除配置事件會是負數。
- tf_op:要求配置/解除配置的 TensorFlow 運算。
- step_id (步驟 ID):事件發生的訓練步驟。
- region_type (區域類型):已配置記憶體的資料實體類型。可能的值包括:
temp(暫時性)、output(啟動和梯度),以及persist/dynamic(權重和常數)。 - data_type (資料類型):張量元素類型 (例如,8 位元不帶正負號整數的 uint8)。
- tensor_shape (張量形狀):正在配置/解除配置的張量形狀。
- memory_in_use(GiBs) (使用中記憶體 (GiB)):此時間點使用中的記憶體總量。
記憶體細分表
此表格顯示效能分析間隔期間記憶體用量高峰時的現用記憶體配置。
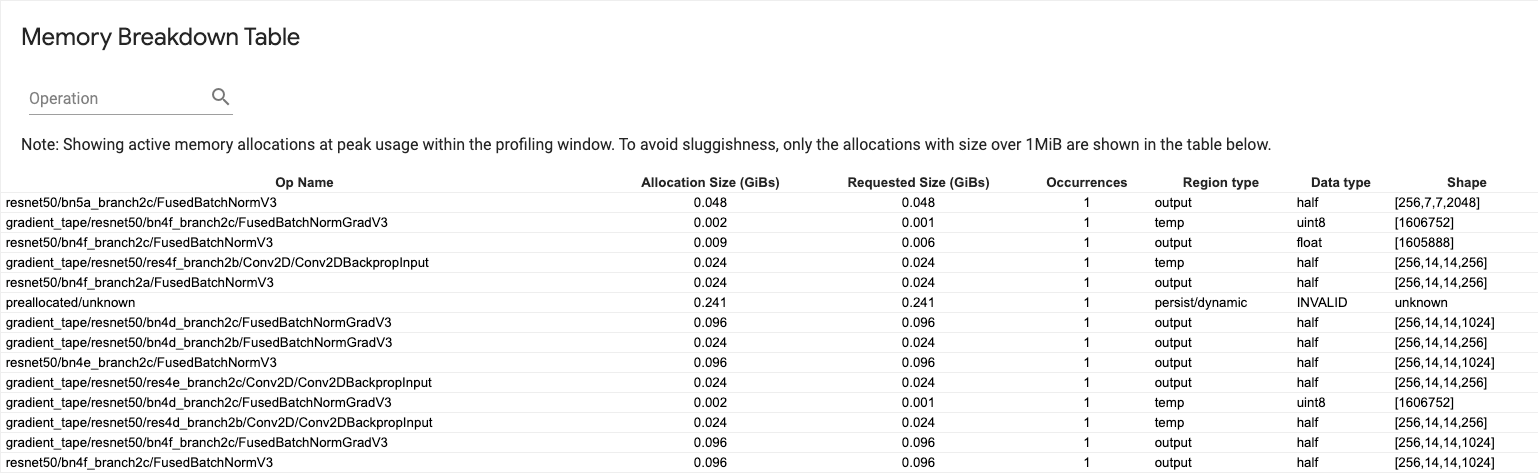
每個 TensorFlow 運算各佔一列,且每一列都有下列欄
- Op Name (運算名稱):TensorFlow 運算的名稱。
- Allocation Size (GiBs) (配置大小 (GiB)):配置給這個運算的記憶體總量。
- Requested Size (GiBs) (要求大小 (GiB)):要求這個運算的記憶體總量。
- Occurrences (出現次數):這個運算的配置次數。
- Region type (區域類型):已配置記憶體的資料實體類型。可能的值包括:
temp(暫時性)、output(啟動和梯度),以及persist/dynamic(權重和常數)。 - Data type (資料類型):張量元素類型。
- Shape (形狀):已配置張量的形狀。
Pod 檢視器
「Pod Viewer」(Pod 檢視器) 工具會顯示所有工作站中訓練步驟的細分。
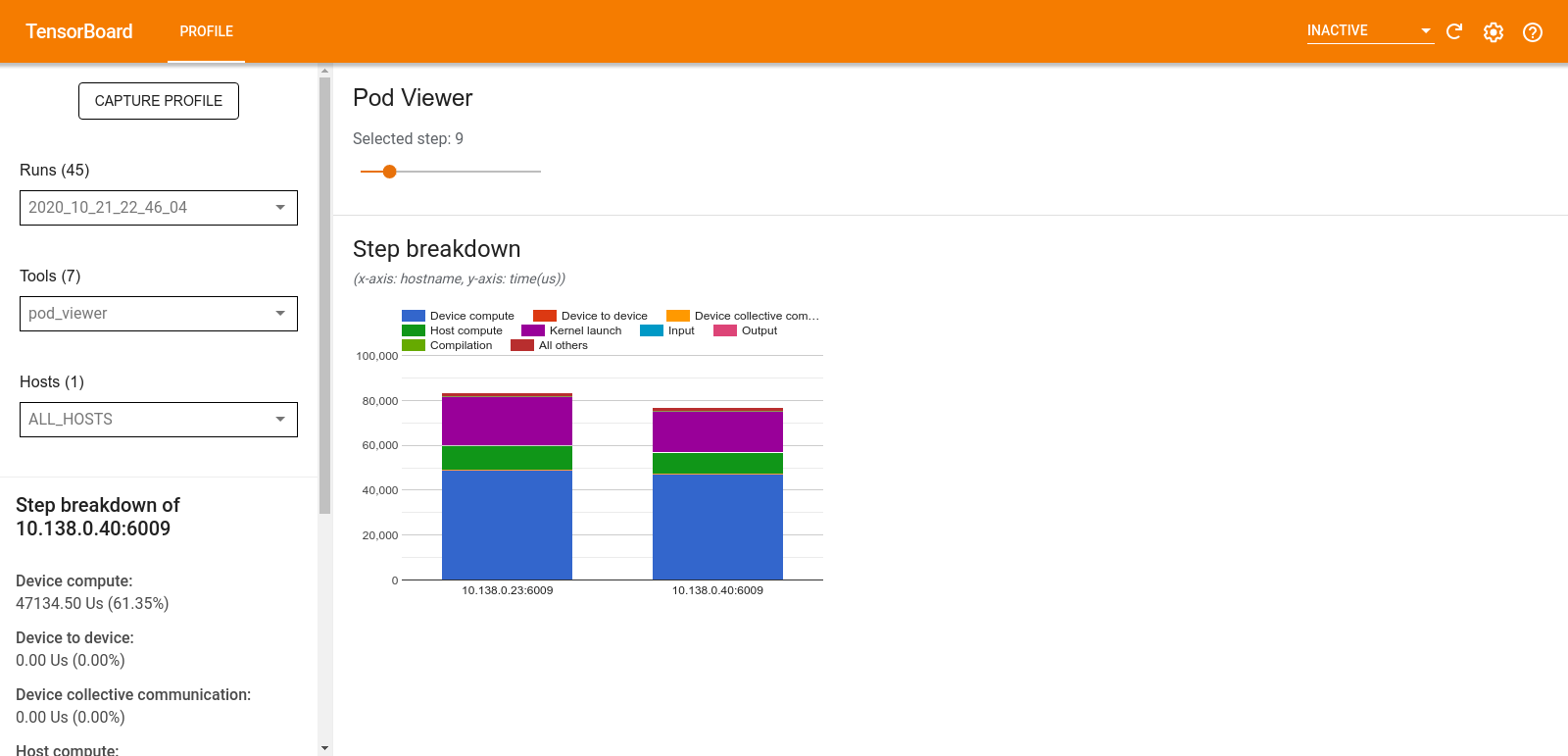
- 上方窗格有一個滑桿,可用於選取步驟編號。
- 下方窗格會顯示堆疊直條圖。這是高階檢視畫面,顯示堆疊在一起的細分步驟時間類別。每個堆疊直條代表一個獨特的工作站。
- 當您將滑鼠游標停留在堆疊直條上方時,左側的資訊卡會顯示步驟細分的更多詳細資料。
tf.data 瓶頸分析
tf.data 瓶頸分析工具會自動偵測程式中 tf.data 輸入管線的瓶頸,並提供如何修正這些瓶頸的建議。這個工具適用於任何使用 tf.data 的程式,無論平台為何 (CPU/GPU/TPU)。其分析和建議均以本指南為基礎。
這個工具會透過下列步驟偵測瓶頸
- 找出受輸入限制最嚴重的主機。
- 找出
tf.data輸入管線最慢的執行。 - 從分析器追蹤記錄重建輸入管線圖。
- 找出輸入管線圖中的關鍵路徑。
- 將關鍵路徑上最慢的轉換識別為瓶頸。
UI 分為三個部分:「Performance Analysis Summary」(效能分析摘要)、「Summary of All Input Pipelines」(所有輸入管線摘要) 和「Input Pipeline Graph」(輸入管線圖)。
效能分析摘要

這個部分提供分析摘要。其中報告在效能分析中偵測到的緩慢 tf.data 輸入管線。這個部分也會顯示受輸入限制最嚴重的主機及其最慢的輸入管線 (具有最大延遲時間)。最重要的是,這個部分會識別輸入管線的哪個部分是瓶頸,以及如何修正瓶頸。瓶頸資訊會與迭代器類型及其長名稱一併提供。
如何讀取 tf.data 迭代器的長名稱
長名稱的格式為 Iterator::<Dataset_1>::...::<Dataset_n>。在長名稱中,<Dataset_n> 符合迭代器類型,而長名稱中的其他資料集則代表下游轉換。
例如,假設有下列輸入管線資料集
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
上述資料集的迭代器長名稱會是
| 迭代器類型 | 長名稱 |
|---|---|
| Range | Iterator::Batch::Repeat::Map::Range |
| Map | Iterator::Batch::Repeat::Map |
| Repeat | Iterator::Batch::Repeat |
| Batch | Iterator::Batch |
所有輸入管線摘要
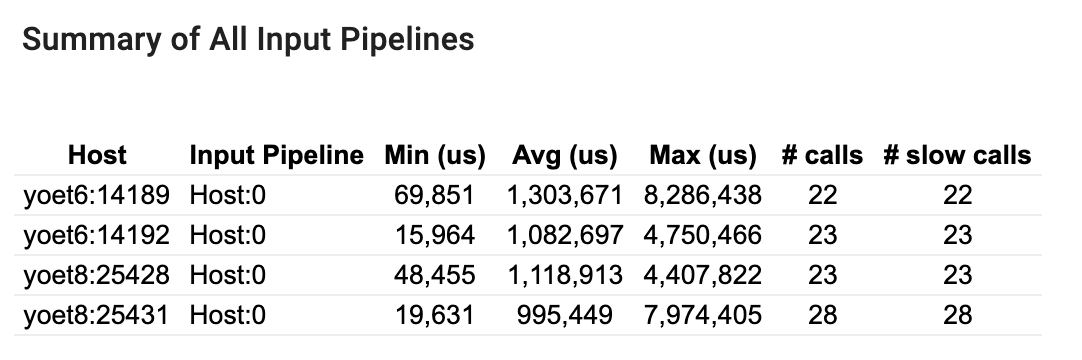
本節概述所有主機上的所有輸入管線。通常只有一個輸入管線。當使用分散式策略時,會有一個主機輸入管線執行程式的 tf.data 程式碼,以及多個裝置輸入管線從主機輸入管線擷取資料並傳輸到裝置。
針對每個輸入管線,它會顯示其執行時間的統計資訊。如果呼叫時間超過 50 微秒,則會被視為慢速呼叫。
輸入管線圖表

本節顯示包含執行時間資訊的輸入管線圖表。您可以使用「Host」和「Input Pipeline」來選擇要查看的主機和輸入管線。輸入管線的執行會依執行時間降序排序,您可以使用「Rank」下拉式選單選擇排序方式。
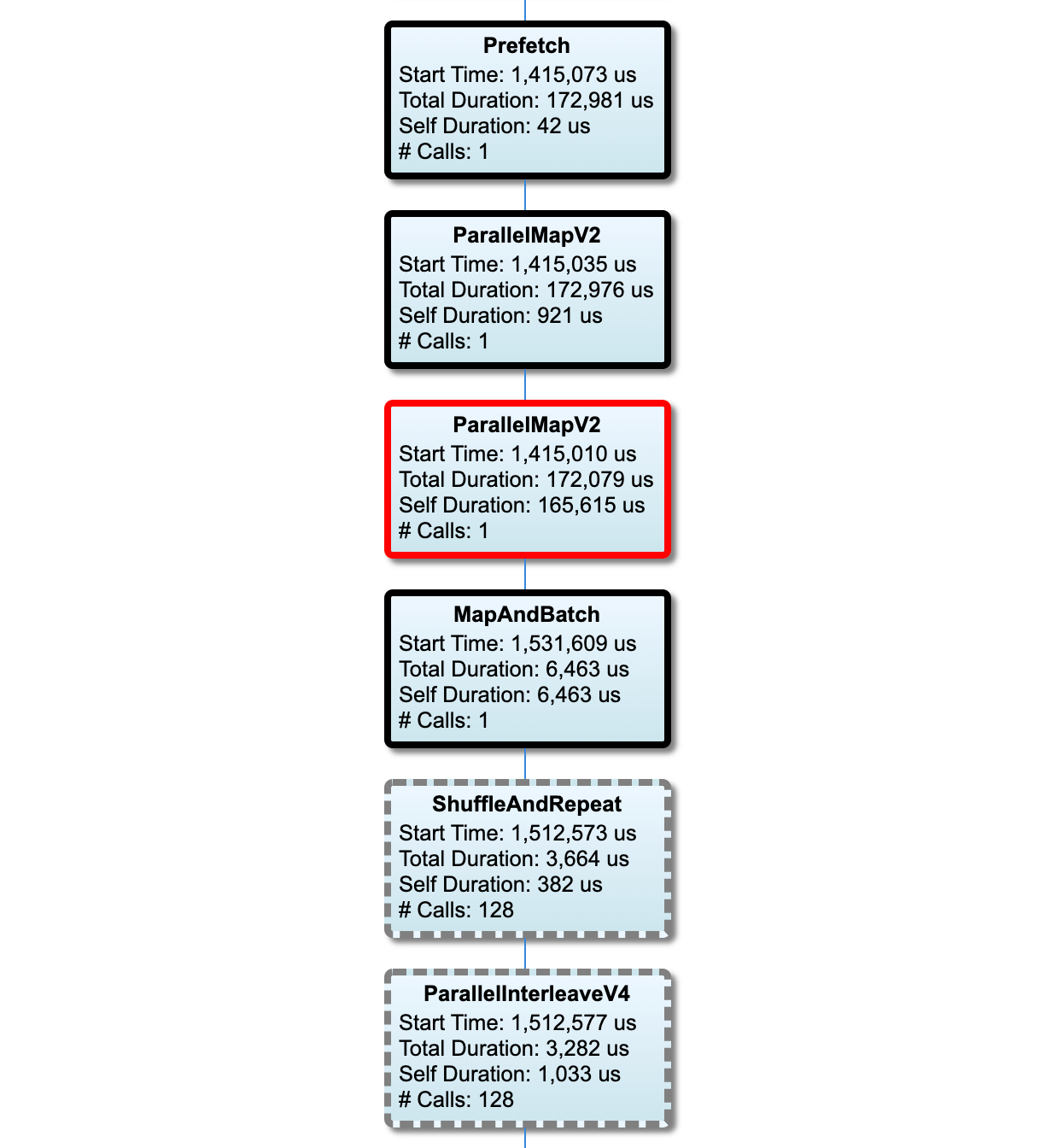
關鍵路徑上的節點具有粗體外框。瓶頸節點(即關鍵路徑上自我時間最長的節點)具有紅色外框。其他非關鍵節點則具有灰色虛線外框。
在每個節點中,「Start Time」表示執行的開始時間。同一個節點可能會執行多次,例如,如果輸入管線中有 Batch op。如果執行多次,則它是第一次執行的開始時間。
「Total Duration」是執行的實際時間。如果執行多次,則它是所有執行實際時間的總和。
「Self Time」是「Total Time」減去與其直接子節點重疊的時間。
「# Calls」是輸入管線執行的次數。
收集效能資料
TensorFlow Profiler 會收集 TensorFlow 模型的host活動和 GPU 追蹤。您可以設定 Profiler 透過程式化模式或取樣模式收集效能資料。
效能分析 API
您可以使用下列 API 執行效能分析。
使用 TensorBoard Keras Callback 的程式化模式 (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])使用
tf.profilerFunction API 的程式化模式tf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()使用情境管理器的程式化模式
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
取樣模式:透過使用
tf.profiler.experimental.server.start啟動 gRPC 伺服器來對 TensorFlow 模型執行隨選效能分析。啟動 gRPC 伺服器並執行模型後,您可以透過 TensorBoard 效能分析外掛程式中的「Capture Profile」按鈕擷取效能分析。如果 TensorBoard 執行個體尚未執行,請使用上方「Install profiler」章節中的指令碼啟動 TensorBoard 執行個體。例如,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)多個 worker 效能分析範例
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
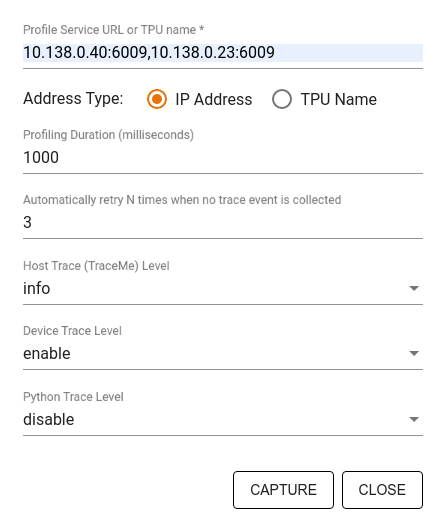
使用「Capture Profile」對話方塊指定
- 以逗號分隔的效能分析服務 URL 或 TPU 名稱清單。
- 效能分析持續時間。
- 裝置、主機和 Python 函式呼叫追蹤的層級。
- 如果第一次擷取效能分析失敗,您希望 Profiler 重試擷取效能分析的次數。
自訂訓練迴圈的效能分析
若要對 TensorFlow 程式碼中的自訂訓練迴圈進行效能分析,請使用 tf.profiler.experimental.Trace API 檢測訓練迴圈,以標記 Profiler 的步驟邊界。
`name` 引數用作步驟名稱的前置字串,step_num 關鍵字引數會附加在步驟名稱中,而 _r 關鍵字引數會使此追蹤事件被 Profiler 處理為步驟事件。
例如,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
這將啟用 Profiler 的步驟式效能分析,並使步驟事件顯示在追蹤檢視器中。
確保將資料集迭代器包含在 tf.profiler.experimental.Trace 情境中,以便準確分析輸入管線。
下方的程式碼片段是一種反模式
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
效能分析使用案例
效能分析器涵蓋沿四個不同軸向的許多使用案例。某些組合目前受到支援,其他組合將在未來新增。部分使用案例包括
- 本機與遠端效能分析:這是設定效能分析環境的兩種常見方式。在本機效能分析中,效能分析 API 會在執行模型的同一部機器上呼叫,例如,具有 GPU 的本機工作站。在遠端效能分析中,效能分析 API 會在與模型執行所在機器不同的機器上呼叫,例如,在 Cloud TPU 上。
- 多個 worker 效能分析:當使用 TensorFlow 的分散式訓練功能時,您可以對多部機器進行效能分析。
- 硬體平台:效能分析 CPU、GPU 和 TPU。
下表快速概述上述 TensorFlow 支援的使用案例
| 效能分析 API | 本機 | 遠端 | 多個 worker | 硬體平台 |
|---|---|---|---|---|
| TensorBoard Keras 回呼 | 支援 | 不支援 | 不支援 | CPU、GPU |
tf.profiler.experimental start/stop API |
支援 | 不支援 | 不支援 | CPU、GPU |
tf.profiler.experimental client.trace API |
支援 | 支援 | 支援 | CPU、GPU、TPU |
| 情境管理器 API | 支援 | 不支援 | 不支援 | CPU、GPU |
達到最佳模型效能的最佳實務做法
針對您的 TensorFlow 模型,視情況採用下列建議以達到最佳效能。
一般而言,請在裝置上執行所有轉換,並確保針對您的平台使用最新相容版本的程式庫,例如 cuDNN 和 Intel MKL。
最佳化輸入資料管線
使用來自 [#input_pipeline_analyzer] 的資料來最佳化您的資料輸入管線。有效率的資料輸入管線可以透過減少裝置閒置時間,大幅提升模型執行速度。嘗試採用「Better performance with the tf.data API」指南和下文詳述的最佳實務做法,讓您的資料輸入管線更有效率。
一般而言,平行處理任何不需要循序執行的運算,可以大幅最佳化資料輸入管線。
在許多情況下,變更某些呼叫的順序或調整引數,使其最適合您的模型,會有所幫助。在最佳化輸入資料管線時,請僅基準測試資料載入器,而不要基準測試訓練和反向傳播步驟,以獨立量化最佳化的效果。
嘗試使用合成資料執行模型,以檢查輸入管線是否為效能瓶頸。
針對多 GPU 訓練使用
tf.data.Dataset.shard。確保在輸入迴圈中儘早分片,以防止吞吐量降低。使用 TFRecords 時,請確保分片 TFRecords 的清單,而不是 TFRecords 的內容。透過使用
tf.data.AUTOTUNE動態設定num_parallel_calls的值,平行處理多個運算。考慮限制
tf.data.Dataset.from_generator的使用,因為與純 TensorFlow 運算相比,它速度較慢。考慮限制
tf.py_function的使用,因為它無法序列化,且不支援在分散式 TensorFlow 中執行。使用
tf.data.Options控制輸入管線的靜態最佳化。
另請閱讀 tf.data 效能分析 指南,以取得更多關於最佳化輸入管線的指引。
最佳化資料擴增
使用影像資料時,在套用空間轉換(例如翻轉、裁剪、旋轉等)後,再轉換為不同的資料類型,使資料擴增更有效率。
使用 NVIDIA® DALI
在某些情況下,例如當您的系統具有高 GPU 對 CPU 比率時,上述所有最佳化可能不足以消除因 CPU 週期限制而導致的資料載入器瓶頸。
如果您使用 NVIDIA® GPU 進行電腦視覺和音訊深度學習應用程式,請考慮使用資料載入程式庫 (DALI) 來加速資料管線。
查看 NVIDIA® DALI: Operations 文件,以取得支援的 DALI 運算清單。
使用執行緒和並行執行
使用 tf.config.threading API 在多個 CPU 執行緒上執行運算,以加快執行速度。
TensorFlow 預設會自動設定平行執行緒的數量。可用於執行 TensorFlow 運算的執行緒集區取決於可用的 CPU 執行緒數量。
使用 tf.config.threading.set_intra_op_parallelism_threads 控制單一運算的最大平行加速。請注意,如果您平行執行多個運算,它們將共用可用的執行緒集區。
如果您有獨立的非封鎖運算(圖表上它們之間沒有定向路徑的運算),請使用 tf.config.threading.set_inter_op_parallelism_threads 使用可用的執行緒集區並行執行它們。
雜項
當在 NVIDIA® GPU 上使用較小的模型時,您可以設定 tf.compat.v1.ConfigProto.force_gpu_compatible=True,強制所有 CPU 張量使用 CUDA 固定記憶體配置,以大幅提升模型效能。但是,對於未知/非常大的模型使用此選項時請謹慎,因為這可能會對主機 (CPU) 效能產生負面影響。
提升裝置效能
遵循此處和 GPU 效能最佳化指南中詳述的最佳實務做法,以最佳化裝置上 TensorFlow 模型的效能。
如果您使用 NVIDIA GPU,請執行下列命令將 GPU 和記憶體使用率記錄到 CSV 檔案
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
設定資料版面配置
使用包含通道資訊的資料(例如影像)時,最佳化資料版面配置格式,使其偏好通道在後 (NHWC 而非 NCHW)。
通道在後資料格式可提升 Tensor Core 使用率,並提供顯著的效能改進,尤其是在與 AMP 結合的卷積模型中。NCHW 資料版面配置仍然可以由 Tensor Core 操作,但由於自動轉置運算,會引入額外的 overhead。
您可以透過為層(例如 tf.keras.layers.Conv2D、tf.keras.layers.Conv3D 和 tf.keras.layers.RandomRotation)設定 data_format="channels_last",來最佳化資料版面配置以偏好 NHWC 版面配置。
使用 tf.keras.backend.set_image_data_format 設定 Keras 後端 API 的預設資料版面配置格式。
最大化 L2 快取
當使用 NVIDIA® GPU 時,在訓練迴圈之前執行下方的程式碼片段,將 L2 擷取粒度最大化為 128 位元組。
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
設定 GPU 執行緒使用量
GPU 執行緒模式決定 GPU 執行緒的使用方式。
將執行緒模式設定為 gpu_private,以確保預先處理不會佔用所有 GPU 執行緒。這將減少訓練期間的核心啟動延遲。您也可以設定每個 GPU 的執行緒數量。使用環境變數設定這些值。
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
設定 GPU 記憶體選項
一般而言,增加批次大小並縮放模型,以更充分利用 GPU 並獲得更高的吞吐量。請注意,增加批次大小會變更模型的準確度,因此需要透過調整超參數(例如學習率)來縮放模型,以達到目標準確度。
此外,使用 tf.config.experimental.set_memory_growth 允許 GPU 記憶體成長,以防止所有可用記憶體完全配置給僅需要一小部分記憶體的運算。這允許其他消耗 GPU 記憶體的程序在同一部裝置上執行。
若要瞭解更多資訊,請查看 GPU 指南中的「Limiting GPU memory growth」指引以深入瞭解。
雜項
將訓練迷你批次大小(在訓練迴圈的一次迭代中每個裝置使用的訓練樣本數)增加到 GPU 上不會發生記憶體不足 (OOM) 錯誤的最大量。增加批次大小會影響模型的準確度,因此請務必透過調整超參數來縮放模型,以達到目標準確度。
在生產程式碼中停用張量配置期間回報 OOM 錯誤。在
tf.compat.v1.RunOptions中設定report_tensor_allocations_upon_oom=False。對於具有卷積層的模型,如果使用批次正規化,請移除偏差加法。批次正規化會依其平均值移動值,這消除了具有常數偏差項的需要。
使用 TF Stats 找出裝置上運算的執行效率。
使用
tf.function執行計算,並選擇性地啟用jit_compile=True旗標 (tf.function(jit_compile=True)。若要瞭解更多資訊,請前往「Use XLA tf.function」。盡量減少步驟之間的主機 Python 運算並減少回呼。每隔幾個步驟而非每個步驟計算指標。
保持裝置運算單元忙碌。
並行傳送資料到多個裝置。
考慮使用 16 位元數值表示法,例如
fp16(IEEE 指定的半精度浮點格式)或 Brain 浮點 bfloat16 格式。
其他資源
- 「TensorFlow Profiler: Profile model performance」教學課程,其中包含 Keras 和 TensorBoard,您可以在其中應用本指南中的建議。
- 來自 TensorFlow Dev Summit 2020 的「Performance profiling in TensorFlow 2」演講。
- 來自 TensorFlow Dev Summit 2020 的「TensorFlow Profiler demo」示範。
已知限制
在 TensorFlow 2.2 和 TensorFlow 2.3 上對多個 GPU 進行效能分析
TensorFlow 2.2 和 2.3 僅支援單一主機系統的多個 GPU 效能分析;不支援多主機系統的多個 GPU 效能分析。若要對多 worker GPU 設定檔進行效能分析,必須個別對每個 worker 進行效能分析。從 TensorFlow 2.4 開始,可以使用 tf.profiler.experimental.client.trace API 對多個 worker 進行效能分析。
需要 CUDA® Toolkit 10.2 或更新版本才能對多個 GPU 進行效能分析。由於 TensorFlow 2.2 和 2.3 僅支援 CUDA® Toolkit 版本最高至 10.1,因此您需要建立指向 libcudart.so.10.1 和 libcupti.so.10.1 的符號連結
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1