|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
總覽
GPU 和 TPU 可以大幅縮短執行單一訓練步驟所需的時間。若要達到尖峰效能,需要有效率的輸入管道,以便在目前步驟完成前,為下一個步驟傳送資料。tf.data API 有助於建構彈性且有效率的輸入管道。本文件示範如何使用 tf.data API 來建構高效能的 TensorFlow 輸入管道。
在繼續之前,請查看「建構 TensorFlow 輸入管道」指南,瞭解如何使用 tf.data API。
資源
設定
import tensorflow as tf
import time
2024-07-05 01:29:56.308143: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:479] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-07-05 01:29:56.333878: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:10575] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-07-05 01:29:56.333913: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1442] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
在本指南中,您將反覆查看資料集並測量效能。建立可重現的效能基準可能很困難。影響可重現性的不同因素包括:
- 目前的 CPU 負載
- 網路流量
- 複雜的機制,例如快取
若要取得可重現的基準,您將建構人工範例。
資料集
首先定義一個繼承自 tf.data.Dataset 的類別,名為 ArtificialDataset。這個資料集會:
- 產生
num_samples個樣本 (預設值為 3) - 在第一個項目之前休眠一段時間,以模擬開啟檔案
- 在產生每個項目之前休眠一段時間,以模擬從檔案讀取資料
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
這個資料集類似於 tf.data.Dataset.range 資料集,但在每個樣本的開頭和樣本之間新增了固定的延遲。
訓練迴圈
接下來,編寫一個虛擬訓練迴圈,以測量反覆查看資料集所需的時間。訓練時間為模擬時間。
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
最佳化效能
為了展示如何最佳化效能,您將改善 ArtificialDataset 的效能。
初始方法
從未使用任何技巧的初始管道開始,依原樣反覆查看資料集。
benchmark(ArtificialDataset())
Execution time: 0.2957320680000066 2024-07-05 01:30:00.632263: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:00.774083: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
在幕後,您的執行時間是這樣花費的:

圖表顯示,執行訓練步驟包含:
- 開啟檔案 (如果尚未開啟)
- 從檔案擷取資料項目
- 使用資料進行訓練
不過,在像這裡一樣的初始同步實作中,當您的管道正在擷取資料時,您的模型會閒置。反之亦然,當您的模型正在訓練時,輸入管道會閒置。因此,訓練步驟時間是開啟、讀取和訓練時間的總和。
接下來的章節將以此輸入管道為基礎,說明設計高效能 TensorFlow 輸入管道的最佳做法。
預先擷取
預先擷取會重疊訓練步驟的預處理和模型執行。當模型執行訓練步驟 s 時,輸入管道會讀取步驟 s+1 的資料。這樣做可將步驟時間縮短為訓練時間與擷取資料所需時間的最大值 (而非總和)。
tf.data API 提供 tf.data.Dataset.prefetch 轉換。這可用於將資料產生時間與資料耗用時間分離。特別是,此轉換會使用背景執行緒和內部緩衝區,在要求輸入資料集中的元素之前預先擷取這些元素。要預先擷取的元素數量應等於 (或可能大於) 單一訓練步驟耗用的批次數量。您可以手動調整此值,或將其設為 tf.data.AUTOTUNE,這會提示 tf.data 執行階段在執行階段動態調整值。
請注意,每當有機會將「生產者」的工作與「消費者」的工作重疊時,預先擷取轉換都會帶來好處。
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.28615551899997627 2024-07-05 01:30:00.955879: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:01.096260: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

現在,如同資料執行時間圖所示,當樣本 0 正在執行訓練步驟時,輸入管道正在讀取樣本 1 的資料,依此類推。
平行化資料擷取
在真實世界設定中,輸入資料可能會遠端儲存 (例如在 Google Cloud Storage 或 HDFS 上)。當在本機讀取資料時運作良好的資料集管道,在遠端讀取資料時可能會因 I/O 而成為瓶頸,原因如下:本機和遠端儲存空間之間的差異
- 首位元組時間:從遠端儲存空間讀取檔案的第一個位元組,所花費的時間可能比從本機儲存空間讀取檔案的第一個位元組長好幾個數量級。
- 讀取輸送量:雖然遠端儲存空間通常提供很大的總頻寬,但讀取單一檔案可能只能利用此頻寬的一小部分。
此外,將原始位元組載入記憶體後,可能也需要還原序列化和/或解密資料 (例如 protobuf),這需要額外的運算。無論資料是本機儲存還是遠端儲存,這種額外負擔都存在,但如果資料未有效預先擷取,則在遠端案例中可能會更糟。
為了減輕各種資料擷取額外負擔的影響,可以使用 tf.data.Dataset.interleave 轉換來平行化資料載入步驟,交錯其他資料集 (例如資料檔案讀取器) 的內容。cycle_length 引數可以指定要重疊的資料集數量,而 num_parallel_calls 引數可以指定平行處理層級。與 prefetch 轉換類似,interleave 轉換支援 tf.data.AUTOTUNE,這會將要使用的平行處理層級的決策委派給 tf.data 執行階段。
循序交錯
tf.data.Dataset.interleave 轉換的預設引數使其循序交錯來自兩個資料集的單一範例。
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
2024-07-05 01:30:01.387067: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence Execution time: 0.4829045789999782 2024-07-05 01:30:01.625100: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

此資料執行時間圖允許展示 interleave 轉換的行為,從兩個可用的資料集交替擷取範例。不過,這裡不涉及效能改善。
平行交錯
現在,使用 interleave 轉換的 num_parallel_calls 引數。這會平行載入多個資料集,從而減少等待檔案開啟的時間。
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.3866158929999983 2024-07-05 01:30:01.865332: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:02.053387: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

這次,如同資料執行時間圖所示,兩個資料集的讀取已平行化,從而減少了全域資料處理時間。
平行化資料轉換
準備資料時,可能需要預先處理輸入元素。為此,tf.data API 提供 tf.data.Dataset.map 轉換,這會將使用者定義的函式套用至輸入資料集的每個元素。由於輸入元素彼此獨立,因此預先處理可以在多個 CPU 核心之間平行化。為了實現這一點,與 prefetch 和 interleave 轉換類似,map 轉換提供 num_parallel_calls 引數以指定平行處理層級。
為 num_parallel_calls 引數選擇最佳值取決於您的硬體、訓練資料的特性 (例如其大小和形狀)、對應函式的成本,以及同時在 CPU 上發生的其他處理。一個簡單的啟發法是使用可用的 CPU 核心數。不過,如同 prefetch 和 interleave 轉換一樣,map 轉換支援 tf.data.AUTOTUNE,這會將要使用的平行處理層級的決策委派給 tf.data 執行階段。
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
循序對應
首先使用不含平行處理的 map 轉換作為基準範例。
benchmark(
ArtificialDataset()
.map(mapped_function)
)
2024-07-05 01:30:02.372077: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence Execution time: 0.4950294169998415 2024-07-05 01:30:02.616726: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

如同初始方法,在這裡,如同圖表所示,開啟、讀取、預先處理 (對應) 和訓練步驟所花費的時間會加總為單一迭代。
平行對應
現在,使用相同的預先處理函式,但在多個樣本上平行套用。
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.3728290660001221 2024-07-05 01:30:02.841096: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.024465: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

如同資料圖所示,預先處理步驟會重疊,從而減少單一迭代的總時間。
快取
tf.data.Dataset.cache 轉換可以快取資料集,無論是在記憶體中還是本機儲存空間中。這將節省在每個週期執行的一些運算 (例如檔案開啟和資料讀取)。
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3902423539998381 2024-07-05 01:30:03.314025: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.348975: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.383824: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.418575: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.453486: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

在這裡,資料執行時間圖顯示,當您快取資料集時,cache 轉換之前的轉換 (例如檔案開啟和資料讀取) 只會在第一個週期執行。下一個週期將重複使用 cache 轉換快取的資料。
如果傳遞至 map 轉換的使用者定義函式成本很高,只要產生的資料集仍可放入記憶體或本機儲存空間,請在 map 轉換之後套用 cache 轉換。如果使用者定義函式增加儲存資料集所需的空間超出快取容量,請在 cache 轉換之後套用它,或在訓練工作之前考慮預先處理資料,以減少資源用量。
向量化對應
叫用傳遞至 map 轉換的使用者定義函式,會產生與排程和執行使用者定義函式相關的額外負擔。向量化使用者定義的函式 (也就是說,讓它一次對一批輸入執行運算),並在 map 轉換之前套用 batch 轉換。
為了說明這種良好做法,您的人工資料集不適合。排程延遲約為 10 微秒 (10e-6 秒),遠小於 ArtificialDataset 中使用的數十毫秒,因此其影響很難看出。
對於這個範例,請使用基本 tf.data.Dataset.range 函式,並將訓練迴圈簡化為最簡單的形式。
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
純量對應
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.25260185999991336 2024-07-05 01:30:03.610517: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.744984: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.747348: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

上面的圖表說明了使用純量對應方法 (樣本較少) 發生的情況。它顯示對應的函式會針對每個樣本套用。雖然此函式速度很快,但它有一些影響時間效能的額外負擔。
向量化對應
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
2024-07-05 01:30:03.794190: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence Execution time: 0.05108185200015214 2024-07-05 01:30:03.815283: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:03.817405: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

這次,對應的函式會呼叫一次,並套用至一批樣本。如同資料執行時間圖所示,雖然函式可能需要更多時間才能執行,但額外負擔只會出現一次,從而改善整體時間效能。
減少記憶體用量
許多轉換 (包括 interleave、prefetch 和 shuffle) 都會維護元素的內部緩衝區。如果傳遞至 map 轉換的使用者定義函式變更了元素的大小,則對應轉換和緩衝元素轉換的排序會影響記憶體用量。一般而言,請選擇產生較低記憶體用量的順序,除非不同的排序對於效能而言是理想的。
快取部分運算
建議在 map 轉換之後快取資料集,除非此轉換使資料過大而無法放入記憶體。如果您的對應函式可以分成兩部分:耗時的部分和耗用記憶體的部分,則可以實現權衡。在這種情況下,您可以像下面這樣鏈結轉換:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
這樣一來,耗時的部分只會在第一個週期執行,並且您可以避免使用過多的快取空間。
最佳做法摘要
以下是設計高效能 TensorFlow 輸入管道的最佳做法摘要:
- 使用
prefetch轉換來重疊生產者和消費者的工作 - 使用
interleave轉換平行化資料讀取轉換 - 透過設定
num_parallel_calls引數平行化map轉換 - 使用
cache轉換在第一個週期期間快取記憶體中的資料 - 向量化傳遞至
map轉換的使用者定義函式 - 在使用
interleave、prefetch和shuffle轉換時減少記憶體用量
重現圖表
若要深入瞭解 tf.data.Dataset API,您可以試用自己的管道。以下是從本指南繪製圖片所用的程式碼。它可以作為一個良好的起點,展示一些針對常見難題的解決方案,例如:
- 執行時間可重現性
- 對應函式急切執行
interleave轉換可呼叫
import itertools
from collections import defaultdict
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
資料集
與 ArtificialDataset 類似,您可以建構一個資料集,傳回每個步驟中花費的時間。
class TimeMeasuredDataset(tf.data.Dataset):
# OUTPUT: (steps, timings, counters)
OUTPUT_TYPES = (tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32)
OUTPUT_SHAPES = ((2, 1), (2, 2), (2, 3))
_INSTANCES_COUNTER = itertools.count() # Number of datasets generated
_EPOCHS_COUNTER = defaultdict(itertools.count) # Number of epochs done for each dataset
def _generator(instance_idx, num_samples):
epoch_idx = next(TimeMeasuredDataset._EPOCHS_COUNTER[instance_idx])
# Opening the file
open_enter = time.perf_counter()
time.sleep(0.03)
open_elapsed = time.perf_counter() - open_enter
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
read_enter = time.perf_counter()
time.sleep(0.015)
read_elapsed = time.perf_counter() - read_enter
yield (
[("Open",), ("Read",)],
[(open_enter, open_elapsed), (read_enter, read_elapsed)],
[(instance_idx, epoch_idx, -1), (instance_idx, epoch_idx, sample_idx)]
)
open_enter, open_elapsed = -1., -1. # Negative values will be filtered
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.OUTPUT_TYPES,
output_shapes=cls.OUTPUT_SHAPES,
args=(next(cls._INSTANCES_COUNTER), num_samples)
)
此資料集提供形狀為 [[2, 1], [2, 2], [2, 3]] 和類型為 [tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32] 的樣本。每個樣本是:
(
[("Open"), ("Read")],
[(t0, d), (t0, d)],
[(i, e, -1), (i, e, s)]
)
其中:
Open和Read是步驟識別碼t0是對應步驟開始時的時間戳記d是對應步驟中花費的時間i是執行個體索引e是週期索引 (資料集反覆查看的次數)s是樣本索引
迭代迴圈
使迭代迴圈稍微複雜一些,以彙總所有計時。這僅適用於產生如上詳述之樣本的資料集。
def timelined_benchmark(dataset, num_epochs=2):
# Initialize accumulators
steps_acc = tf.zeros([0, 1], dtype=tf.dtypes.string)
times_acc = tf.zeros([0, 2], dtype=tf.dtypes.float32)
values_acc = tf.zeros([0, 3], dtype=tf.dtypes.int32)
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
epoch_enter = time.perf_counter()
for (steps, times, values) in dataset:
# Record dataset preparation informations
steps_acc = tf.concat((steps_acc, steps), axis=0)
times_acc = tf.concat((times_acc, times), axis=0)
values_acc = tf.concat((values_acc, values), axis=0)
# Simulate training time
train_enter = time.perf_counter()
time.sleep(0.01)
train_elapsed = time.perf_counter() - train_enter
# Record training informations
steps_acc = tf.concat((steps_acc, [["Train"]]), axis=0)
times_acc = tf.concat((times_acc, [(train_enter, train_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [values[-1]]), axis=0)
epoch_elapsed = time.perf_counter() - epoch_enter
# Record epoch informations
steps_acc = tf.concat((steps_acc, [["Epoch"]]), axis=0)
times_acc = tf.concat((times_acc, [(epoch_enter, epoch_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [[-1, epoch_num, -1]]), axis=0)
time.sleep(0.001)
tf.print("Execution time:", time.perf_counter() - start_time)
return {"steps": steps_acc, "times": times_acc, "values": values_acc}
繪圖方法
最後,定義一個函式,能夠根據 timelined_benchmark 函式傳回的值繪製時間軸。
def draw_timeline(timeline, title, width=0.5, annotate=False, save=False):
# Remove invalid entries (negative times, or empty steps) from the timelines
invalid_mask = np.logical_and(timeline['times'] > 0, timeline['steps'] != b'')[:,0]
steps = timeline['steps'][invalid_mask].numpy()
times = timeline['times'][invalid_mask].numpy()
values = timeline['values'][invalid_mask].numpy()
# Get a set of different steps, ordered by the first time they are encountered
step_ids, indices = np.stack(np.unique(steps, return_index=True))
step_ids = step_ids[np.argsort(indices)]
# Shift the starting time to 0 and compute the maximal time value
min_time = times[:,0].min()
times[:,0] = (times[:,0] - min_time)
end = max(width, (times[:,0]+times[:,1]).max() + 0.01)
cmap = mpl.cm.get_cmap("plasma")
plt.close()
fig, axs = plt.subplots(len(step_ids), sharex=True, gridspec_kw={'hspace': 0})
fig.suptitle(title)
fig.set_size_inches(17.0, len(step_ids))
plt.xlim(-0.01, end)
for i, step in enumerate(step_ids):
step_name = step.decode()
ax = axs[i]
ax.set_ylabel(step_name)
ax.set_ylim(0, 1)
ax.set_yticks([])
ax.set_xlabel("time (s)")
ax.set_xticklabels([])
ax.grid(which="both", axis="x", color="k", linestyle=":")
# Get timings and annotation for the given step
entries_mask = np.squeeze(steps==step)
serie = np.unique(times[entries_mask], axis=0)
annotations = values[entries_mask]
ax.broken_barh(serie, (0, 1), color=cmap(i / len(step_ids)), linewidth=1, alpha=0.66)
if annotate:
for j, (start, width) in enumerate(serie):
annotation = "\n".join([f"{l}: {v}" for l,v in zip(("i", "e", "s"), annotations[j])])
ax.text(start + 0.001 + (0.001 * (j % 2)), 0.55 - (0.1 * (j % 2)), annotation,
horizontalalignment='left', verticalalignment='center')
if save:
plt.savefig(title.lower().translate(str.maketrans(" ", "_")) + ".svg")
對應函式使用包裝函式
若要在急切環境中執行對應函式,您必須將它們包裝在 tf.py_function 呼叫中。
def map_decorator(func):
def wrapper(steps, times, values):
# Use a tf.py_function to prevent auto-graph from compiling the method
return tf.py_function(
func,
inp=(steps, times, values),
Tout=(steps.dtype, times.dtype, values.dtype)
)
return wrapper
管道比較
_batch_map_num_items = 50
def dataset_generator_fun(*args):
return TimeMeasuredDataset(num_samples=_batch_map_num_items)
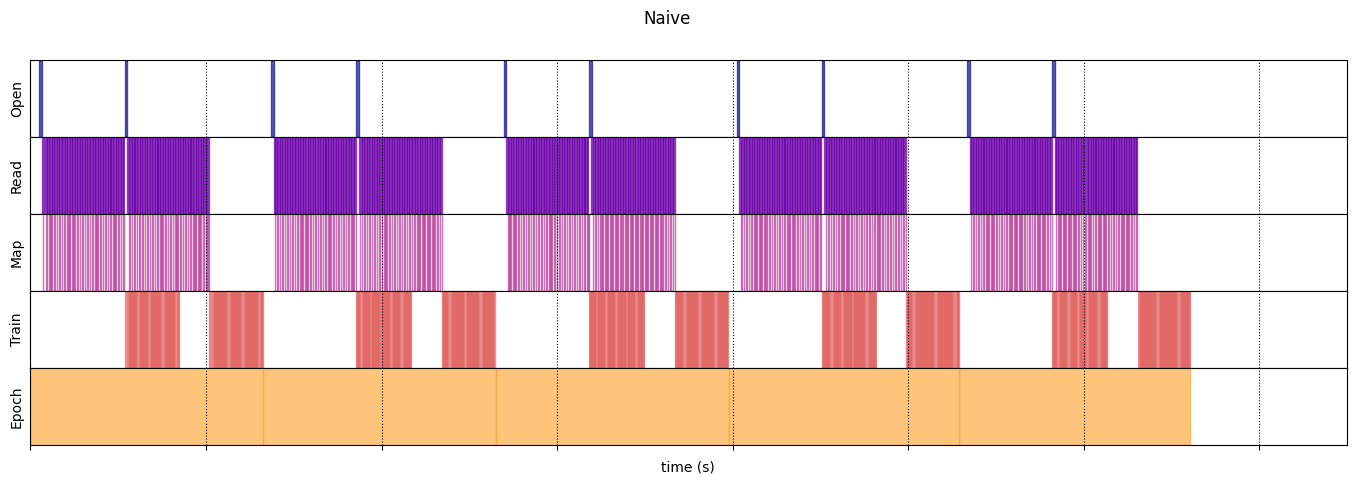
初始
@map_decorator
def naive_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001) # Time consuming step
time.sleep(0.0001) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, [["Map"]]), axis=0),
tf.concat((times, [[map_enter, map_elapsed]]), axis=0),
tf.concat((values, [values[-1]]), axis=0)
)
naive_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.flat_map(dataset_generator_fun)
.map(naive_map)
.batch(_batch_map_num_items, drop_remainder=True)
.unbatch(),
5
)
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_18520/64197174.py:32: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_types is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead WARNING:tensorflow:From /tmpfs/tmp/ipykernel_18520/64197174.py:32: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_shapes is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead 2024-07-05 01:30:06.899542: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:09.551322: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:12.203750: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:14.829173: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence Execution time: 13.217723363000005 2024-07-05 01:30:17.465496: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
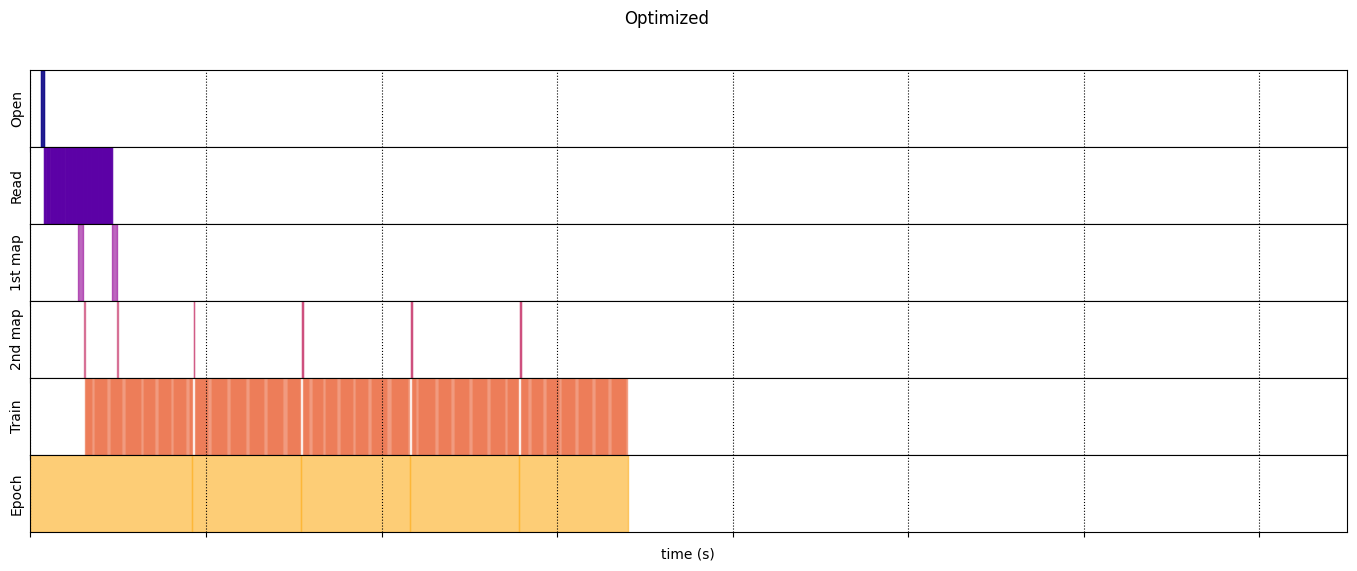
已最佳化
@map_decorator
def time_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001 * values.shape[0]) # Time consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, tf.tile([[["1st map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
@map_decorator
def memory_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.0001 * values.shape[0]) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
# Use tf.tile to handle batch dimension
return (
tf.concat((steps, tf.tile([[["2nd map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
optimized_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.interleave( # Parallelize data reading
dataset_generator_fun,
num_parallel_calls=tf.data.AUTOTUNE
)
.batch( # Vectorize your mapped function
_batch_map_num_items,
drop_remainder=True)
.map( # Parallelize map transformation
time_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.cache() # Cache data
.map( # Reduce memory usage
memory_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.prefetch( # Overlap producer and consumer works
tf.data.AUTOTUNE
)
.unbatch(),
5
)
2024-07-05 01:30:19.383587: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:20.620389: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:21.864781: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence 2024-07-05 01:30:23.104293: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence Execution time: 6.807020873000056 2024-07-05 01:30:24.348445: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
draw_timeline(naive_timeline, "Naive", 15)
/tmpfs/tmp/ipykernel_18520/2966908191.py:17: MatplotlibDeprecationWarning: The get_cmap function was deprecated in Matplotlib 3.7 and will be removed in 3.11. Use ``matplotlib.colormaps[name]`` or ``matplotlib.colormaps.get_cmap()`` or ``pyplot.get_cmap()`` instead.
cmap = mpl.cm.get_cmap("plasma")
draw_timeline(optimized_timeline, "Optimized", 15)
/tmpfs/tmp/ipykernel_18520/2966908191.py:17: MatplotlibDeprecationWarning: The get_cmap function was deprecated in Matplotlib 3.7 and will be removed in 3.11. Use ``matplotlib.colormaps[name]`` or ``matplotlib.colormaps.get_cmap()`` or ``pyplot.get_cmap()`` instead.
cmap = mpl.cm.get_cmap("plasma")