
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
學習目標
在本 Colab 筆記本中,您將學習如何使用 NLP 模型程式庫中的建構區塊,為常見的 NLP 任務 (包括預先訓練、跨度標記和分類) 建構以 Transformer 為基礎的模型。
安裝與匯入
安裝 TensorFlow Model Garden pip 套件
tf-models-official是穩定的 Model Garden 套件。請注意,它可能未包含tensorflow_modelsgithub repo 中的最新變更。若要包含最新變更,您可以安裝tf-models-nightly,這是每日自動建立的 Model Garden 每夜版套件。pip將自動安裝所有模型和依附元件。
pip install tf-models-official
匯入 Tensorflow 和其他程式庫
import numpy as np
import tensorflow as tf
from tensorflow_models import nlp
2023-10-17 12:23:04.557393: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-10-17 12:23:04.557445: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-10-17 12:23:04.557482: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
BERT 預先訓練模型
BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding) 介紹了在大型文字語料庫上預先訓練語言表示,然後將該模型用於下游 NLP 任務的方法。
在本節中,我們將學習如何建構模型,以針對遮罩語言模型任務和下一句預測任務預先訓練 BERT。為簡化起見,我們僅顯示最小範例並使用虛擬資料。
建構包裝 BertEncoder 的 BertPretrainer 模型
nlp.networks.BertEncoder 類別實作以 Transformer 為基礎的編碼器,如 BERT 論文中所述。它包含嵌入查詢和 Transformer 層 (nlp.layers.TransformerEncoderBlock),但不包含遮罩語言模型或分類任務網路。
nlp.models.BertPretrainer 類別允許使用者傳入 Transformer 堆疊,並實例化用於建立訓練目標的遮罩語言模型和分類網路。
# Build a small transformer network.
vocab_size = 100
network = nlp.networks.BertEncoder(
vocab_size=vocab_size,
# The number of TransformerEncoderBlock layers
num_layers=3)
2023-10-17 12:23:09.241708: W tensorflow/core/common_runtime/gpu/gpu_device.cc:2211] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://tensorflow.dev.org.tw/install/gpu for how to download and setup the required libraries for your platform. Skipping registering GPU devices...
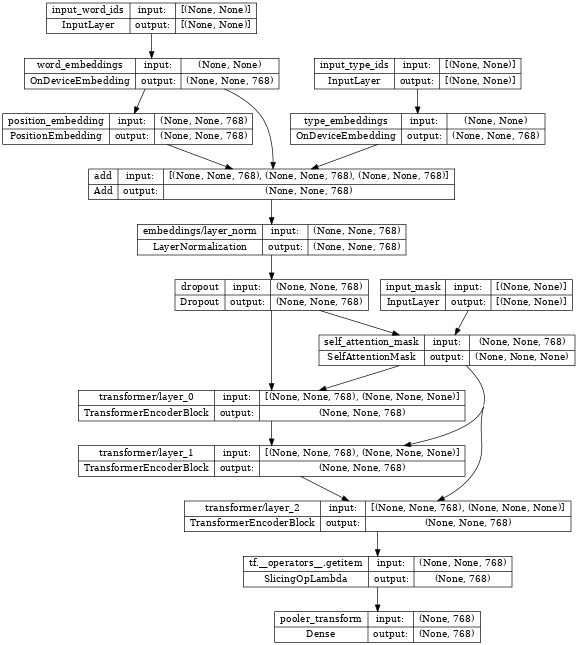
檢查編碼器,我們看到它包含一些嵌入層、堆疊的 nlp.layers.TransformerEncoderBlock 層,並連接到三個輸入層
input_word_ids、input_type_ids 和 input_mask。
tf.keras.utils.plot_model(network, show_shapes=True, expand_nested=True, dpi=48)
# Create a BERT pretrainer with the created network.
num_token_predictions = 8
bert_pretrainer = nlp.models.BertPretrainer(
network, num_classes=2, num_token_predictions=num_token_predictions, output='predictions')
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/official/nlp/modeling/models/bert_pretrainer.py:112: Classification.__init__ (from official.nlp.modeling.networks.classification) is deprecated and will be removed in a future version. Instructions for updating: Classification as a network is deprecated. Please use the layers.ClassificationHead instead.
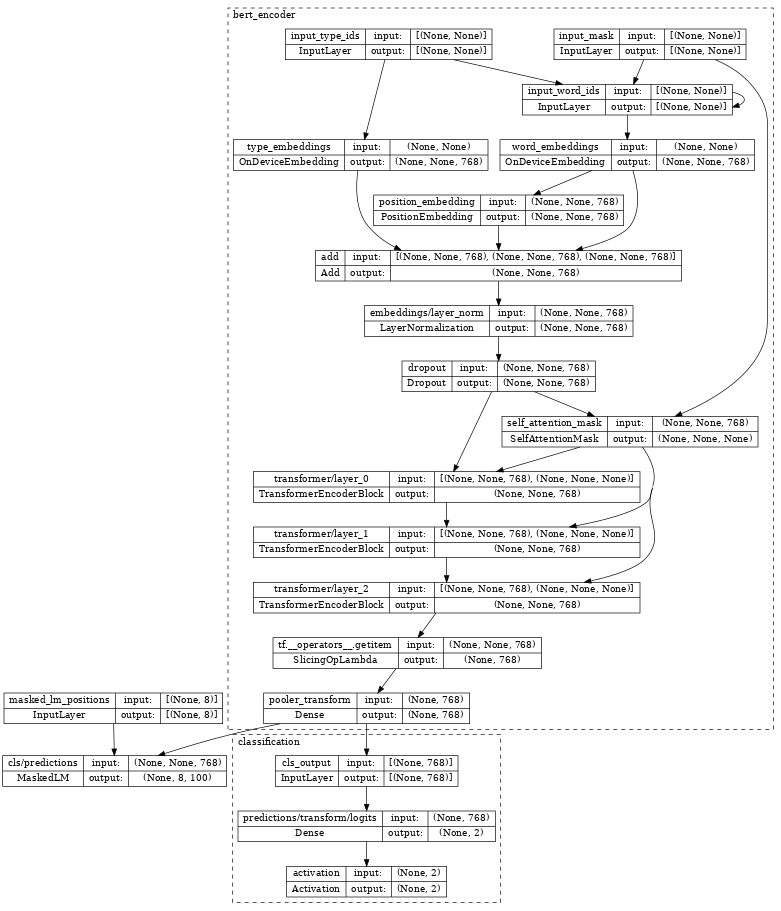
檢查 bert_pretrainer,我們看到它使用額外的 MaskedLM 和 nlp.layers.ClassificationHead 標頭包裝 encoder。
tf.keras.utils.plot_model(bert_pretrainer, show_shapes=True, expand_nested=True, dpi=48)
# We can feed some dummy data to get masked language model and sentence output.
sequence_length = 16
batch_size = 2
word_id_data = np.random.randint(vocab_size, size=(batch_size, sequence_length))
mask_data = np.random.randint(2, size=(batch_size, sequence_length))
type_id_data = np.random.randint(2, size=(batch_size, sequence_length))
masked_lm_positions_data = np.random.randint(2, size=(batch_size, num_token_predictions))
outputs = bert_pretrainer(
[word_id_data, mask_data, type_id_data, masked_lm_positions_data])
lm_output = outputs["masked_lm"]
sentence_output = outputs["classification"]
print(f'lm_output: shape={lm_output.shape}, dtype={lm_output.dtype!r}')
print(f'sentence_output: shape={sentence_output.shape}, dtype={sentence_output.dtype!r}')
lm_output: shape=(2, 8, 100), dtype=tf.float32 sentence_output: shape=(2, 2), dtype=tf.float32
計算損失
接下來,我們可以使用 lm_output 和 sentence_output 來計算 loss。
masked_lm_ids_data = np.random.randint(vocab_size, size=(batch_size, num_token_predictions))
masked_lm_weights_data = np.random.randint(2, size=(batch_size, num_token_predictions))
next_sentence_labels_data = np.random.randint(2, size=(batch_size))
mlm_loss = nlp.losses.weighted_sparse_categorical_crossentropy_loss(
labels=masked_lm_ids_data,
predictions=lm_output,
weights=masked_lm_weights_data)
sentence_loss = nlp.losses.weighted_sparse_categorical_crossentropy_loss(
labels=next_sentence_labels_data,
predictions=sentence_output)
loss = mlm_loss + sentence_loss
print(loss)
tf.Tensor(5.2983174, shape=(), dtype=float32)
有了損失,您就可以最佳化模型。訓練後,我們可以儲存 TransformerEncoder 的權重,以用於下游微調任務。如需完整範例,請參閱 run_pretraining.py。
跨度標記模型
跨度標記是將標籤指派給文字跨度的任務,例如,將文字跨度標記為指定問題的答案。
在本節中,我們將學習如何建構跨度標記模型。同樣地,為簡化起見,我們使用虛擬資料。
建構包裝 BertEncoder 的 BertSpanLabeler
nlp.models.BertSpanLabeler 類別實作簡單的單跨度起點-終點預測器 (也就是預測兩個值的模型:起點權杖索引和終點權杖索引),適用於 SQuAD 樣式的任務。
請注意,nlp.models.BertSpanLabeler 包裝了 nlp.networks.BertEncoder,其權重可以從上述預先訓練模型還原。
network = nlp.networks.BertEncoder(
vocab_size=vocab_size, num_layers=2)
# Create a BERT trainer with the created network.
bert_span_labeler = nlp.models.BertSpanLabeler(network)
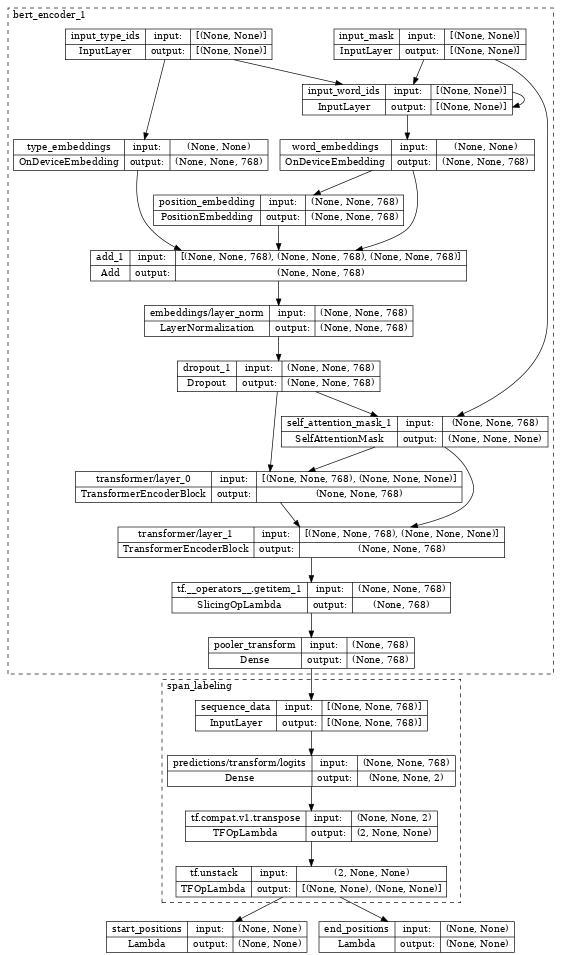
檢查 bert_span_labeler,我們看到它使用額外的 SpanLabeling 包裝編碼器,該 SpanLabeling 輸出 start_position 和 end_position。
tf.keras.utils.plot_model(bert_span_labeler, show_shapes=True, expand_nested=True, dpi=48)
# Create a set of 2-dimensional data tensors to feed into the model.
word_id_data = np.random.randint(vocab_size, size=(batch_size, sequence_length))
mask_data = np.random.randint(2, size=(batch_size, sequence_length))
type_id_data = np.random.randint(2, size=(batch_size, sequence_length))
# Feed the data to the model.
start_logits, end_logits = bert_span_labeler([word_id_data, mask_data, type_id_data])
print(f'start_logits: shape={start_logits.shape}, dtype={start_logits.dtype!r}')
print(f'end_logits: shape={end_logits.shape}, dtype={end_logits.dtype!r}')
start_logits: shape=(2, 16), dtype=tf.float32 end_logits: shape=(2, 16), dtype=tf.float32
計算損失
有了 start_logits 和 end_logits,我們就可以計算損失
start_positions = np.random.randint(sequence_length, size=(batch_size))
end_positions = np.random.randint(sequence_length, size=(batch_size))
start_loss = tf.keras.losses.sparse_categorical_crossentropy(
start_positions, start_logits, from_logits=True)
end_loss = tf.keras.losses.sparse_categorical_crossentropy(
end_positions, end_logits, from_logits=True)
total_loss = (tf.reduce_mean(start_loss) + tf.reduce_mean(end_loss)) / 2
print(total_loss)
tf.Tensor(5.3621416, shape=(), dtype=float32)
有了 loss,您就可以最佳化模型。如需完整範例,請參閱 run_squad.py。
分類模型
在最後一節中,我們將展示如何建構文字分類模型。
建構包裝 BertEncoder 的 BertClassifier 模型
nlp.models.BertClassifier 實作包含單一分類標頭的 [CLS] 權杖分類模型。
network = nlp.networks.BertEncoder(
vocab_size=vocab_size, num_layers=2)
# Create a BERT trainer with the created network.
num_classes = 2
bert_classifier = nlp.models.BertClassifier(
network, num_classes=num_classes)
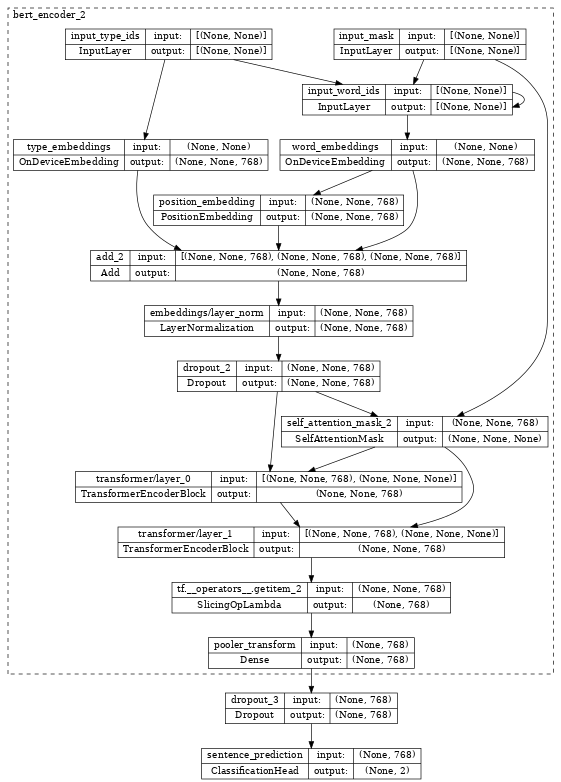
檢查 bert_classifier,我們看到它使用額外的 Classification 標頭包裝 encoder。
tf.keras.utils.plot_model(bert_classifier, show_shapes=True, expand_nested=True, dpi=48)
# Create a set of 2-dimensional data tensors to feed into the model.
word_id_data = np.random.randint(vocab_size, size=(batch_size, sequence_length))
mask_data = np.random.randint(2, size=(batch_size, sequence_length))
type_id_data = np.random.randint(2, size=(batch_size, sequence_length))
# Feed the data to the model.
logits = bert_classifier([word_id_data, mask_data, type_id_data])
print(f'logits: shape={logits.shape}, dtype={logits.dtype!r}')
logits: shape=(2, 2), dtype=tf.float32
計算損失
有了 logits,我們就可以計算 loss
labels = np.random.randint(num_classes, size=(batch_size))
loss = tf.keras.losses.sparse_categorical_crossentropy(
labels, logits, from_logits=True)
print(loss)
tf.Tensor([0.7332015 1.3447659], shape=(2,), dtype=float32)
有了 loss,您就可以最佳化模型。如需完整範例,請參閱 Fine tune_bert 筆記本或模型訓練文件。