
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
在本教學課程中,您將學習如何透過使用預先訓練網路的遷移學習,對貓狗圖片進行分類。
預先訓練模型是已儲存的網路,先前已在大型資料集上訓練過,通常是在大規模圖片分類工作上訓練。您可以按原樣使用預先訓練模型,或使用遷移學習針對特定工作自訂此模型。
圖片分類遷移學習背後的直覺是,如果模型在夠大型且夠通用的資料集上訓練,則此模型將有效地充當視覺世界的通用模型。然後,您可以利用這些已學習的功能圖,而不必從頭開始,在大型資料集上訓練大型模型。
在本筆記本中,您將嘗試兩種自訂預先訓練模型的方法
特徵擷取:使用先前網路學習到的表示法,從新樣本中擷取有意義的特徵。您只需在預先訓練模型之上新增一個新的分類器 (將從頭開始訓練),以便您可以將先前針對資料集學習到的功能圖重新用於其他用途。
您不需要 (重新) 訓練整個模型。基礎卷積網路已包含在圖片分類方面通用的特徵。但是,預先訓練模型的最終分類部分特定於原始分類工作,隨後也特定於模型訓練的類別集。
微調:解除凍結凍結模型基礎的幾個頂層,並共同訓練新新增的分類器層和基礎模型的最後幾層。這讓我們可以「微調」基礎模型中的高階特徵表示法,使其更適用於特定工作。
您將遵循一般機器學習工作流程。
- 檢查並理解資料
- 建構輸入管線,在本例中是使用 Keras ImageDataGenerator
- 組合模型
- 載入預先訓練基礎模型 (和預先訓練權重)
- 將分類層堆疊在頂端
- 訓練模型
- 評估模型
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
資料預先處理
資料下載
在本教學課程中,您將使用包含數千張貓狗圖片的資料集。下載並解壓縮包含圖片的 zip 檔案,然後使用 tf.keras.utils.image_dataset_from_directory 公用程式,為訓練和驗證建立 tf.data.Dataset。您可以在此教學課程中進一步瞭解載入圖片。
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68606236/68606236 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
顯示訓練集中的前九張圖片和標籤
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
2024-06-27 01:22:05.112570: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

由於原始資料集不包含測試集,您將建立一個測試集。若要執行此操作,請使用 tf.data.experimental.cardinality 判斷驗證集中可用的資料批次數量,然後將其中的 20% 移至測試集。
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
設定資料集以提升效能
使用緩衝預先擷取從磁碟載入圖片,而不會讓 I/O 變成封鎖。若要進一步瞭解此方法,請參閱資料效能指南。
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
使用資料擴增
當您沒有大型圖片資料集時,良好的做法是透過對訓練圖片套用隨機但真實的轉換 (例如旋轉和水平翻轉),人工地引入樣本多樣性。這有助於讓模型接觸訓練資料的不同面向,並減少過度擬合。您可以在此教學課程中進一步瞭解資料擴增。
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
讓我們對同一張圖片重複套用這些層,並查看結果。
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')
2024-06-27 01:22:06.987241: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

重新調整像素值
稍後,您將下載 tf.keras.applications.MobileNetV2 以用作基礎模型。此模型預期像素值在 [-1, 1] 範圍內,但在此時,圖片中的像素值在 [0, 255] 範圍內。若要重新調整這些值,請使用模型隨附的預先處理方法。
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
從預先訓練的 convnet 建立基礎模型
您將從 Google 開發的 MobileNet V2 模型建立基礎模型。此模型已在 ImageNet 資料集上預先訓練,ImageNet 資料集是包含 140 萬張圖片和 1000 個類別的大型資料集。ImageNet 是研究訓練資料集,其中包含各種不同的類別,例如 jackfruit 和 syringe。此知識基礎將協助我們從特定資料集分類貓和狗。
首先,您需要選擇要將 MobileNet V2 的哪個層用於特徵擷取。最上層的最後一個分類層 (在「頂端」,因為大多數機器學習模型的圖表都是從底部到頂部) 不是很有用。相反地,您將遵循慣例,依賴展平運算之前的最後一個層。此層稱為「瓶頸層」。與最終/頂層相比,瓶頸層特徵保留了更多通用性。
首先,例項化預先載入在 ImageNet 上訓練的權重的 MobileNet V2 模型。透過指定 include_top=False 引數,您載入的網路不包含頂端的分類層,這非常適合用於特徵擷取。
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9406464/9406464 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
此特徵擷取器會將每個 160x160x3 圖片轉換為 5x5x1280 特徵區塊。讓我們看看它對範例圖片批次執行了什麼操作
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
特徵擷取
在此步驟中,您將凍結從上一個步驟建立的卷積基礎,並將其用作特徵擷取器。此外,您會在它之上新增分類器,並訓練頂層分類器。
凍結卷積基礎
在編譯和訓練模型之前凍結卷積基礎非常重要。凍結 (透過設定 layer.trainable = False) 可防止在訓練期間更新指定層中的權重。MobileNet V2 有許多層,因此將整個模型的 trainable 旗標設定為 False 將凍結所有層。
base_model.trainable = False
關於 BatchNormalization 層的重要注意事項
許多模型都包含 tf.keras.layers.BatchNormalization 層。此層是特殊情況,在微調的環境中應採取預防措施,如本教學課程稍後所示。
當您設定 layer.trainable = False 時,BatchNormalization 層將在推論模式下執行,且不會更新其平均值和變異數統計資料。
當您解除凍結包含 BatchNormalization 層的模型以進行微調時,您應透過在呼叫基礎模型時傳遞 training = False,讓 BatchNormalization 層保持在推論模式。否則,套用至非可訓練權重的更新將會破壞模型已學習到的內容。
如需更多詳細資訊,請參閱遷移學習指南。
# Let's take a look at the base model architecture
base_model.summary()
新增分類標頭
若要從特徵區塊產生預測,請在空間 5x5 空間位置上取平均值,並使用 tf.keras.layers.GlobalAveragePooling2D 層將特徵轉換為每張圖片的單一 1280 元素向量。
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
套用 tf.keras.layers.Dense 層,將這些特徵轉換為每張圖片的單一預測。您在這裡不需要啟動函式,因為此預測將被視為 logit 或原始預測值。正數預測類別 1,負數預測類別 0。
prediction_layer = tf.keras.layers.Dense(1, activation='sigmoid')
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
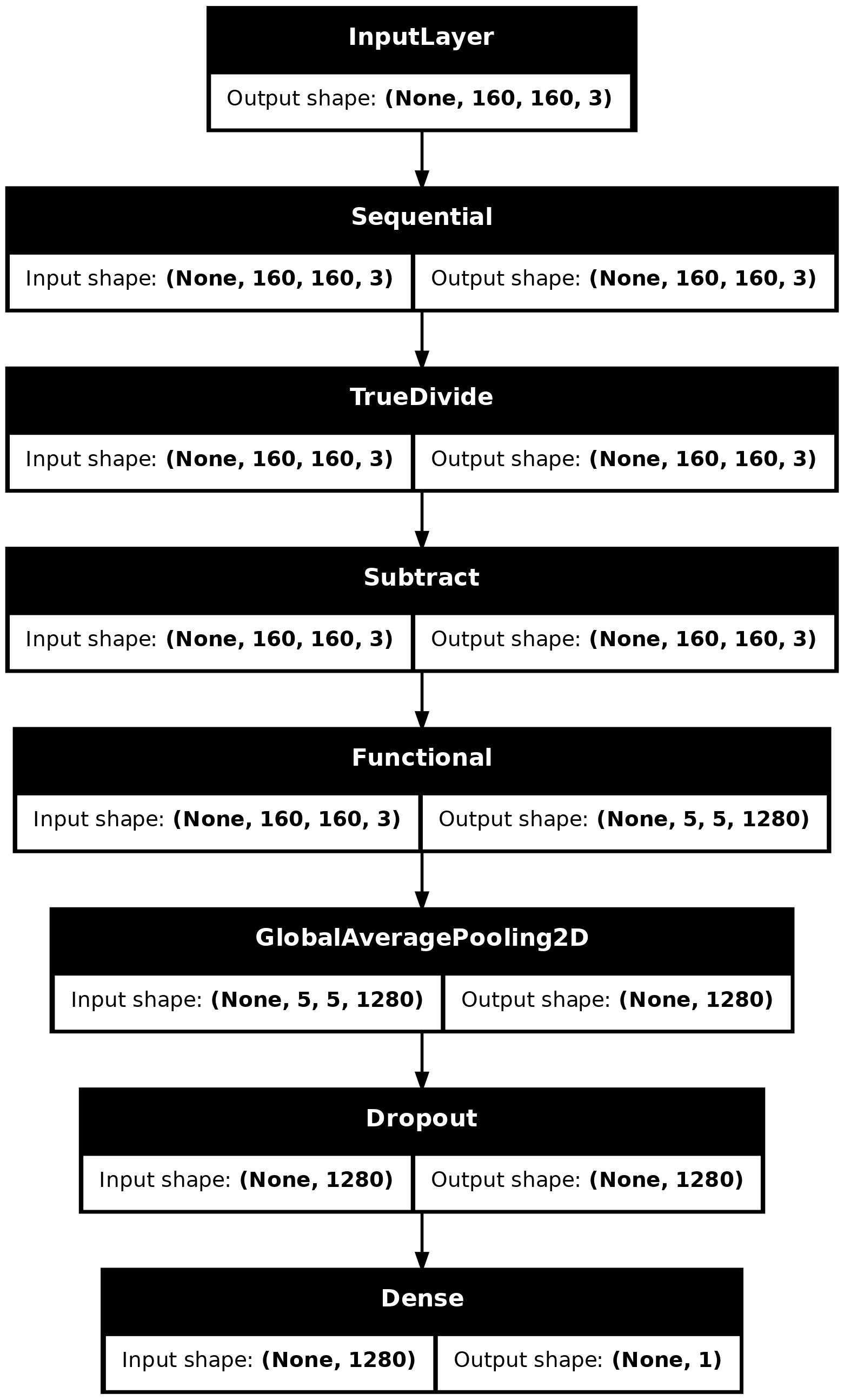
使用 Keras Functional API,透過串連資料擴增、重新調整、base_model 和特徵擷取器層來建構模型。如先前所述,由於我們的模型包含 BatchNormalization 層,因此請使用 training=False。
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
model.summary()
MobileNet 中超過 800 萬個參數已凍結,但 Dense 層中有 1200 個可訓練參數。這些參數在兩個 tf.Variable 物件 (權重和偏差) 之間分配。
len(model.trainable_variables)
2
tf.keras.utils.plot_model(model, show_shapes=True)
編譯模型
在訓練模型之前先編譯模型。由於有兩個類別和 Sigmoid 輸出,因此請使用 BinaryAccuracy。
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])
訓練模型
在訓練 10 個週期後,您應該會在驗證集上看到約 96% 的準確度。
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 ━━━━━━━━━━━━━━━━━━━━ 3s 50ms/step - accuracy: 0.5516 - loss: 0.7358
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.72 initial accuracy: 0.57
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 51ms/step - accuracy: 0.6088 - loss: 0.6782 - val_accuracy: 0.7908 - val_loss: 0.4953 Epoch 2/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.7647 - loss: 0.5053 - val_accuracy: 0.8812 - val_loss: 0.3665 Epoch 3/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8187 - loss: 0.4228 - val_accuracy: 0.9109 - val_loss: 0.2960 Epoch 4/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8556 - loss: 0.3566 - val_accuracy: 0.9344 - val_loss: 0.2435 Epoch 5/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8878 - loss: 0.3080 - val_accuracy: 0.9455 - val_loss: 0.2101 Epoch 6/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8879 - loss: 0.2790 - val_accuracy: 0.9480 - val_loss: 0.1879 Epoch 7/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8970 - loss: 0.2621 - val_accuracy: 0.9554 - val_loss: 0.1616 Epoch 8/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.9082 - loss: 0.2352 - val_accuracy: 0.9641 - val_loss: 0.1485 Epoch 9/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.9162 - loss: 0.2239 - val_accuracy: 0.9678 - val_loss: 0.1360 Epoch 10/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.9204 - loss: 0.2183 - val_accuracy: 0.9728 - val_loss: 0.1245
學習曲線
讓我們看看在使用 MobileNetV2 基礎模型作為固定特徵擷取器時,訓練和驗證準確度/損失的學習曲線。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
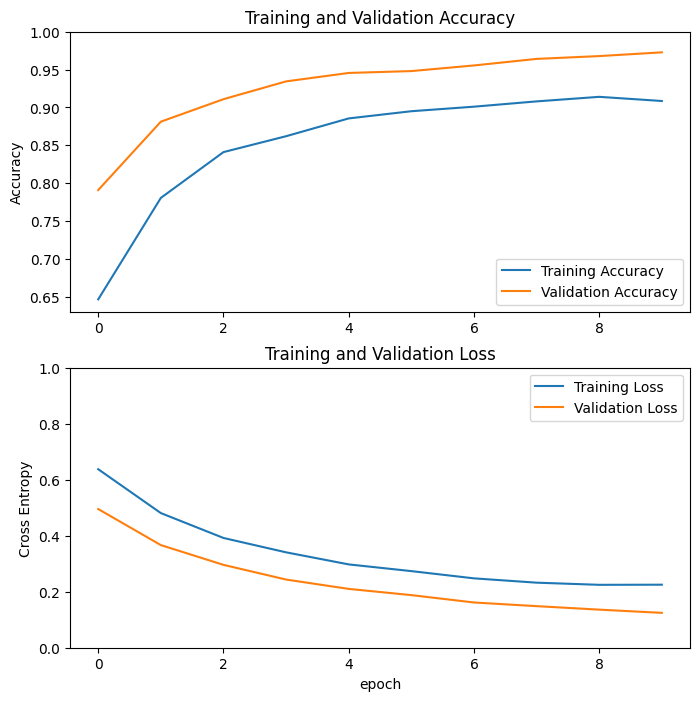
在較小程度上,這也是因為訓練指標會報告一個週期的平均值,而驗證指標會在週期後評估,因此驗證指標會看到訓練時間稍微長一點的模型。
微調
在特徵擷取實驗中,您僅訓練 MobileNetV2 基礎模型頂端的幾個層。預先訓練網路的權重在訓練期間未更新。
進一步提高效能的一種方法是,在訓練您新增的分類器的同時,訓練 (或「微調」) 預先訓練模型頂層的權重。訓練流程將強制權重從通用特徵圖調整為與資料集明確相關聯的特徵。
此外,您應嘗試微調少數頂層,而不是整個 MobileNet 模型。在大多數卷積網路中,層級越高,就越專業。前幾個層學習非常簡單且通用的特徵,這些特徵可推廣到幾乎所有類型的圖片。當您向上移動時,特徵會越來越特定於模型訓練的資料集。微調的目標是調整這些專業特徵以適用於新資料集,而不是覆寫通用學習。
解除凍結模型的頂層
您只需解除凍結 base_model,並將底層設定為非可訓練。然後,您應重新編譯模型 (這些變更生效的必要條件),並繼續訓練。
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
編譯模型
由於您要訓練更大的模型並想要重新調整預先訓練權重,因此在此階段使用較低的學習率非常重要。否則,您的模型可能會很快過度擬合。
model.compile(loss=tf.keras.losses.BinaryCrossentropy(),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])
model.summary()
len(model.trainable_variables)
56
繼續訓練模型
如果您先前已訓練到收斂,則此步驟將使您的準確度提高幾個百分點。
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=len(history.epoch),
validation_data=validation_dataset)
Epoch 11/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 14s 82ms/step - accuracy: 0.7710 - loss: 0.4544 - val_accuracy: 0.9740 - val_loss: 0.0892 Epoch 12/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.8829 - loss: 0.2787 - val_accuracy: 0.9752 - val_loss: 0.0771 Epoch 13/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9097 - loss: 0.2267 - val_accuracy: 0.9802 - val_loss: 0.0603 Epoch 14/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9186 - loss: 0.2091 - val_accuracy: 0.9827 - val_loss: 0.0577 Epoch 15/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9118 - loss: 0.1978 - val_accuracy: 0.9814 - val_loss: 0.0553 Epoch 16/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9382 - loss: 0.1637 - val_accuracy: 0.9839 - val_loss: 0.0507 Epoch 17/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9325 - loss: 0.1515 - val_accuracy: 0.9827 - val_loss: 0.0502 Epoch 18/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9448 - loss: 0.1339 - val_accuracy: 0.9827 - val_loss: 0.0511 Epoch 19/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9534 - loss: 0.1213 - val_accuracy: 0.9827 - val_loss: 0.0470 Epoch 20/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9465 - loss: 0.1408 - val_accuracy: 0.9827 - val_loss: 0.0466
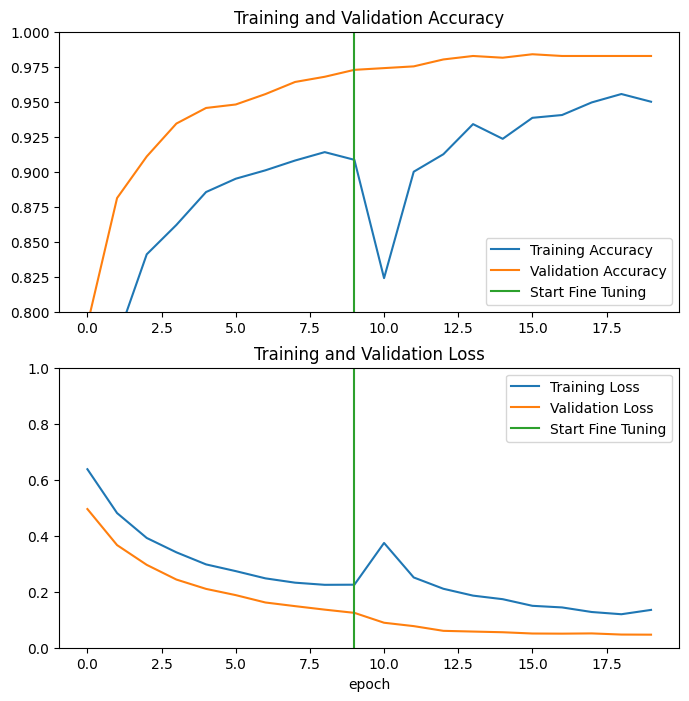
讓我們看看在微調 MobileNetV2 基礎模型的最後幾個層,以及訓練其頂端的分類器時,訓練和驗證準確度/損失的學習曲線。驗證損失遠高於訓練損失,因此您可能會遇到一些過度擬合。
由於新的訓練集相對較小且與原始 MobileNetV2 資料集相似,因此您也可能會遇到一些過度擬合。
微調模型後,準確度幾乎達到驗證集上的 98%。
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
評估與預測
最後,您可以使用測試集驗證模型在新資料上的效能。
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step - accuracy: 0.9893 - loss: 0.0340 Test accuracy : 0.9895833134651184
現在您已準備好使用此模型來預測您的寵物是貓還是狗。
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [1 1 1 1 1 1 1 0 0 1 1 1 0 0 1 0 0 0 0 1 1 1 0 1 1 0 0 1 0 0 0 0] Labels: [1 1 1 1 1 1 1 0 0 1 1 1 0 0 1 0 0 0 0 1 1 1 0 1 1 0 0 1 0 0 0 0]

摘要
使用預先訓練模型進行特徵擷取:當處理小型資料集時,常見的做法是利用在同一網域中較大型資料集上訓練的模型所學習到的特徵。這透過例項化預先訓練模型並在頂端新增完全連線的分類器來完成。預先訓練模型會「凍結」,且只有分類器的權重會在訓練期間更新。在本例中,卷積基礎擷取了與每張圖片相關聯的所有特徵,而您只訓練了一個分類器,該分類器會根據該組擷取的特徵判斷圖片類別。
微調預先訓練模型:若要進一步提高效能,可能需要透過微調將預先訓練模型的頂層重新用於新資料集。在本例中,您調整了權重,使您的模型學習到特定於資料集的高階特徵。當訓練資料集很大且與預先訓練模型訓練的原始資料集非常相似時,通常建議使用此技術。
若要瞭解詳情,請造訪遷移學習指南。
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.