
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
本教學示範如何使用 TensorFlow 實作 Actor-Critic 方法,以在 Open AI Gym CartPole-v0 環境中訓練代理程式。讀者應對 (深度) 強化學習的策略梯度方法有所熟悉。
Actor-Critic 方法
Actor-Critic 方法是時間差分 (TD) 學習方法,其策略函數的表示方式獨立於價值函數。
策略函數(或策略)會根據給定的狀態,傳回代理程式可以採取的動作的機率分佈。價值函數會決定代理程式從給定狀態開始,並在之後永遠根據特定策略行動的預期報酬。
在 Actor-Critic 方法中,策略稱為「演員」(actor),其會根據給定的狀態提出一組可能的動作;而預估的價值函數則稱為「評論家」(critic),其會根據給定的策略評估「演員」採取的動作。
在本教學中,「演員」和「評論家」都將使用一個具有兩個輸出的神經網路來表示。
CartPole-v0
在 CartPole-v0 環境中,桿子連接到沿著無摩擦軌道移動的手推車。桿子一開始是直立的,代理程式的目標是透過對手推車施加 -1 或 +1 的力來防止桿子倒下。每當桿子保持直立的每個時間步,就會給予 +1 的獎勵。當發生下列情況時,回合結束:1) 桿子與垂直方向的夾角超過 15 度;或 2) 手推車從中心移動超過 2.4 個單位。

當回合的平均總獎勵在 100 次連續試驗中達到 195 時,即視為問題已「解決」。
設定
匯入必要的套件並設定全域設定。
pip install gym[classic_control]pip install pyglet
# Install additional packages for visualizationsudo apt-get install -y python-opengl > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v1")
# Set seed for experiment reproducibility
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
模型
「演員」和「評論家」將使用一個神經網路來建模,該網路會分別產生動作機率和「評論家」價值。本教學使用模型子類別化來定義模型。
在正向傳遞期間,模型會將狀態作為輸入,並輸出動作機率和評論家價值 \(V\),後者會對狀態相關的價值函數建模。目標是訓練一個模型,使其根據最大化預期報酬的策略 \(\pi\) 來選擇動作。
對於 CartPole-v0,有四個值代表狀態:手推車位置、手推車速度、桿子角度和桿子速度。代理程式可以採取兩個動作來分別將手推車向左 (0) 和向右 (1) 推動。
如需更多資訊,請參閱 Gym 的 Cart Pole 文件頁面,以及 Barto、Sutton 和 Anderson (1983) 的著作 Neuronlike adaptive elements that can solve difficult learning control problems。
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
訓練代理程式
若要訓練代理程式,您將遵循以下步驟
- 在環境中執行代理程式,以收集每個回合的訓練資料。
- 計算每個時間步的預期報酬。
- 計算組合式 Actor-Critic 模型的損失。
- 計算梯度並更新網路參數。
- 重複步驟 1-4,直到達到成功標準或最大回合數。
1. 收集訓練資料
如同在監督式學習中,為了訓練 Actor-Critic 模型,您需要有訓練資料。但是,為了收集此類資料,模型需要在環境中「執行」。
訓練資料是針對每個回合收集的。然後在每個時間步,模型的正向傳遞將在環境的狀態下執行,以便根據模型權重參數化的目前策略,產生動作機率和評論家價值。
下一個動作將從模型產生的動作機率中取樣,然後將其應用於環境,進而產生下一個狀態和獎勵。
此流程在 run_episode 函數中實作,該函數使用 TensorFlow 運算,以便稍後可以將其編譯成 TensorFlow 圖表,以加快訓練速度。請注意,tf.TensorArray 用於支援可變長度陣列上的張量迭代。
# Wrap Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
@tf.numpy_function(Tout=[tf.float32, tf.int32, tf.int32])
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, truncated, info = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. 計算預期報酬
在一個回合中收集的每個時間步 \(t\) 的獎勵序列 \(\{r_{t}\}^{T}_{t=1}\) 會轉換為預期報酬序列 \(\{G_{t}\}^{T}_{t=1}\),其中獎勵總和取自目前時間步 \(t\) 到 \(T\),且每個獎勵都乘以指數衰減折扣因子 \(\gamma\)
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
由於 \(\gamma\in(0,1)\),因此距離目前時間步較遠的獎勵權重較低。
直覺上,預期報酬僅表示現在的獎勵優於稍後的獎勵。在數學意義上,這是為了確保獎勵總和收斂。
為了穩定訓練,產生的報酬序列也會標準化(即具有零平均值和單位標準差)。
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. Actor-Critic 損失
由於您使用的是混合式 Actor-Critic 模型,因此選擇的損失函數是「演員」和「評論家」損失的組合,如下所示
\[L = L_{actor} + L_{critic}\]
「演員」損失
「演員」損失基於以「評論家」作為狀態相關基準的策略梯度,並以單樣本(每個回合)估計值計算。
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
其中
- \(T\):每個回合的時間步數,每個回合可能不同
- \(s_{t}\):時間步 \(t\) 的狀態
- \(a_{t}\):在時間步 \(t\) 給定狀態 \(s\) 時選擇的動作
- \(\pi_{\theta}\):是由 \(\theta\) 參數化的策略(「演員」)
- \(V^{\pi}_{\theta}\):也是由 \(\theta\) 參數化的價值函數(「評論家」)
- \(G = G_{t}\):在時間步 \(t\) 給定狀態、動作組的預期報酬
在總和中加入負項,因為其概念是透過最小化組合損失,最大化產生較高獎勵的動作機率。
優勢
我們 \(L_{actor}\) 公式中的 \(G - V\) 項稱為「優勢」(Advantage),其表示在給定特定狀態下,某個動作相較於根據該狀態的策略 \(\pi\) 選擇的隨機動作好多少。
雖然可以排除基準線,但這可能會導致訓練期間出現高變異數。而選擇「評論家」\(V\) 作為基準線的好處是,它經過訓練盡可能接近 \(G\),從而降低變異數。
此外,如果沒有「評論家」,演算法會嘗試根據預期報酬提高在特定狀態下採取的動作機率,但如果動作之間的相對機率保持不變,則可能不會有太大差異。
例如,假設給定狀態的兩個動作會產生相同的預期報酬。如果沒有「評論家」,演算法會嘗試根據目標 \(J\) 提高這些動作的機率。有了「評論家」,可能會發現沒有「優勢」(\(G - V = 0\)),因此增加動作機率沒有任何好處,而演算法會將梯度設為零。
「評論家」損失
將 \(V\) 訓練為盡可能接近 \(G\) 可以設定為迴歸問題,並使用以下損失函數
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
其中 \(L_{\delta}\) 是 Huber 損失,其對資料中離群值的敏感度低於平方誤差損失。
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined Actor-Critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. 定義更新參數的訓練步驟
上述所有步驟都組合為每個回合執行的訓練步驟。達到損失函數的所有步驟都使用 tf.GradientTape 內容執行,以啟用自動微分。
本教學使用 Adam 最佳化工具將梯度應用於模型參數。
在這個步驟中也會計算未折扣獎勵的總和 episode_reward。此值稍後將用於評估是否符合成功標準。
tf.function 內容會應用於 train_step 函數,以便可以將其編譯為可呼叫的 TensorFlow 圖表,這可以使訓練速度提高 10 倍。
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate the expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculate the loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. 執行訓練迴圈
訓練是透過執行訓練步驟來完成,直到達到成功標準或最大回合數。
回合獎勵的執行記錄會保存在佇列中。達到 100 次試驗後,最舊的獎勵會從佇列的左端(尾端)移除,而最新的獎勵會新增至前端(右端)。為了計算效率,也會維護獎勵的執行總和。
根據您的執行時間,訓練可能會在不到一分鐘內完成。
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 500
# `CartPole-v1` is considered solved if average reward is >= 475 over 500
# consecutive trials
reward_threshold = 475
running_reward = 0
# The discount factor for future rewards
gamma = 0.99
# Keep the last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
t = tqdm.trange(max_episodes)
for i in t:
initial_state, info = env.reset()
initial_state = tf.constant(initial_state, dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show the average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
0%| | 0/10000 [00:00<?, ?it/s]/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/gym/utils/passive_env_checker.py:233: DeprecationWarning: `np.bool8` is a deprecated alias for `np.bool_`. (Deprecated NumPy 1.24) if not isinstance(terminated, (bool, np.bool8)): 11%|█▏ | 1138/10000 [03:54<30:29, 4.84it/s, episode_reward=500, running_reward=475] Solved at episode 1138: average reward: 475.13! CPU times: user 8min 21s, sys: 1min 20s, total: 9min 41s Wall time: 3min 54s
視覺化
訓練完成後,最好將模型在環境中的效能視覺化。您可以執行以下儲存格來產生模型單次回合執行的 GIF 動畫。請注意,需要安裝其他套件,Gym 才能在 Colab 中正確轉譯環境的圖片。
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
render_env = gym.make("CartPole-v1", render_mode='rgb_array')
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
state, info = env.reset()
state = tf.constant(state, dtype=tf.float32)
screen = env.render()
images = [Image.fromarray(screen)]
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, reward, done, truncated, info = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render()
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(render_env, model, max_steps_per_episode)
image_file = 'cartpole-v1.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
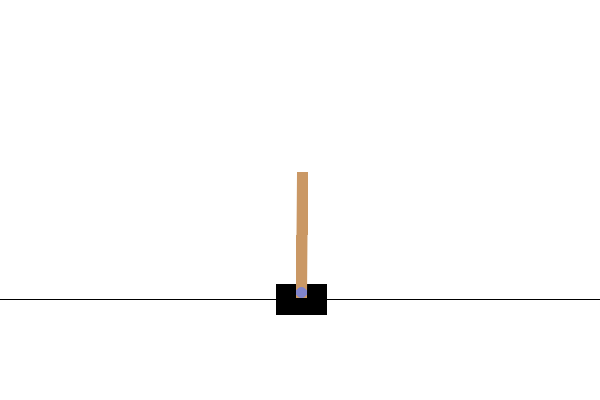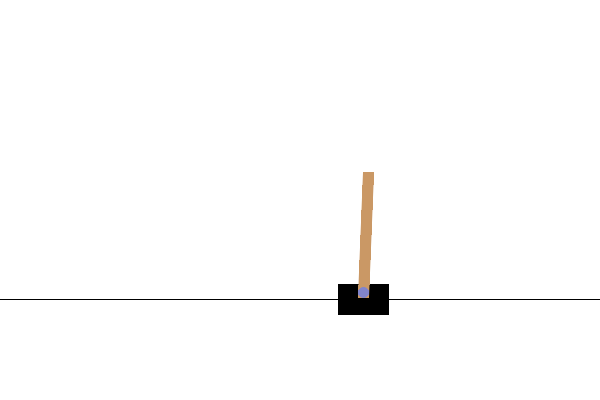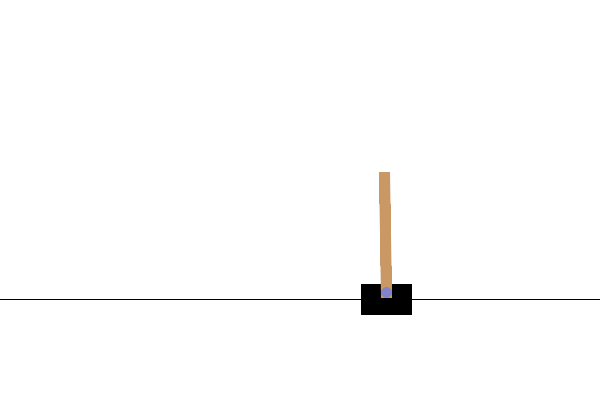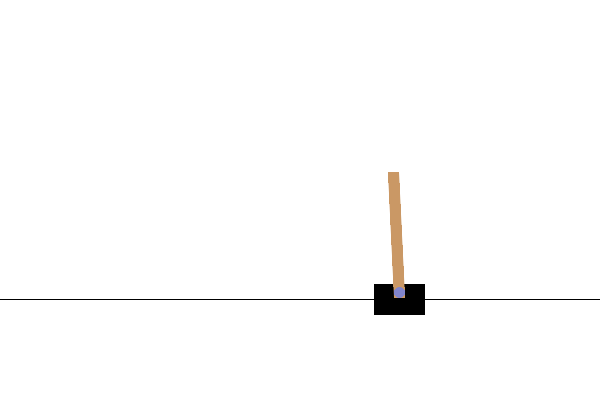
後續步驟
本教學示範如何使用 Tensorflow 實作 Actor-Critic 方法。
作為後續步驟,您可以嘗試在 Gym 中的不同環境中訓練模型。
如需有關 Actor-Critic 方法和 Cartpole-v0 問題的其他資訊,您可以參閱下列資源
如需 TensorFlow 中更多強化學習範例,您可以查看下列資源