
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
本教學課程著重於影像分割的任務,使用修改過的 U-Net。
什麼是影像分割?
在影像分類任務中,網路會為每個輸入影像指派標籤 (或類別)。但是,假設您想知道該物件的形狀、哪個像素屬於哪個物件等等。在這種情況下,您需要為影像的每個像素指派類別,此任務稱為分割。分割模型會傳回關於影像的更多詳細資訊。影像分割在醫療影像、自動駕駛汽車和衛星影像等領域有許多應用,僅舉幾例。
本教學課程使用 Oxford-IIIT Pet 資料集 (Parkhi et al, 2012)。資料集包含 37 種寵物犬品種的影像,每個品種有 200 張影像 (訓練和測試分割中各有約 100 張)。每張影像都包含對應的標籤和像素級遮罩。遮罩是每個像素的類別標籤。每個像素都指定為三個類別之一
- 類別 1:屬於寵物的像素。
- 類別 2:與寵物邊界相鄰的像素。
- 類別 3:非上述類別/周圍的像素。
pip install git+https://github.com/tensorflow/examples.gitpip install -U keraspip install -q tensorflow_datasetspip install -q -U tensorflow-text tensorflow
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
下載 Oxford-IIIT Pets 資料集
此資料集可從 TensorFlow Datasets 取得。分割遮罩包含在版本 3+ 中。
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
此外,影像色彩值已正規化為 [0, 1] 範圍。最後,如上所述,分割遮罩中的像素標記為 {1, 2, 3}。為方便起見,從分割遮罩中減去 1,使標籤變成:{0, 1, 2}。
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(
datapoint['segmentation_mask'],
(128, 128),
method = tf.image.ResizeMethod.NEAREST_NEIGHBOR,
)
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
資料集已包含所需的訓練和測試分割,因此繼續使用相同的分割
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
下列類別透過隨機翻轉影像來執行簡單的擴增。前往影像擴增教學課程以瞭解詳情。
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
建構輸入管線,在批次處理輸入後套用擴增
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
從資料集中視覺化影像範例及其對應的遮罩
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment

2024-04-13 01:21:27.796241: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

2024-04-13 01:21:27.964240: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
定義模型
此處使用的模型是修改過的 U-Net。U-Net 由編碼器 (降採樣器) 和解碼器 (升採樣器) 組成。為了學習穩健的特徵並減少可訓練參數的數量,請使用預訓練模型—MobileNetV2—作為編碼器。對於解碼器,您將使用升採樣區塊,此區塊已在 TensorFlow Examples 存放庫中的 pix2pix 範例中實作。(請查看筆記本中的「pix2pix:使用條件式 GAN 進行影像對影像翻譯」教學課程。)
如前所述,編碼器是預訓練的 MobileNetV2 模型。您將使用來自 tf.keras.applications 的模型。編碼器由模型中介層的特定輸出組成。請注意,編碼器在訓練過程中不會接受訓練。
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9406464/9406464 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
解碼器/升採樣器只是一系列在 TensorFlow 範例中實作的升採樣區塊
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
請注意,最後一層的篩選器數量設定為 output_channels 的數量。每個類別將有一個輸出通道。
訓練模型
現在,剩下要做的就是編譯和訓練模型。
由於這是多類別分類問題,因此請使用 tf.keras.losses.SparseCategoricalCrossentropy 損失函數,並將 from_logits 引數設定為 True,因為標籤是純量整數,而不是每個類別的每個像素的分數向量。
在執行推論時,指派給像素的標籤是具有最高值的通道。這就是 create_mask 函數的作用。
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
繪製產生的模型架構圖
tf.keras.utils.plot_model(model, show_shapes=True, expand_nested=True, dpi=64)

在訓練前試用模型以檢查其預測結果
def create_mask(pred_mask):
pred_mask = tf.math.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1712971291.476380 10584 service.cc:145] XLA service 0x7f59b0002000 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices: I0000 00:00:1712971291.476433 10584 service.cc:153] StreamExecutor device (0): Tesla T4, Compute Capability 7.5 I0000 00:00:1712971291.476437 10584 service.cc:153] StreamExecutor device (1): Tesla T4, Compute Capability 7.5 I0000 00:00:1712971291.476440 10584 service.cc:153] StreamExecutor device (2): Tesla T4, Compute Capability 7.5 I0000 00:00:1712971291.476443 10584 service.cc:153] StreamExecutor device (3): Tesla T4, Compute Capability 7.5 1/1 ━━━━━━━━━━━━━━━━━━━━ 5s 5s/step I0000 00:00:1712971295.614196 10584 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.

下面定義的回呼用於觀察模型在訓練時的改進情況
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 46ms/step

Sample Prediction after epoch 20 57/57 ━━━━━━━━━━━━━━━━━━━━ 6s 109ms/step - accuracy: 0.9271 - loss: 0.1783 - val_accuracy: 0.9080 - val_loss: 0.2467
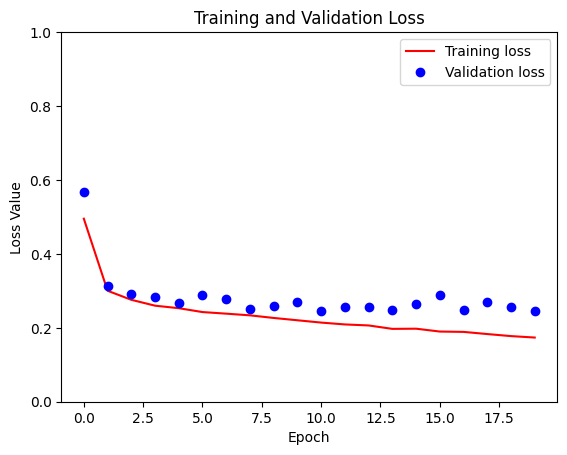
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
進行預測
現在,進行一些預測。為了節省時間,將 epoch 數量保持在較小的值,但您可以將此值設定為較高以獲得更準確的結果。
show_predictions(test_batches, 3)
2/2 ━━━━━━━━━━━━━━━━━━━━ 2s 27ms/step
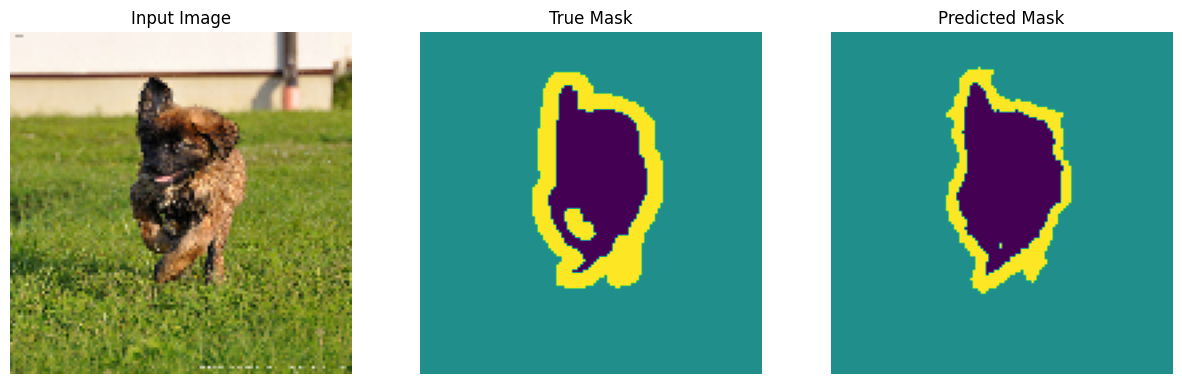
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step
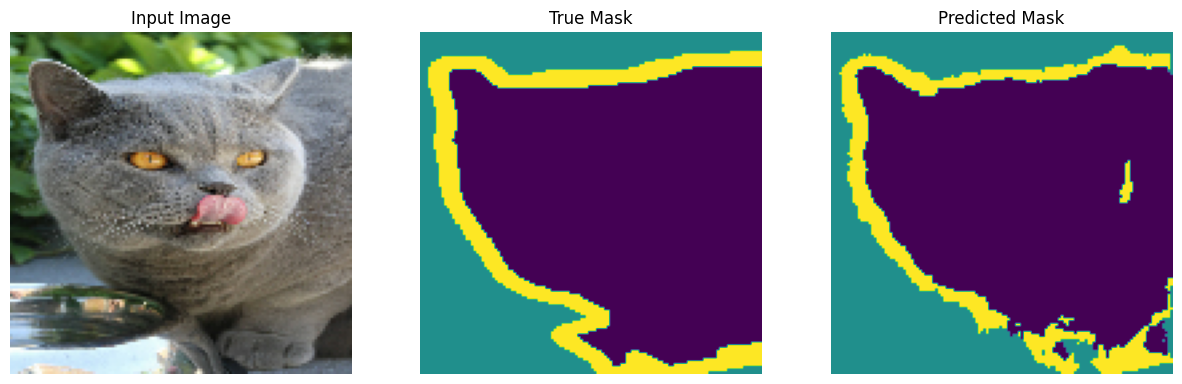
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step

2024-04-13 01:24:26.351284: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
選用項目:不平衡類別和類別權重
語意分割資料集可能高度不平衡,這表示特定類別的像素可能比其他類別的像素更多地出現在影像中。由於分割問題可以視為每個像素的分類問題來處理,因此您可以透過權衡損失函數來解決不平衡問題,以解決此問題。這是處理此問題的簡單而優雅的方法。請參閱不平衡資料的分類教學課程以瞭解詳情。
為了避免模稜兩可,Model.fit 不支援維度為 3+ 的目標的 class_weight 引數。
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Epoch 1/20 W0000 00:00:1712971470.137772 10583 assert_op.cc:38] Ignoring Assert operator compile_loss/sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/assert_equal_1/Assert/Assert 57/57 ━━━━━━━━━━━━━━━━━━━━ 12s 96ms/step - accuracy: 0.9248 - loss: 0.2493 Epoch 2/20 W0000 00:00:1712971478.676844 10582 assert_op.cc:38] Ignoring Assert operator compile_loss/sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/assert_equal_1/Assert/Assert 57/57 ━━━━━━━━━━━━━━━━━━━━ 8s 97ms/step - accuracy: 0.9208 - loss: 0.2617 Epoch 3/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 97ms/step - accuracy: 0.9250 - loss: 0.2464 Epoch 4/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 6s 98ms/step - accuracy: 0.9275 - loss: 0.2350 Epoch 5/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 6s 98ms/step - accuracy: 0.9289 - loss: 0.2300 Epoch 6/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 6s 98ms/step - accuracy: 0.9305 - loss: 0.2217 Epoch 7/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 6s 97ms/step - accuracy: 0.9340 - loss: 0.2095 Epoch 8/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 96ms/step - accuracy: 0.9349 - loss: 0.2075 Epoch 9/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 96ms/step - accuracy: 0.9344 - loss: 0.2091 Epoch 10/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 95ms/step - accuracy: 0.9380 - loss: 0.1949 Epoch 11/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 95ms/step - accuracy: 0.9379 - loss: 0.1953 Epoch 12/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 94ms/step - accuracy: 0.9409 - loss: 0.1839 Epoch 13/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 94ms/step - accuracy: 0.9421 - loss: 0.1816 Epoch 14/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 94ms/step - accuracy: 0.9437 - loss: 0.1737 Epoch 15/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 95ms/step - accuracy: 0.9446 - loss: 0.1724 Epoch 16/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 95ms/step - accuracy: 0.9459 - loss: 0.1675 Epoch 17/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 95ms/step - accuracy: 0.9479 - loss: 0.1616 Epoch 18/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 95ms/step - accuracy: 0.9484 - loss: 0.1588 Epoch 19/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 95ms/step - accuracy: 0.9484 - loss: 0.1599 Epoch 20/20 57/57 ━━━━━━━━━━━━━━━━━━━━ 5s 96ms/step - accuracy: 0.9496 - loss: 0.1564 Expected AssertionError:
因此,在這種情況下,您需要自行實作加權。您將使用範例權重來執行此操作:除了 (data、label) 配對之外,Model.fit 也接受 (data、label、sample_weight) 三元組。
Keras Model.fit 會將 sample_weight 傳播到損失和指標,損失和指標也接受 sample_weight 引數。範例權重會在縮減步驟之前乘以範例的值。例如
label = np.array([0,0])
prediction = np.array([[-3., 0], [-3, 0]])
sample_weight = [1, 10]
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction=tf.keras.losses.Reduction.NONE
)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
因此,若要為本教學課程製作範例權重,您需要一個函數,此函數會採用 (data、label) 配對並傳回 (data、label、sample_weight) 三元組,其中 sample_weight 是包含每個像素類別權重的單通道影像。
最簡單的實作方式是使用標籤作為 class_weight 清單的索引
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
產生的資料集元素各包含 3 個影像
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
現在,您可以在此加權資料集上訓練模型
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
W0000 00:00:1712971591.144762 10585 assert_op.cc:38] Ignoring Assert operator compile_loss/sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/assert_equal_1/Assert/Assert 10/10 ━━━━━━━━━━━━━━━━━━━━ 9s 100ms/step - accuracy: 0.5474 - loss: 0.3538 <keras.src.callbacks.history.History at 0x7f5ac8738550>
後續步驟
現在您已瞭解影像分割是什麼以及其運作方式,您可以嘗試使用不同的中介層輸出,甚至不同的預訓練模型來試用本教學課程。您也可以透過嘗試 Kaggle 上託管的 Carvana 影像遮罩挑戰來挑戰自己。
您可能也想查看 Tensorflow Object Detection API,以取得另一個您可以在自己的資料上重新訓練的模型。預訓練模型可在 TensorFlow Hub 上取得。