
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
本教學課程示範如何使用深度卷積生成對抗網路 (DCGAN) 生成手寫數字影像。程式碼是使用 Keras Sequential API 和 tf.GradientTape 訓練迴圈編寫的。
什麼是 GAN?
生成對抗網路 (GAN) 是當今電腦科學中最有趣的想法之一。兩個模型透過對抗過程同時訓練。*生成器*(「藝術家」)學習創建看起來真實的影像,而*鑑別器*(「藝術評論家」)學習區分真實影像和偽造影像。
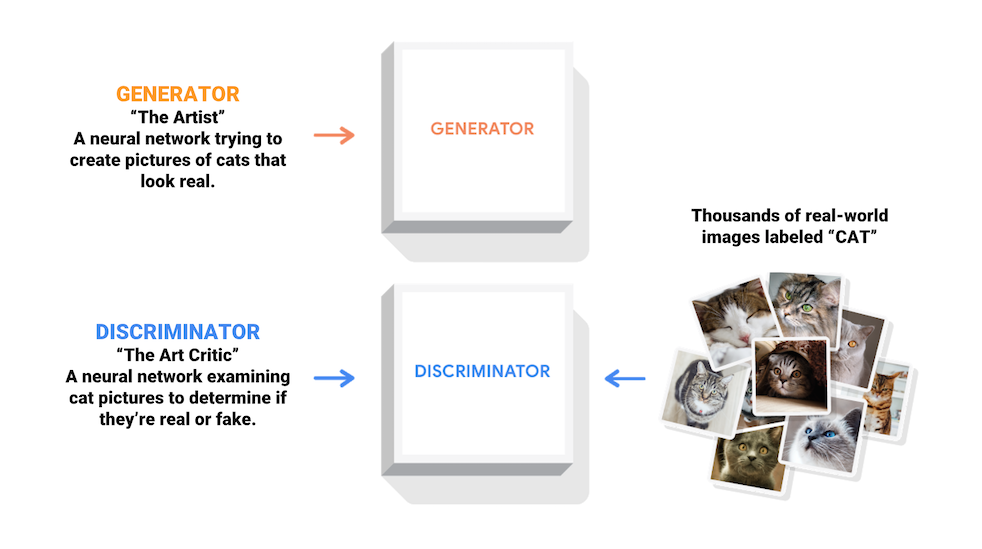
在訓練期間,*生成器*逐漸擅長創建看起來真實的影像,而*鑑別器*則更擅長區分它們。當*鑑別器*無法再區分真實影像和偽造影像時,該過程達到平衡。
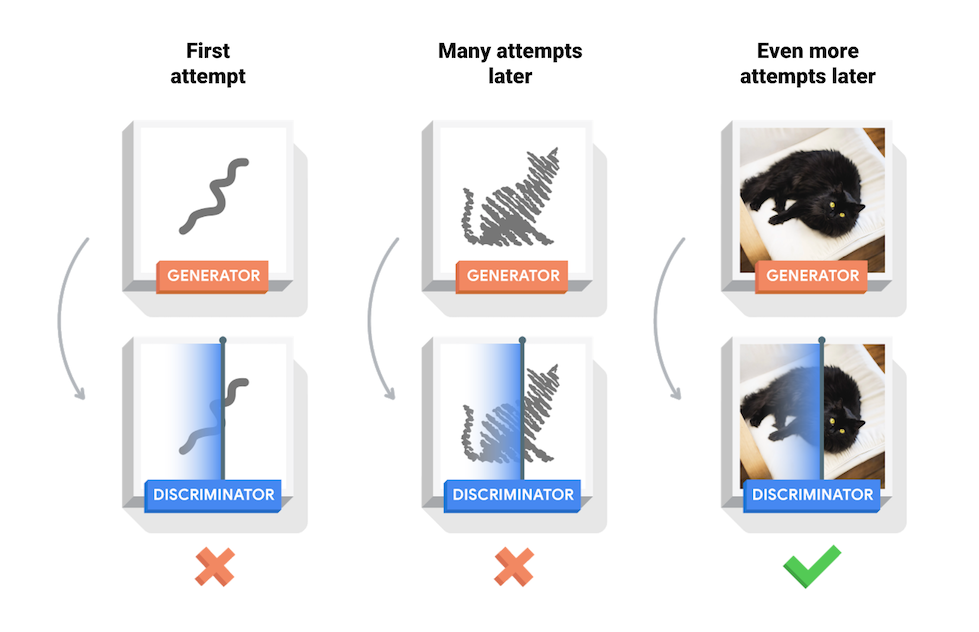
本筆記本示範了在 MNIST 資料集上進行的此過程。以下動畫顯示了*生成器*在經過 50 個 epoch 訓練後產生的一系列影像。影像一開始是隨機雜訊,隨著時間的推移,越來越像手寫數字。

若要瞭解更多關於 GAN 的資訊,請參閱麻省理工學院的「深度學習入門」課程。
設定
import tensorflow as tf
tf.__version__
'2.16.1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
載入和準備資料集
您將使用 MNIST 資料集來訓練生成器和鑑別器。生成器將生成類似於 MNIST 資料集的手寫數字。
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
建立模型
生成器和鑑別器都是使用 Keras Sequential API 定義的。
生成器
生成器使用 tf.keras.layers.Conv2DTranspose(上採樣)層從種子(隨機雜訊)產生影像。從以該種子作為輸入的 Dense 層開始,然後進行多次上採樣,直到達到所需的 28x28x1 影像大小。請注意,除了輸出層使用 tanh 之外,每一層都使用 tf.keras.layers.LeakyReLU 啟動函數。
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
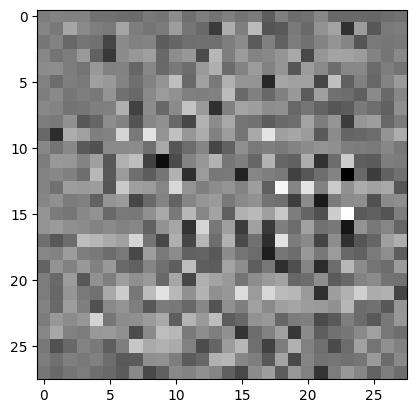
使用(尚未訓練的)生成器建立影像。
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/layers/core/dense.py:88: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead. super().__init__(activity_regularizer=activity_regularizer, **kwargs) <matplotlib.image.AxesImage at 0x7f1c44809fa0>
鑑別器
鑑別器是一個基於 CNN 的影像分類器。
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
使用(尚未訓練的)鑑別器將生成的影像分類為真實或偽造。該模型將被訓練為真實影像輸出正值,為偽造影像輸出負值。
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[0.00231416]], shape=(1, 1), dtype=float32) /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/layers/convolutional/base_conv.py:99: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead. super().__init__(
定義損失和優化器
為兩個模型定義損失函數和優化器。
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
鑑別器損失
此方法量化了鑑別器區分真實影像和偽造影像的能力。它將鑑別器對真實影像的預測與 1 的陣列進行比較,並將鑑別器對偽造(生成)影像的預測與 0 的陣列進行比較。
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
生成器損失
生成器的損失量化了它欺騙鑑別器的能力。直觀地說,如果生成器表現良好,鑑別器會將偽造影像分類為真實(或 1)。在此,將鑑別器對生成影像的決策與 1 的陣列進行比較。
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
鑑別器和生成器優化器是不同的,因為您將分別訓練兩個網路。
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
儲存檢查點
本筆記本也示範了如何儲存和還原模型,這在長時間運行的訓練任務中斷時可能很有用。
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
定義訓練迴圈
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
訓練迴圈從生成器接收隨機種子作為輸入開始。該種子用於產生影像。然後使用鑑別器對真實影像(從訓練集中提取)和偽造影像(由生成器產生)進行分類。計算每個模型的損失,並使用梯度來更新生成器和鑑別器。
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
生成並儲存影像
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
訓練模型
呼叫上面定義的 train() 方法以同時訓練生成器和鑑別器。請注意,訓練 GAN 可能很棘手。重要的是,生成器和鑑別器不要互相壓制(例如,它們以相似的速度訓練)。
在訓練開始時,生成的影像看起來像隨機雜訊。隨著訓練的進行,生成的數字將看起來越來越真實。大約 50 個 epoch 後,它們類似於 MNIST 數字。使用 Colab 上的預設設定,這可能需要大約一分鐘/epoch。
train(train_dataset, EPOCHS)

還原最新的檢查點。
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f1c44809d00>
建立 GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

使用 imageio 建立動畫 gif,使用訓練期間儲存的影像。
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
/tmpfs/tmp/ipykernel_125567/1982054950.py:7: DeprecationWarning: Starting with ImageIO v3 the behavior of this function will switch to that of iio.v3.imread. To keep the current behavior (and make this warning disappear) use `import imageio.v2 as imageio` or call `imageio.v2.imread` directly. image = imageio.imread(filename) /tmpfs/tmp/ipykernel_125567/1982054950.py:9: DeprecationWarning: Starting with ImageIO v3 the behavior of this function will switch to that of iio.v3.imread. To keep the current behavior (and make this warning disappear) use `import imageio.v2 as imageio` or call `imageio.v2.imread` directly. image = imageio.imread(filename)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

後續步驟
本教學課程已展示編寫和訓練 GAN 所需的完整程式碼。作為下一步,您可能想嘗試使用不同的資料集,例如 Kaggle 上提供的大規模 Celeb Faces Attributes (CelebA) 資料集。若要瞭解更多關於 GAN 的資訊,請參閱「NIPS 2016 Tutorial: Generative Adversarial Networks」。