
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
總覽
DTensor 提供在裝置之間分散模型訓練的方式,以提高效率、可靠性和可擴充性。如需更多詳細資訊,請查看 DTensor 概念指南。
在本教學課程中,您將使用 DTensor 訓練情感分析模型。此範例示範三種分散式訓練架構
- 資料平行訓練,其中訓練樣本會分片 (分割) 至裝置。
- 模型平行訓練,其中模型變數會分片至裝置。
- 空間平行訓練,其中輸入資料的特徵會分片至裝置 (也稱為 空間分割)。
本教學課程的訓練部分靈感來自名為 Kaggle 情感分析指南的 Kaggle 筆記本。若要瞭解完整的訓練和評估工作流程 (不含 DTensor),請參閱該筆記本。
本教學課程將逐步說明下列步驟
- 一些資料清理,以取得權杖化句子及其極性的
tf.data.Dataset。 - 接著,使用
tf.Module搭配自訂 Dense 和 BatchNorm 層建構 MLP 模型,以追蹤推論變數。模型建構函式會採用額外的Layout引數來控制變數的分片。 - 針對訓練,您會先使用資料平行訓練以及
tf.experimental.dtensor的檢查點功能。然後,您將繼續進行模型平行訓練和空間平行訓練。 - 最後一節簡要說明 TensorFlow 2.9 中
tf.saved_model和tf.experimental.dtensor之間的互動。
設定
DTensor (tf.experimental.dtensor) 自 2.9.0 版本以來一直是 TensorFlow 的一部分。
首先,安裝或升級 TensorFlow Datasets
pip install --quiet --upgrade tensorflow-datasets
接著,匯入 tensorflow 和 dtensor,並將 TensorFlow 設定為使用 8 個虛擬 CPU。
即使此範例使用虛擬 CPU,DTensor 在 CPU、GPU 或 TPU 裝置上的運作方式也相同。
import tempfile
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
from tensorflow.experimental import dtensor
print('TensorFlow version:', tf.__version__)
def configure_virtual_cpus(ncpu):
phy_devices = tf.config.list_physical_devices('CPU')
tf.config.set_logical_device_configuration(phy_devices[0], [
tf.config.LogicalDeviceConfiguration(),
] * ncpu)
configure_virtual_cpus(8)
DEVICES = [f'CPU:{i}' for i in range(8)]
tf.config.list_logical_devices('CPU')
下載資料集
下載 IMDB 評論資料集以訓練情感分析模型
train_data = tfds.load('imdb_reviews', split='train', shuffle_files=True, batch_size=64)
train_data
準備資料
首先將文字權杖化。此處使用單熱編碼的擴充功能,即 tf.keras.layers.TextVectorization 的 'tf_idf' 模式。
- 為了加快速度,將權杖數量限制為 1200 個。
- 為了簡化
tf.Module,請在訓練前執行TextVectorization作為預先處理步驟。
資料清理章節的最終結果是 Dataset,其中權杖化文字為 x,標籤為 y。
text_vectorization = tf.keras.layers.TextVectorization(output_mode='tf_idf', max_tokens=1200, output_sequence_length=None)
text_vectorization.adapt(data=train_data.map(lambda x: x['text']))
def vectorize(features):
return text_vectorization(features['text']), features['label']
train_data_vec = train_data.map(vectorize)
train_data_vec
使用 DTensor 建構神經網路
現在使用 DTensor 建構多層感知器 (MLP) 網路。此網路將使用完全連線的 Dense 和 BatchNorm 層。
DTensor 透過根據其輸入 Tensor 和變數的 dtensor.Layout 屬性,對一般 TensorFlow 運算進行單一程式多資料 (SPMD) 擴充,來擴充 TensorFlow。
DTensor 感知層的變數是 dtensor.DVariable,而 DTensor 感知層物件的建構函式除了通常的層參數外,還採用額外的 Layout 輸入。
Dense 層
下列自訂 Dense 層定義 2 個層變數:\(W_{ij}\) 是權重的變數,而 \(b_i\) 是偏差的變數。
\[ y_j = \sigma(\sum_i x_i W_{ij} + b_j) \]
版面配置推導
此結果來自下列觀察
矩陣點積 \(t_j = \sum_i x_i W_{ij}\) 運算元的慣用 DTensor 分片是沿著 \(i\) 軸以相同方式分片 \(\mathbf{W}\) 和 \(\mathbf{x}\)。
矩陣總和 \(t_j + b_j\) 運算元的慣用 DTensor 分片是沿著 \(j\) 軸以相同方式分片 \(\mathbf{t}\) 和 \(\mathbf{b}\)。
class Dense(tf.Module):
def __init__(self, input_size, output_size,
init_seed, weight_layout, activation=None):
super().__init__()
random_normal_initializer = tf.function(tf.random.stateless_normal)
self.weight = dtensor.DVariable(
dtensor.call_with_layout(
random_normal_initializer, weight_layout,
shape=[input_size, output_size],
seed=init_seed
))
if activation is None:
activation = lambda x:x
self.activation = activation
# bias is sharded the same way as the last axis of weight.
bias_layout = weight_layout.delete([0])
self.bias = dtensor.DVariable(
dtensor.call_with_layout(tf.zeros, bias_layout, [output_size]))
def __call__(self, x):
y = tf.matmul(x, self.weight) + self.bias
y = self.activation(y)
return y
BatchNorm
批次正規化層有助於避免在訓練時模式崩潰。在此案例中,新增批次正規化層有助於模型訓練避免產生僅產生零的模型。
下方的自訂 BatchNorm 層的建構函式未採用 Layout 引數。這是因為 BatchNorm 沒有層變數。這仍然適用於 DTensor,因為 'x' (層的唯一輸入) 已經是代表全域批次的 DTensor。
class BatchNorm(tf.Module):
def __init__(self):
super().__init__()
def __call__(self, x, training=True):
if not training:
# This branch is not used in the Tutorial.
pass
mean, variance = tf.nn.moments(x, axes=[0])
return tf.nn.batch_normalization(x, mean, variance, 0.0, 1.0, 1e-5)
完整功能的批次正規化層 (例如 tf.keras.layers.BatchNormalization) 將需要其變數的 Layout 引數。
def make_keras_bn(bn_layout):
return tf.keras.layers.BatchNormalization(gamma_layout=bn_layout,
beta_layout=bn_layout,
moving_mean_layout=bn_layout,
moving_variance_layout=bn_layout,
fused=False)
將層組合在一起
接著,使用上述建構區塊建構多層感知器 (MLP) 網路。下圖顯示輸入 x 與兩個 Dense 層的權重矩陣之間的軸關係,而未套用任何 DTensor 分片或複製。
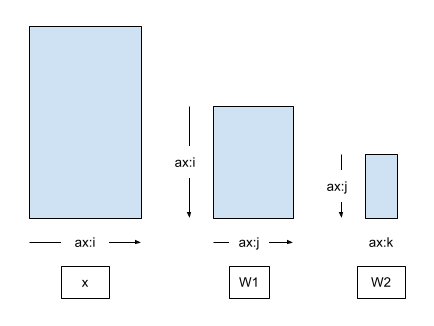
第一個 Dense 層的輸出會傳遞至第二個 Dense 層的輸入 (在 BatchNorm 之後)。因此,第一個 Dense 層 (\(\mathbf{W_1}\)) 的輸出和第二個 Dense 層 (\(\mathbf{W_2}\)) 的輸入的慣用 DTensor 分片是沿著共同軸 \(\hat{j}\) 以相同方式分片 \(\mathbf{W_1}\) 和 \(\mathbf{W_2}\)。
\[ \mathsf{Layout}[{W_{1,ij} }; i, j] = \left[\hat{i}, \hat{j}\right] \\ \mathsf{Layout}[{W_{2,jk} }; j, k] = \left[\hat{j}, \hat{k} \right] \]
即使版面配置推導顯示 2 個版面配置不是獨立的,但為了簡化模型介面,MLP 將採用 2 個 Layout 引數,每個 Dense 層各一個。
from typing import Tuple
class MLP(tf.Module):
def __init__(self, dense_layouts: Tuple[dtensor.Layout, dtensor.Layout]):
super().__init__()
self.dense1 = Dense(
1200, 48, (1, 2), dense_layouts[0], activation=tf.nn.relu)
self.bn = BatchNorm()
self.dense2 = Dense(48, 2, (3, 4), dense_layouts[1])
def __call__(self, x):
y = x
y = self.dense1(y)
y = self.bn(y)
y = self.dense2(y)
return y
在版面配置推導限制的正確性和 API 的簡潔性之間權衡取捨,是使用 DTensor 的 API 的常見設計點。也可以使用不同的 API 擷取 Layout 之間的依附關係。例如,MLPStricter 類別會在建構函式中建立 Layout 物件。
class MLPStricter(tf.Module):
def __init__(self, mesh, input_mesh_dim, inner_mesh_dim1, output_mesh_dim):
super().__init__()
self.dense1 = Dense(
1200, 48, (1, 2), dtensor.Layout([input_mesh_dim, inner_mesh_dim1], mesh),
activation=tf.nn.relu)
self.bn = BatchNorm()
self.dense2 = Dense(48, 2, (3, 4), dtensor.Layout([inner_mesh_dim1, output_mesh_dim], mesh))
def __call__(self, x):
y = x
y = self.dense1(y)
y = self.bn(y)
y = self.dense2(y)
return y
為了確保模型執行,請使用完全複製的版面配置和完全複製的 'x' 輸入批次來探測您的模型。
WORLD = dtensor.create_mesh([("world", 8)], devices=DEVICES)
model = MLP([dtensor.Layout.replicated(WORLD, rank=2),
dtensor.Layout.replicated(WORLD, rank=2)])
sample_x, sample_y = train_data_vec.take(1).get_single_element()
sample_x = dtensor.copy_to_mesh(sample_x, dtensor.Layout.replicated(WORLD, rank=2))
print(model(sample_x))
將資料移至裝置
通常,tf.data 迭代器 (和其他資料擷取方法) 會產生由本機主機裝置記憶體支援的張量物件。此資料必須傳輸到支援 DTensor 元件張量的加速器裝置記憶體。
dtensor.copy_to_mesh 不適用於這種情況,因為它會將輸入張量複製到所有裝置,這是因為 DTensor 的全域視角。因此在本教學課程中,您將使用輔助函式 repack_local_tensor 來協助資料傳輸。此輔助函式使用 dtensor.pack 來傳送 (且僅傳送) 旨在用於副本的全域批次分片至支援副本的裝置。
此簡化的函式假設為單一用戶端。在多用戶端應用程式中,判斷分割本機張量的正確方式以及分割片段與本機裝置之間的對應可能很費力。
計畫新增其他 DTensor API 以簡化 tf.data 整合,同時支援單一用戶端和多用戶端應用程式。敬請期待。
def repack_local_tensor(x, layout):
"""Repacks a local Tensor-like to a DTensor with layout.
This function assumes a single-client application.
"""
x = tf.convert_to_tensor(x)
sharded_dims = []
# For every sharded dimension, use tf.split to split the along the dimension.
# The result is a nested list of split-tensors in queue[0].
queue = [x]
for axis, dim in enumerate(layout.sharding_specs):
if dim == dtensor.UNSHARDED:
continue
num_splits = layout.shape[axis]
queue = tf.nest.map_structure(lambda x: tf.split(x, num_splits, axis=axis), queue)
sharded_dims.append(dim)
# Now we can build the list of component tensors by looking up the location in
# the nested list of split-tensors created in queue[0].
components = []
for locations in layout.mesh.local_device_locations():
t = queue[0]
for dim in sharded_dims:
split_index = locations[dim] # Only valid on single-client mesh.
t = t[split_index]
components.append(t)
return dtensor.pack(components, layout)
資料平行訓練
在本節中,您將使用資料平行訓練來訓練您的 MLP 模型。以下章節將示範模型平行訓練和空間平行訓練。
資料平行訓練是分散式機器學習的常用架構
- 模型變數會在 N 個裝置上各複製一份。
- 全域批次會分割成 N 個每個副本批次。
- 每個副本批次都會在副本裝置上訓練。
- 梯度會在權重更新資料之前縮減,並在所有副本上集體執行。
資料平行訓練在裝置數量方面提供近乎線性的加速。
建立資料平行網格
典型的資料平行訓練迴圈會使用 DTensor Mesh,其中包含單一 batch 維度,其中每個裝置都會成為接收來自全域批次分片的副本。
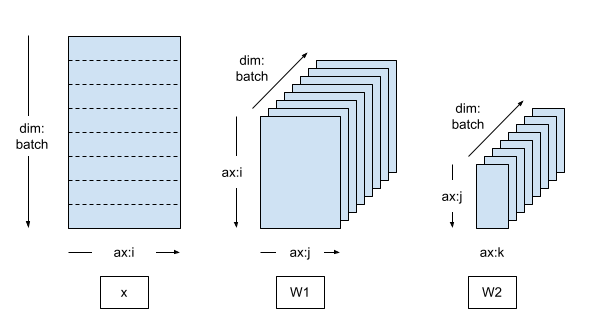
複製的模型會在副本上執行,因此模型變數會完全複製 (未分片)。
mesh = dtensor.create_mesh([("batch", 8)], devices=DEVICES)
model = MLP([dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh),
dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh),])
將訓練資料封裝至 DTensor
訓練資料批次應封裝到沿著 'batch' (第一個) 軸分片的 DTensor 中,以便 DTensor 將訓練資料均勻分配到 'batch' 網格維度。
def repack_batch(x, y, mesh):
x = repack_local_tensor(x, layout=dtensor.Layout(['batch', dtensor.UNSHARDED], mesh))
y = repack_local_tensor(y, layout=dtensor.Layout(['batch'], mesh))
return x, y
sample_x, sample_y = train_data_vec.take(1).get_single_element()
sample_x, sample_y = repack_batch(sample_x, sample_y, mesh)
print('x', sample_x[:, 0])
print('y', sample_y)
訓練步驟
此範例使用隨機梯度下降最佳化工具搭配自訂訓練迴圈 (CTL)。如需這些主題的更多資訊,請參閱自訂訓練迴圈指南和逐步解說。
train_step 封裝為 tf.function,以表示此主體將追蹤為 TensorFlow 圖表。train_step 的主體包含前向推論傳遞、反向梯度傳遞和變數更新。
請注意,train_step 的主體不包含任何特殊的 DTensor 註解。相反地,train_step 僅包含處理來自輸入批次和模型全域檢視的輸入 x 和 y 的高階 TensorFlow 運算。所有 DTensor 註解 (Mesh、Layout) 都從訓練步驟中分解出來。
# Refer to the CTL (custom training loop guide)
@tf.function
def train_step(model, x, y, learning_rate=tf.constant(1e-4)):
with tf.GradientTape() as tape:
logits = model(x)
# tf.reduce_sum sums the batch sharded per-example loss to a replicated
# global loss (scalar).
loss = tf.reduce_sum(
tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits, labels=y))
parameters = model.trainable_variables
gradients = tape.gradient(loss, parameters)
for parameter, parameter_gradient in zip(parameters, gradients):
parameter.assign_sub(learning_rate * parameter_gradient)
# Define some metrics
accuracy = 1.0 - tf.reduce_sum(tf.cast(tf.argmax(logits, axis=-1, output_type=tf.int64) != y, tf.float32)) / x.shape[0]
loss_per_sample = loss / len(x)
return {'loss': loss_per_sample, 'accuracy': accuracy}
檢查點
您可以直接使用 tf.train.Checkpoint 檢查 DTensor 模型。儲存和還原分片 DVariable 將執行有效率的分片儲存和還原。目前,使用 tf.train.Checkpoint.save 和 tf.train.Checkpoint.restore 時,所有 DVariable 都必須位於相同的主機網格上,且 DVariable 和一般變數無法一起儲存。您可以在本指南中瞭解關於檢查點的更多資訊。
還原 DTensor 檢查點時,變數的 Layout 可能與儲存檢查點時不同。也就是說,儲存 DTensor 模型與版面配置和網格無關,並且僅影響分片儲存的效率。您可以使用一個網格和版面配置儲存 DTensor 模型,並在不同的網格和版面配置上還原它。本教學課程利用此功能繼續進行模型平行訓練和空間平行訓練章節中的訓練。
CHECKPOINT_DIR = tempfile.mkdtemp()
def start_checkpoint_manager(model):
ckpt = tf.train.Checkpoint(root=model)
manager = tf.train.CheckpointManager(ckpt, CHECKPOINT_DIR, max_to_keep=3)
if manager.latest_checkpoint:
print("Restoring a checkpoint")
ckpt.restore(manager.latest_checkpoint).assert_consumed()
else:
print("New training")
return manager
訓練迴圈
針對資料平行訓練架構,訓練週期並報告進度。3 個週期不足以訓練模型,50% 的準確度與隨機猜測一樣好。
啟用檢查點,以便您稍後可以繼續訓練。在以下章節中,您將載入檢查點並使用不同的平行架構進行訓練。
num_epochs = 2
manager = start_checkpoint_manager(model)
for epoch in range(num_epochs):
step = 0
pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()), stateful_metrics=[])
metrics = {'epoch': epoch}
for x,y in train_data_vec:
x, y = repack_batch(x, y, mesh)
metrics.update(train_step(model, x, y, 1e-2))
pbar.update(step, values=metrics.items(), finalize=False)
step += 1
manager.save()
pbar.update(step, values=metrics.items(), finalize=True)
模型平行訓練
如果您切換到二維 Mesh,並沿著第二個網格維度分片模型變數,則訓練將變為模型平行。
在模型平行訓練中,每個模型副本跨越多個裝置 (在本例中為 2 個)
- 有 4 個模型副本,且訓練資料批次會分配給 4 個副本。
- 單一模型副本內的 2 個裝置會接收複製的訓練資料。
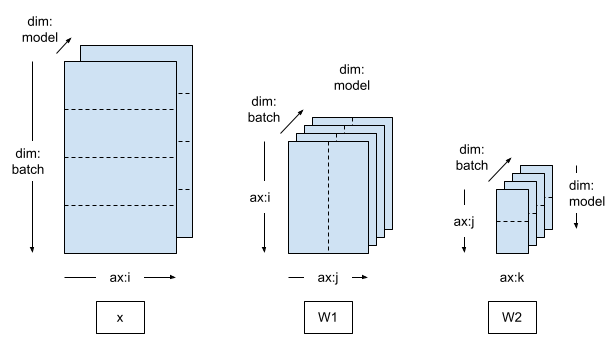
mesh = dtensor.create_mesh([("batch", 4), ("model", 2)], devices=DEVICES)
model = MLP([dtensor.Layout([dtensor.UNSHARDED, "model"], mesh),
dtensor.Layout(["model", dtensor.UNSHARDED], mesh)])
由於訓練資料仍然沿著批次維度分片,因此您可以重複使用與資料平行訓練案例相同的 repack_batch 函式。DTensor 會自動將每個副本批次複製到副本內沿著 "model" 網格維度的所有裝置。
def repack_batch(x, y, mesh):
x = repack_local_tensor(x, layout=dtensor.Layout(['batch', dtensor.UNSHARDED], mesh))
y = repack_local_tensor(y, layout=dtensor.Layout(['batch'], mesh))
return x, y
接著執行訓練迴圈。訓練迴圈會重複使用與資料平行訓練範例相同的檢查點管理員,且程式碼看起來完全相同。
您可以繼續在模型平行訓練下訓練資料平行訓練模型。
num_epochs = 2
manager = start_checkpoint_manager(model)
for epoch in range(num_epochs):
step = 0
pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()))
metrics = {'epoch': epoch}
for x,y in train_data_vec:
x, y = repack_batch(x, y, mesh)
metrics.update(train_step(model, x, y, 1e-2))
pbar.update(step, values=metrics.items(), finalize=False)
step += 1
manager.save()
pbar.update(step, values=metrics.items(), finalize=True)
空間平行訓練
當訓練非常高維度的資料 (例如非常大的圖片或影片) 時,可能需要沿著特徵維度分片。這稱為空間分割,此方法最初引入 TensorFlow,用於訓練具有大型 3D 輸入樣本的模型。
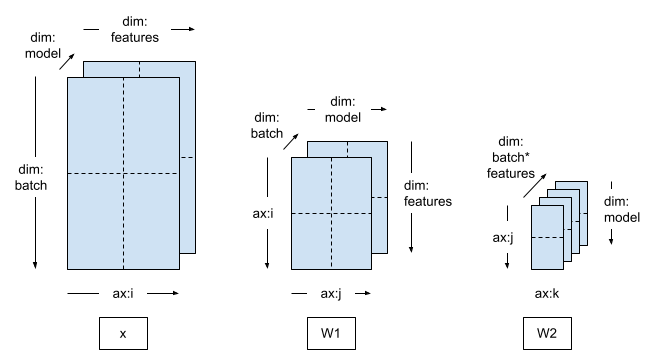
DTensor 也支援此案例。您唯一需要做的變更是建立包含 feature 維度的 Mesh,並套用對應的 Layout。
mesh = dtensor.create_mesh([("batch", 2), ("feature", 2), ("model", 2)], devices=DEVICES)
model = MLP([dtensor.Layout(["feature", "model"], mesh),
dtensor.Layout(["model", dtensor.UNSHARDED], mesh)])
將輸入張量封裝到 DTensor 時,沿著 feature 維度分片輸入資料。您可以使用稍微不同的重新封裝函式 repack_batch_for_spt 來執行此操作,其中 spt 代表空間平行訓練。
def repack_batch_for_spt(x, y, mesh):
# Shard data on feature dimension, too
x = repack_local_tensor(x, layout=dtensor.Layout(["batch", 'feature'], mesh))
y = repack_local_tensor(y, layout=dtensor.Layout(["batch"], mesh))
return x, y
空間平行訓練也可以從使用其他平行訓練架構建立的檢查點繼續進行。
num_epochs = 2
manager = start_checkpoint_manager(model)
for epoch in range(num_epochs):
step = 0
metrics = {'epoch': epoch}
pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()))
for x, y in train_data_vec:
x, y = repack_batch_for_spt(x, y, mesh)
metrics.update(train_step(model, x, y, 1e-2))
pbar.update(step, values=metrics.items(), finalize=False)
step += 1
manager.save()
pbar.update(step, values=metrics.items(), finalize=True)
SavedModel 和 DTensor
DTensor 和 SavedModel 的整合仍在開發中。
截至 TensorFlow 2.11,tf.saved_model 可以儲存分片和複製的 DTensor 模型,而儲存將在網格的不同裝置上執行有效率的分片儲存。但是,在模型儲存後,所有 DTensor 註解都會遺失,且儲存的簽名只能與一般張量搭配使用,而不能與 DTensor 搭配使用。
mesh = dtensor.create_mesh([("world", 1)], devices=DEVICES[:1])
mlp = MLP([dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh),
dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)])
manager = start_checkpoint_manager(mlp)
model_for_saving = tf.keras.Sequential([
text_vectorization,
mlp
])
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def run(inputs):
return {'result': model_for_saving(inputs)}
tf.saved_model.save(
model_for_saving, "/tmp/saved_model",
signatures=run)
截至 TensorFlow 2.9.0,您只能使用一般張量或完全複製的 DTensor (將轉換為一般張量) 呼叫載入的簽名。
sample_batch = train_data.take(1).get_single_element()
sample_batch
loaded = tf.saved_model.load("/tmp/saved_model")
run_sig = loaded.signatures["serving_default"]
result = run_sig(sample_batch['text'])['result']
np.mean(tf.argmax(result, axis=-1) == sample_batch['label'])
接下來的步驟?
本教學課程示範如何使用 DTensor 建構和訓練 MLP 情感分析模型。
透過 Mesh 和 Layout 基本元素,DTensor 可以將 TensorFlow tf.function 轉換為適用於各種訓練架構的分散式程式。
在真實世界的機器學習應用程式中,應套用評估和交叉驗證,以避免產生過度擬合的模型。本教學課程中介紹的技術也可用於將平行處理引入評估。
從頭開始使用 tf.Module 組成模型需要大量工作,而重複使用現有的建構區塊 (例如層和輔助函式) 可以大幅加快模型開發速度。截至 TensorFlow 2.9,tf.keras.layers 下的所有 Keras 層都接受 DTensor 版面配置作為其引數,並且可用於建構 DTensor 模型。您甚至可以直接重複使用具有 DTensor 的 Keras 模型,而無需修改模型實作。如需關於使用 DTensor Keras 的資訊,請參閱 DTensor Keras 整合教學課程。