|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
總覽
使用 TensorBoard Embedding Projector,您可以圖形化呈現高維度嵌入。這對於視覺化、檢查和理解您的嵌入層非常有幫助。
在本教學課程中,您將學習如何視覺化此類型的已訓練圖層。
設定
在本教學課程中,我們將使用 TensorBoard 來視覺化為電影評論資料分類產生的嵌入層。
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
IMDB 資料
我們將使用包含 25,000 筆 IMDB 電影評論的資料集,每筆評論都有情感標籤 (正面/負面)。每筆評論都經過預先處理並編碼為單字索引 (整數) 序列。為了簡化起見,單字會依資料集中整體的頻率編製索引,例如,整數「3」會編碼所有評論中出現頻率第 3 高的單字。這可進行快速篩選作業,例如:「僅考慮前 10,000 個最常見的單字,但排除前 20 個最常見的單字」。
依照慣例,「0」不代表任何特定單字,而是用來編碼任何不明單字。在本教學課程的稍後部分,我們將移除視覺化中的「0」列。
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Keras Embedding Layer
Keras Embedding Layer 可用於訓練詞彙中每個單字的嵌入。每個單字 (或本例中的子單字) 都會與 16 維向量 (或嵌入) 相關聯,該向量將由模型訓練。
請參閱本教學課程,以深入瞭解單字嵌入。
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
儲存 TensorBoard 的資料
TensorBoard 會從您的 tensorflow 專案記錄中讀取張量和中繼資料。記錄目錄的路徑在下方的 log_dir 中指定。在本教學課程中,我們將使用 /logs/imdb-example/。
為了將資料載入 Tensorboard,我們需要將訓練檢查點儲存到該目錄,以及允許視覺化模型中特定感興趣層的中繼資料。
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
分析
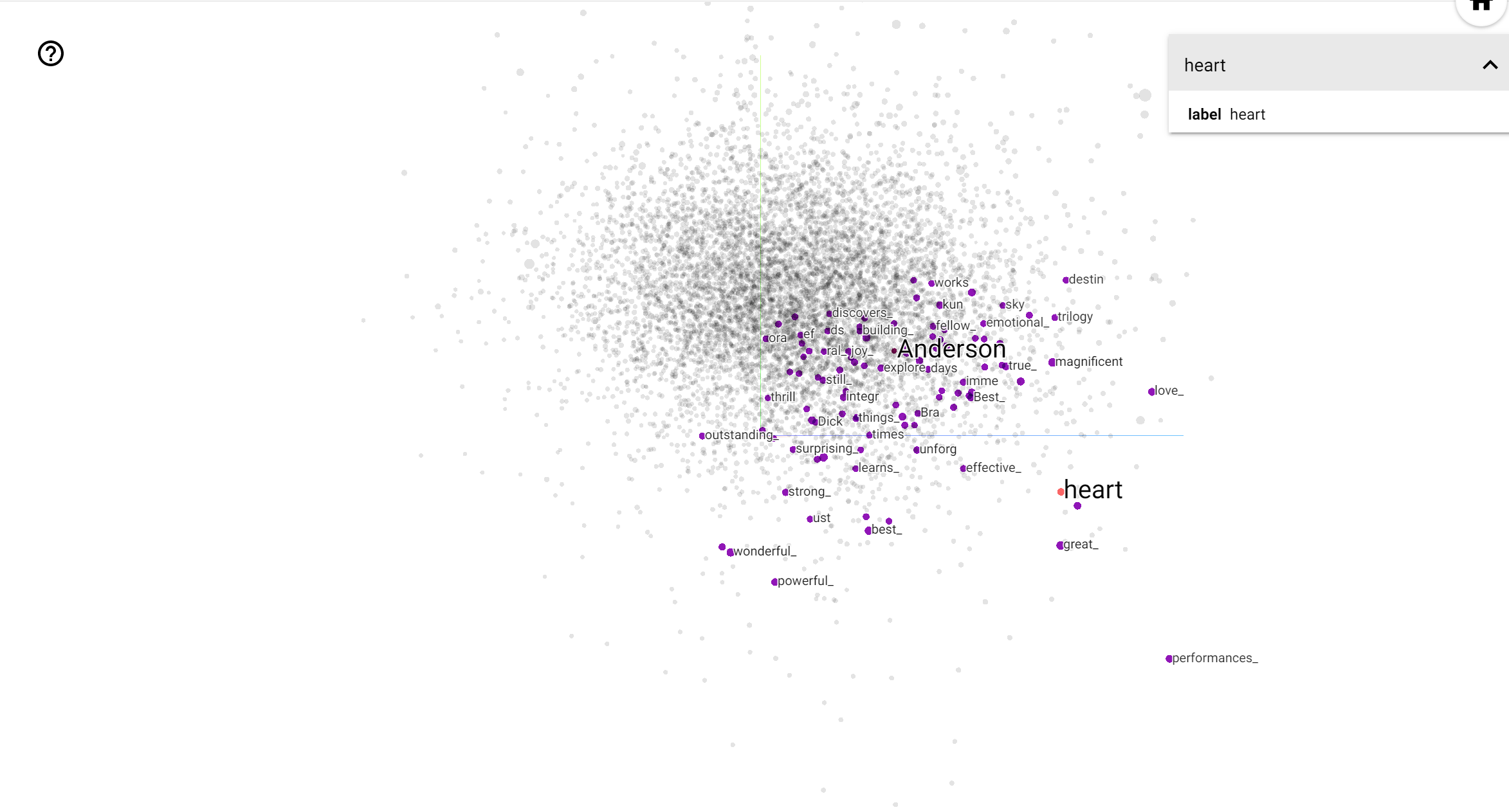
TensorBoard Projector 是解譯和視覺化嵌入的絕佳工具。儀表板允許使用者搜尋特定詞彙,並醒目提示嵌入 (低維度) 空間中彼此相鄰的單字。從此範例中,我們可以看到 Wes Anderson 和 Alfred Hitchcock 都是相當中性的詞彙,但它們在不同的脈絡中被提及。
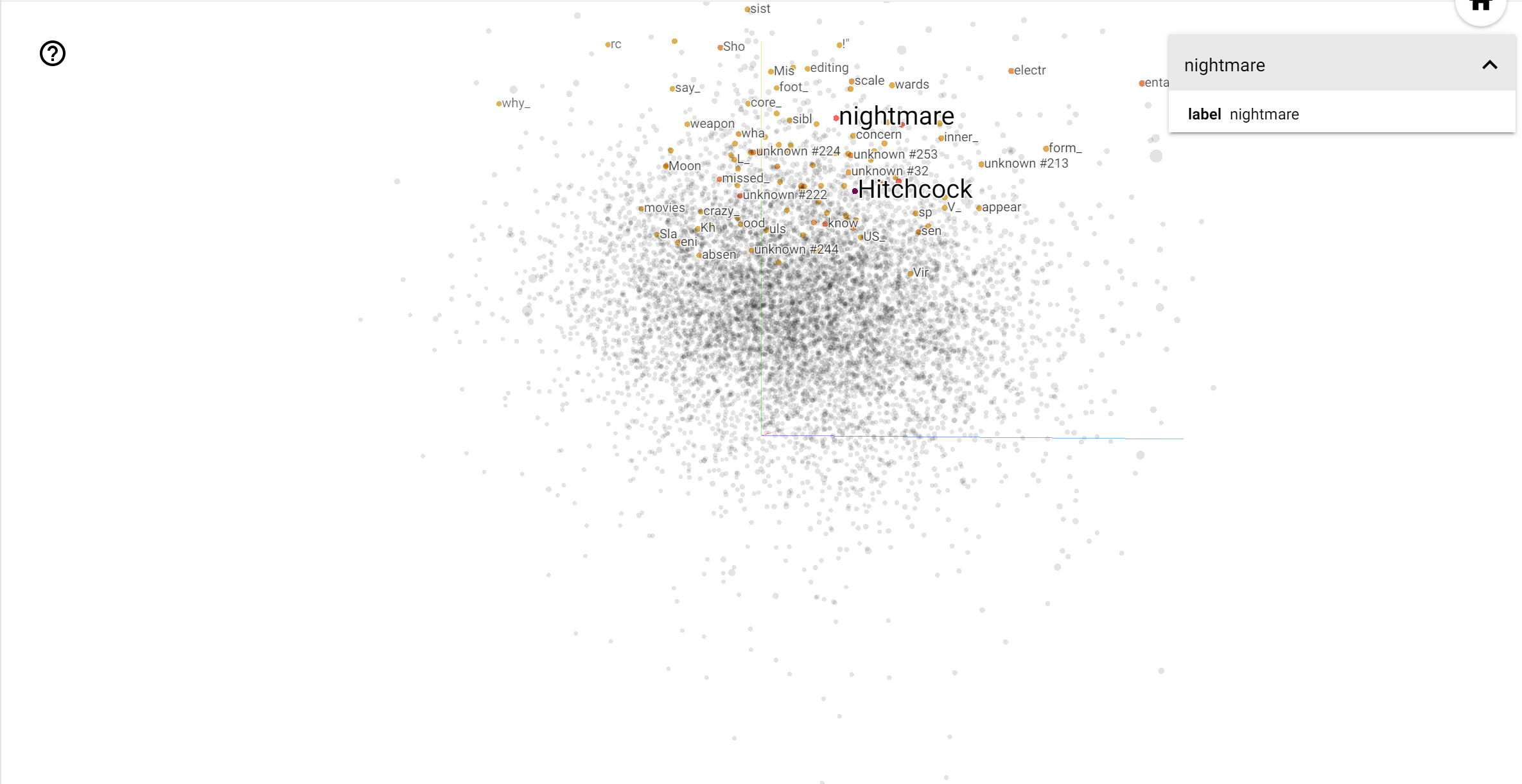
在這個空間中,Hitchcock 更接近 nightmare 之類的單字,這可能是因為他被稱為「懸疑大師」,而 Anderson 更接近 heart 這個單字,這與他堅持不懈的細緻和溫馨風格一致。