
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
在建構機器學習模型時,您需要選擇各種超參數,例如層中的 dropout 率或學習率。這些決策會影響模型指標,例如準確度。因此,機器學習工作流程中的一個重要步驟是找出最適合您問題的超參數,這通常需要實驗。此程序稱為「超參數最佳化」或「超參數調整」。
TensorBoard 中的 HParams 儀表板提供多種工具,可協助您找出最佳實驗或最有前景的超參數組合。
本教學課程將著重於下列步驟
- 實驗設定和 HParams 摘要
- 調整 TensorFlow 執行以記錄超參數和指標
- 啟動執行並將所有執行記錄在一個父目錄下
- 在 TensorBoard 的 HParams 儀表板中視覺化結果
首先安裝 TF 2.0 並載入 TensorBoard 筆記本擴充功能
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
匯入 TensorFlow 和 TensorBoard HParams 外掛程式
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
下載 FashionMNIST 資料集並縮放
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. 實驗設定和 HParams 實驗摘要
在模型中實驗三個超參數
- 第一個密集層中的單位數
- dropout 層中的 Dropout 率
- 最佳化工具
列出要嘗試的值,並將實驗設定記錄到 TensorBoard。此步驟為選用步驟:您可以提供網域資訊,以便在 UI 中更精確地篩選超參數,而且您可以指定應顯示哪些指標。
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
如果您選擇略過此步驟,則可以在您通常會使用 HParam 值的地方使用字串常值:例如,hparams['dropout'] 而不是 hparams[HP_DROPOUT]。
2. 調整 TensorFlow 執行以記錄超參數和指標
模型將非常簡單:兩個密集層,中間有一個 dropout 層。訓練程式碼看起來很熟悉,雖然超參數不再是硬式編碼。相反地,超參數是在 hparams 字典中提供,並在整個訓練函式中使用
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
針對每次執行,記錄包含超參數和最終準確度的 hparams 摘要
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
在訓練 Keras 模型時,您可以使用回呼,而不是直接撰寫這些程式碼
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. 啟動執行並將所有執行記錄在一個父目錄下
您現在可以嘗試多個實驗,針對每個實驗使用一組不同的超參數。
為了簡化,請使用網格搜尋:嘗試離散參數的所有組合,以及實值參數的下限和上限。針對更複雜的情境,隨機選擇每個超參數值可能更有效率 (這稱為隨機搜尋)。還有更多進階方法可以使用。
執行幾個實驗,這需要幾分鐘的時間
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. 在 TensorBoard 的 HParams 外掛程式中視覺化結果
現在可以開啟 HParams 儀表板。啟動 TensorBoard 並按一下頂端的「HParams」。
%tensorboard --logdir logs/hparam_tuning
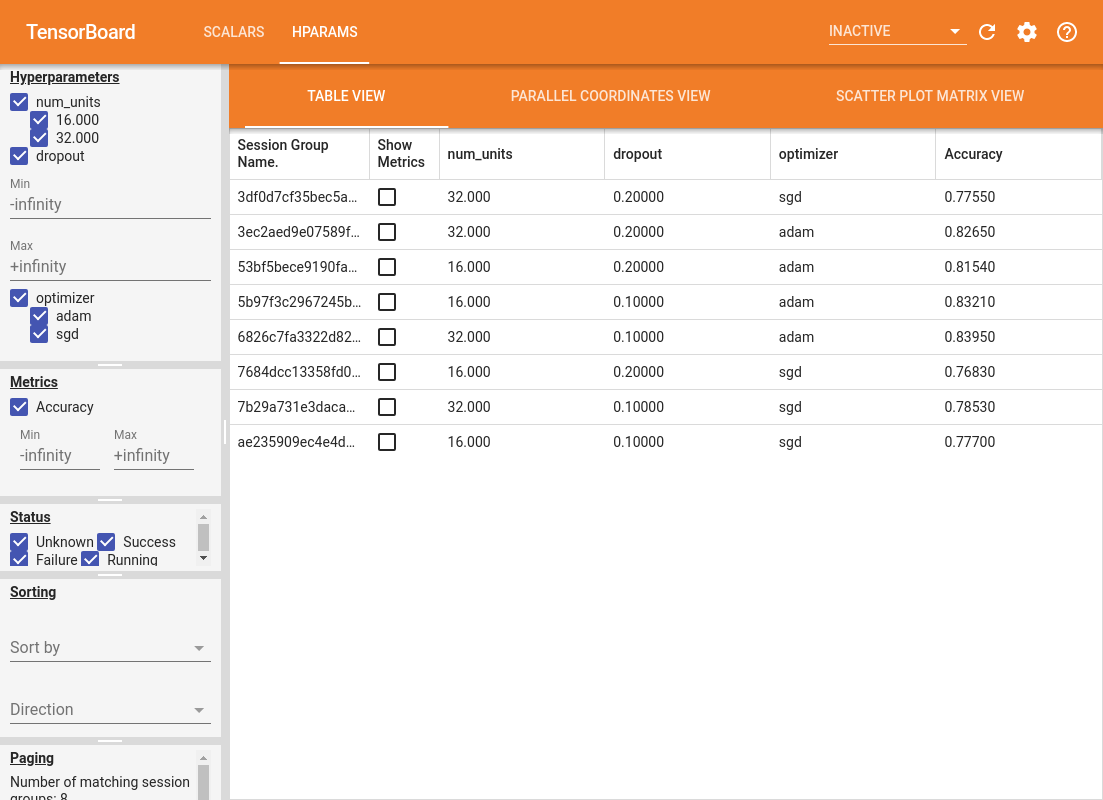
儀表板的左側窗格提供篩選功能,這些功能在 HParams 儀表板的所有檢視畫面中都是有效的
- 篩選儀表板中顯示的超參數/指標
- 篩選儀表板中顯示的超參數/指標值
- 依執行狀態 (執行中、成功...) 篩選
- 在表格檢視中依超參數/指標排序
- 要顯示的工作階段群組數量 (當實驗很多時,適用於效能)
HParams 儀表板有三個不同的檢視畫面,其中包含各種實用資訊
- 表格檢視畫面會列出執行、其超參數和其指標。
- 平行座標檢視畫面會將每次執行顯示為一條線,該線穿過每個超參數和指標的軸。在任何軸上按一下並拖曳滑鼠以標記一個區域,這樣只會醒目顯示通過該區域的執行。這對於識別哪些超參數群組最重要很有用。軸本身可以透過拖曳來重新排序。
- 散佈圖檢視畫面會顯示比較每個超參數/指標與每個指標的圖表。這有助於識別關聯性。按一下並拖曳以選取特定圖表中的區域,並醒目顯示其他圖表中的這些工作階段。
可以按一下表格列、平行座標線和散佈圖標記,以查看指標作為該工作階段訓練步驟函數的圖表 (雖然在本教學課程中,每次執行只使用一個步驟)。
若要進一步探索 HParams 儀表板的功能,請下載一組預先產生的記錄,其中包含更多實驗
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
在 TensorBoard 中檢視這些記錄
%tensorboard --logdir logs/hparam_demo
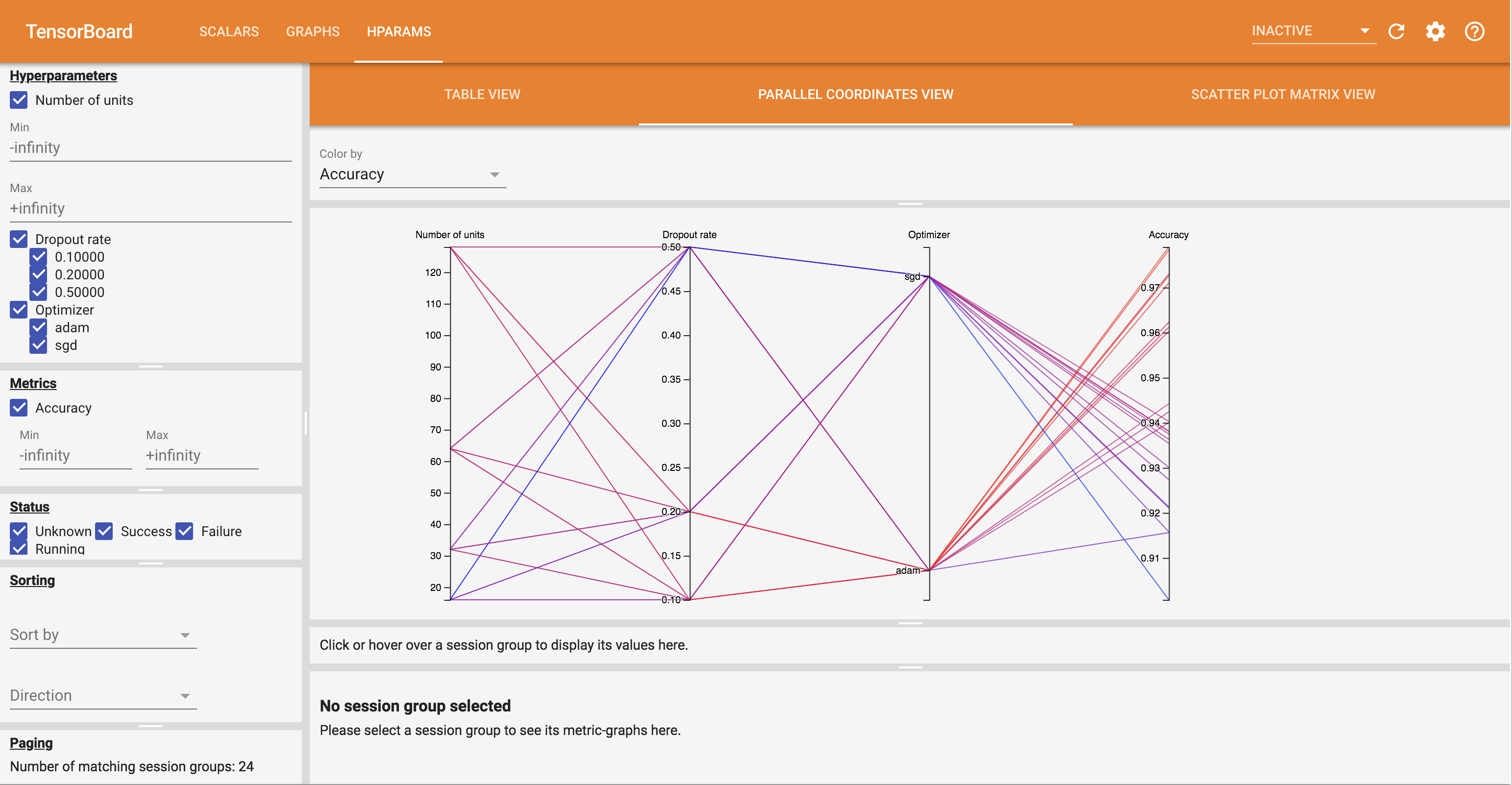
您可以試用 HParams 儀表板中的不同檢視畫面。
例如,透過前往平行座標檢視畫面並按一下並拖曳準確度軸,您可以選取準確度最高的執行。由於這些執行通過最佳化工具軸中的「adam」,您可以得出結論,「adam」在這些實驗中的效能優於「sgd」。