
總覽
TensorBoard 的主要功能是其互動式 GUI。然而,使用者有時會想要以程式設計方式讀取儲存在 TensorBoard 中的資料記錄,以進行事後分析和建立記錄資料的自訂視覺化等用途。
TensorBoard 2.3 透過 tensorboard.data.experimental.ExperimentFromDev() 支援此使用案例。它允許以程式設計方式存取 TensorBoard 的純量記錄。本頁面示範此新 API 的基本用法。
設定
為了使用程式設計 API,請務必一併安裝 pandas 和 tensorboard。
在本指南中,我們會使用 matplotlib 和 seaborn 進行自訂繪圖,但您可以選擇偏好的工具來分析和視覺化 DataFrame。
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
將 TensorBoard 純量載入為 pandas.DataFrame
一旦 TensorBoard logdir 上傳至 TensorBoard.dev,它就會變成我們所稱的實驗。每個實驗都有一個唯一的 ID,可以在實驗的 TensorBoard.dev URL 中找到。在以下示範中,我們將使用位於以下網址的 TensorBoard.dev 實驗:https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df 是一個 pandas.DataFrame,其中包含實驗的所有純量記錄。
DataFrame 的欄是
run:每個執行項目對應於原始 logdir 的子目錄。在本實驗中,每個執行項目都來自 MNIST 資料集上卷積神經網路 (CNN) 的完整訓練,並具有給定的最佳化工具類型 (訓練超參數)。此DataFrame包含多個這類執行項目,這些執行項目對應於不同最佳化工具類型下的重複訓練執行。tag:這描述了同一列中的value代表什麼,也就是說,該值代表該列中的哪個指標。在本實驗中,我們只有兩個獨特的標記:epoch_accuracy和epoch_loss,分別代表準確度和損失指標。step:這是一個數字,反映了執行項目中對應列的序列順序。此處的step實際上是指週期編號。如果您希望除了step值之外還取得時間戳記,您可以在呼叫get_scalars()時使用關鍵字引數include_wall_time=True。value:這是實際感興趣的數值。如上所述,此特定DataFrame中的每個value都是損失或準確度,具體取決於列的tag。
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
取得樞紐分析 (寬格式) DataFrame
在我們的實驗中,兩個標記 (epoch_loss 和 epoch_accuracy) 出現在每個執行項目的相同步驟集中。這使得可以使用 pivot=True 關鍵字引數直接從 get_scalars() 取得「寬格式」DataFrame。寬格式 DataFrame 將其所有標記都包含為 DataFrame 的欄,在某些情況下 (包括此情況) 使用起來更方便。
但是,請注意,如果所有執行項目中所有標記的步驟值均勻集條件未滿足,則使用 pivot=True 將導致錯誤。
dfw = experiment.get_scalars(pivot=True)
dfw
請注意,寬格式 DataFrame 不包含單一「value」欄,而是明確包含兩個標記 (指標) 作為其欄:epoch_accuracy 和 epoch_loss。
將 DataFrame 儲存為 CSV
pandas.DataFrame 與 CSV 具有良好的互通性。您可以將其儲存為本機 CSV 檔案,並稍後重新載入。例如
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
執行自訂視覺化和統計分析
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
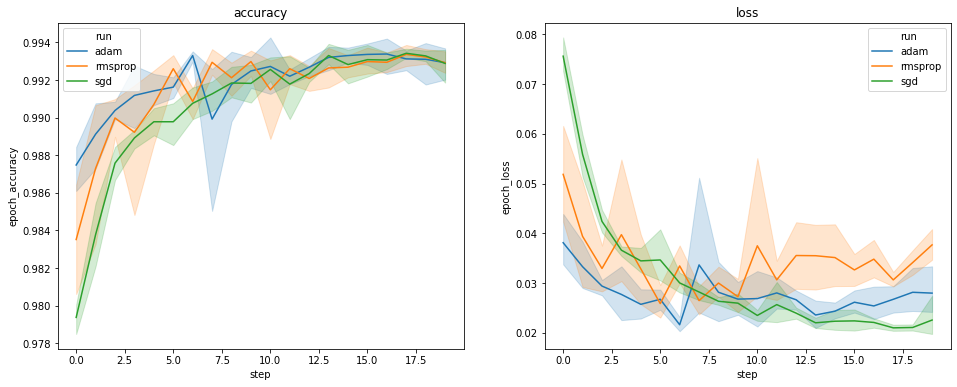
以上繪圖顯示了驗證準確度和驗證損失的時程。每條曲線顯示了某種最佳化工具類型下 5 個執行項目的平均值。由於 seaborn.lineplot() 的內建功能,每條曲線還會顯示平均值周圍 ±1 個標準差,這讓我們清楚瞭解這些曲線的變異性以及三種最佳化工具類型之間差異的顯著性。TensorBoard 的 GUI 尚不支援這種變異性視覺化。
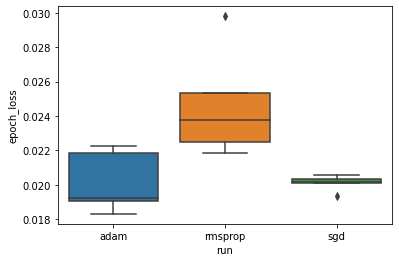
我們想要研究「adam」、「rmsprop」和「sgd」最佳化工具之間的最小驗證損失是否存在顯著差異的假設。因此,我們為每種最佳化工具下的最小驗證損失擷取一個 DataFrame。
然後,我們製作箱形圖,以視覺化最小驗證損失的差異。
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
因此,在 0.05 的顯著性水準下,我們的分析證實了我們的假設,即與我們實驗中包含的其他兩種最佳化工具相比,rmsprop 最佳化工具中的最小驗證損失顯著更高 (即更差)。
總之,本教學課程提供了一個範例,說明如何從 TensorBoard.dev 以 panda.DataFrame 的形式存取純量資料。它示範了您可以使用 DataFrame 進行的彈性且強大的分析和視覺化類型。