
涉及 NaN 的災難性事件有時會在 TensorFlow 程式執行期間發生,嚴重影響模型訓練流程。這類事件的根本原因通常難以捉摸,對於規模和複雜度不小的模型而言尤其如此。為了更輕鬆地偵錯這類型的模型錯誤,TensorBoard 2.3+(搭配 TensorFlow 2.3+)提供了一個名為 Debugger V2 的專用儀表板。在這裡,我們將示範如何使用這個工具,逐步解決一個真實的錯誤,該錯誤涉及以 TensorFlow 撰寫的神經網路中的 NaN。
本教學課程中說明的技巧適用於其他類型的偵錯活動,例如在複雜程式中檢查執行階段張量形狀。本教學課程著重於 NaN,因為它們的發生頻率相對較高。
觀察錯誤
我們將偵錯的 TF2 程式碼原始碼可在 GitHub 上取得。範例程式也已封裝至 tensorflow pip 套件(2.3+ 版),可透過以下方式叫用
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
這個 TF2 程式會建立一個多層感知器 (MLP),並訓練它來辨識 MNIST 圖片。這個範例刻意使用 TF2 的低階 API 來定義自訂層級結構、損失函數和訓練迴圈,因為當我們使用這個更彈性但更容易出錯的 API 時,NaN 錯誤的可能性會高於使用更易於使用但彈性稍低的 tf.keras 等高階 API 時。
程式會在每個訓練步驟後印出測試準確度。我們可以在主控台中看到,測試準確度在第一個步驟後停滯在接近隨機水準 (~0.1)。這當然不是模型訓練預期的行為:我們預期準確度會隨著步驟增加而逐漸接近 1.0 (100%)。
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
合理的猜測是,這個問題是由數值不穩定性所引起,例如 NaN 或無限大。然而,我們如何確認這確實是事實,又該如何找出負責產生數值不穩定性的 TensorFlow 運算 (op)?為了回答這些問題,讓我們使用 Debugger V2 來檢測這個有錯誤的程式。
使用 Debugger V2 檢測 TensorFlow 程式碼
tf.debugging.experimental.enable_dump_debug_info() 是 Debugger V2 的 API 進入點。它可以使用單行程式碼來檢測 TF2 程式。例如,在程式碼開頭附近加入以下程式碼行,會將偵錯資訊寫入 /tmp/tfdbg2_logdir 的記錄目錄 (logdir)。偵錯資訊涵蓋 TensorFlow 執行階段的各個層面。在 TF2 中,它包含 eager execution 的完整歷史記錄、@tf.function 執行的圖表建構、圖表的執行、執行事件產生的張量值,以及這些事件的程式碼位置 (Python 堆疊追蹤)。偵錯資訊的豐富性讓使用者能夠縮小範圍,找出難以捉摸的錯誤。
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
tensor_debug_mode 引數控制 Debugger V2 從每個 eager 或圖表內張量中擷取的資訊。「FULL_HEALTH」是一種模式,可擷取每個浮點類型張量的以下資訊(例如,常見的 float32 和較不常見的 bfloat16 dtype)
- DType
- 階數
- 元素總數
- 將浮點類型元素細分為以下類別:負有限 (
-)、零 (0)、正有限 (+)、負無限大 (-∞)、正無限大 (+∞) 和NaN。
「FULL_HEALTH」模式適用於偵錯涉及 NaN 和無限大的錯誤。請參閱下方以瞭解其他支援的 tensor_debug_mode。
circular_buffer_size 引數控制要儲存到記錄目錄的張量事件數量。預設值為 1000,這會導致只將檢測 TF2 程式結束前的最後 1000 個張量儲存到磁碟。這個預設行為會犧牲偵錯資料完整性,以減少偵錯工具額外負荷。如果偏好完整性(如此案例所示),我們可以將引數設定為負值(例如,此處的 -1)來停用循環緩衝區。
debug_mnist_v2 範例會透過將命令列旗標傳遞給 enable_dump_debug_info() 來叫用它。若要再次執行我們有問題的 TF2 程式並啟用這個偵錯檢測功能,請執行
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
在 TensorBoard 中啟動 Debugger V2 GUI
執行具有偵錯工具檢測功能的程式會在 /tmp/tfdbg2_logdir 建立記錄目錄。我們可以啟動 TensorBoard,並使用以下指令將其指向記錄目錄
tensorboard --logdir /tmp/tfdbg2_logdir
在網頁瀏覽器中,瀏覽至 TensorBoard 的頁面,網址為 http://localhost:6006。「Debugger V2」外掛程式預設會處於停用狀態,因此請從右上角的「停用的外掛程式」選單中選取它。選取後,它應該看起來像這樣
使用 Debugger V2 GUI 找出 NaN 的根本原因
TensorBoard 中的 Debugger V2 GUI 分為六個區段
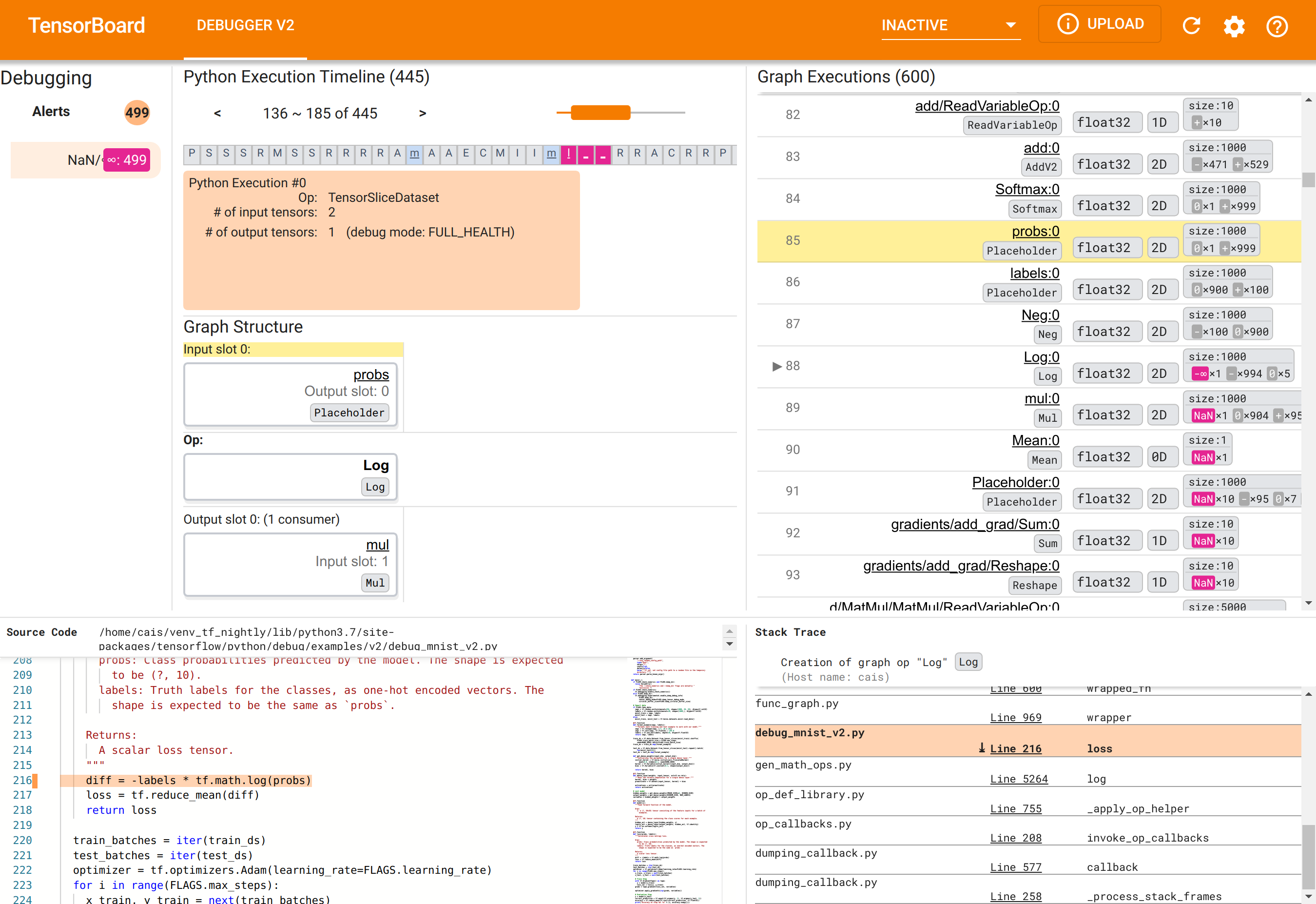
- 警示:這個左上角區段包含偵錯工具在來自檢測 TensorFlow 程式的偵錯資料中偵測到的「警示」事件清單。每個警示都指出某種異常情況,值得注意。在我們的案例中,這個區段以顯眼的粉紅色-紅色醒目提示了 499 個 NaN/∞ 事件。這證實了我們的懷疑,模型無法學習是因為其內部張量值中存在 NaN 和/或無限大。我們稍後將深入探討這些警示。
- Python 執行時間軸:這是中間上方區段的上半部分。它呈現了運算和圖表的 eager execution 的完整歷史記錄。時間軸的每個方塊都標示了運算或圖表名稱的首字母(例如,「TensorSliceDataset」運算的「T」,「model」
tf.function的「m」)。我們可以透過使用時間軸上方的導覽按鈕和捲軸來瀏覽這個時間軸。 - 圖表執行:這個區段位於 GUI 的右上角,將是我們偵錯任務的中心。它包含在圖表內計算的所有浮點 dtype 張量的歷史記錄(也就是由
@tf-function編譯的)。 - 圖表結構(中間上方區段的下半部分)、原始碼(左下角區段)和 堆疊追蹤(右下角區段)最初都是空的。當我們與 GUI 互動時,它們的內容將會填入。這三個區段也將在我們的偵錯任務中扮演重要角色。
在我們熟悉 UI 的組織方式後,讓我們採取以下步驟來探究 NaN 出現的根本原因。首先,按一下「警示」區段中的 NaN/∞ 警示。這會自動捲動「圖表執行」區段中 600 個圖表張量的清單,並將焦點放在 #88,這是一個名為 Log:0 的張量,由 Log(自然對數)運算產生。顯眼的粉紅色-紅色醒目提示了 2D float32 張量的 1000 個元素中的一個 -∞ 元素。這是 TF2 程式執行階段歷史記錄中第一個包含任何 NaN 或無限大的張量:在此之前計算的張量不包含 NaN 或 ∞;之後計算的許多(實際上是大多數)張量都包含 NaN。我們可以透過上下捲動「圖表執行」清單來確認這一點。這個觀察結果強烈暗示 Log 運算是這個 TF2 程式中數值不穩定性的來源。
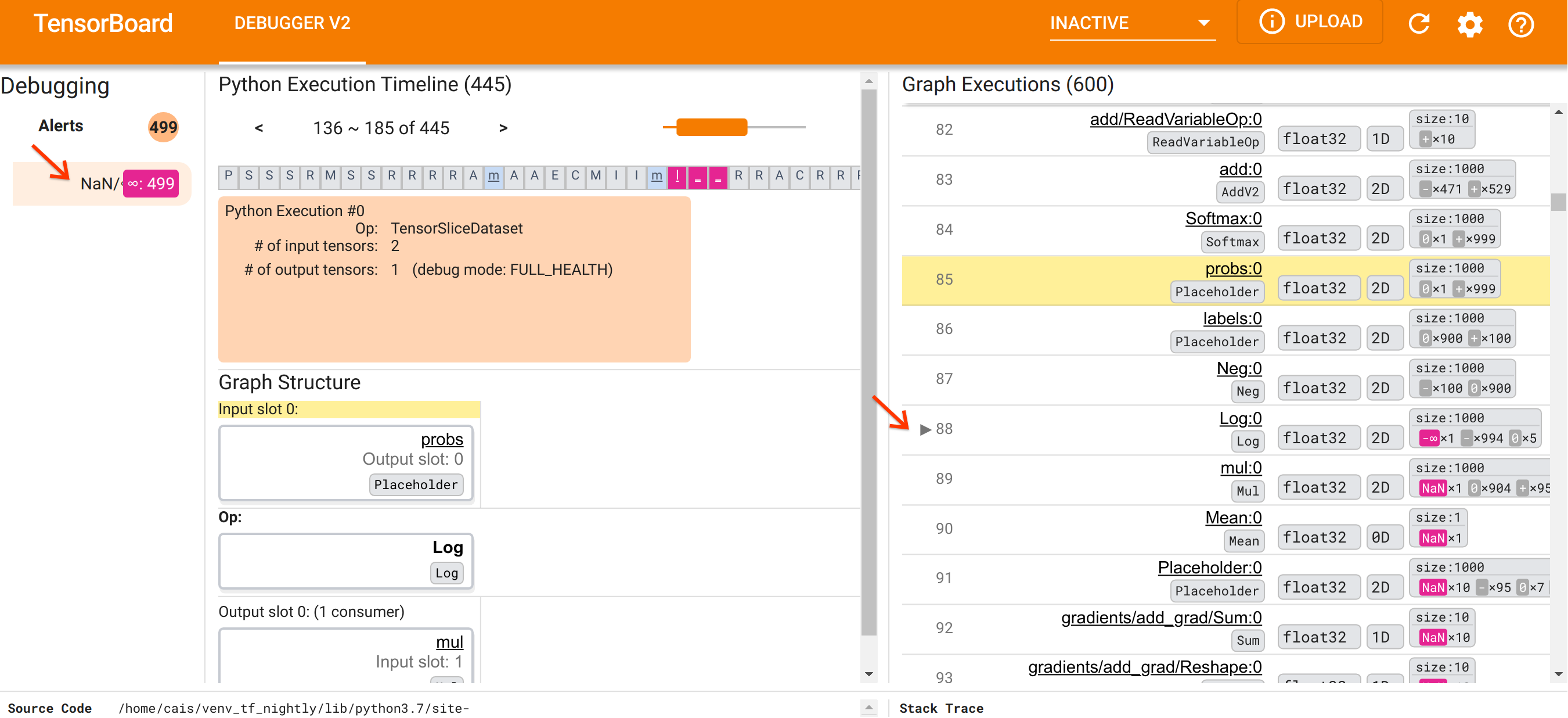
為什麼這個 Log 運算會吐出 -∞?回答這個問題需要檢查運算的輸入。按一下張量的名稱 (Log:0) 會在「圖表結構」區段中顯示 Log 運算在其 TensorFlow 圖表中的鄰近區域的簡單但資訊豐富的可視化。請注意資訊流的由上而下方向。運算本身以粗體顯示在中間。緊接在其上方,我們可以看見 Placeholder 運算提供 Log 運算的唯一輸入。這個 probs Placeholder 產生的張量在哪裡?在「圖表執行」清單中嗎?透過使用黃色背景顏色作為視覺輔助,我們可以看見 probs:0 張量在 Log:0 張量上方三列,也就是在第 85 列。
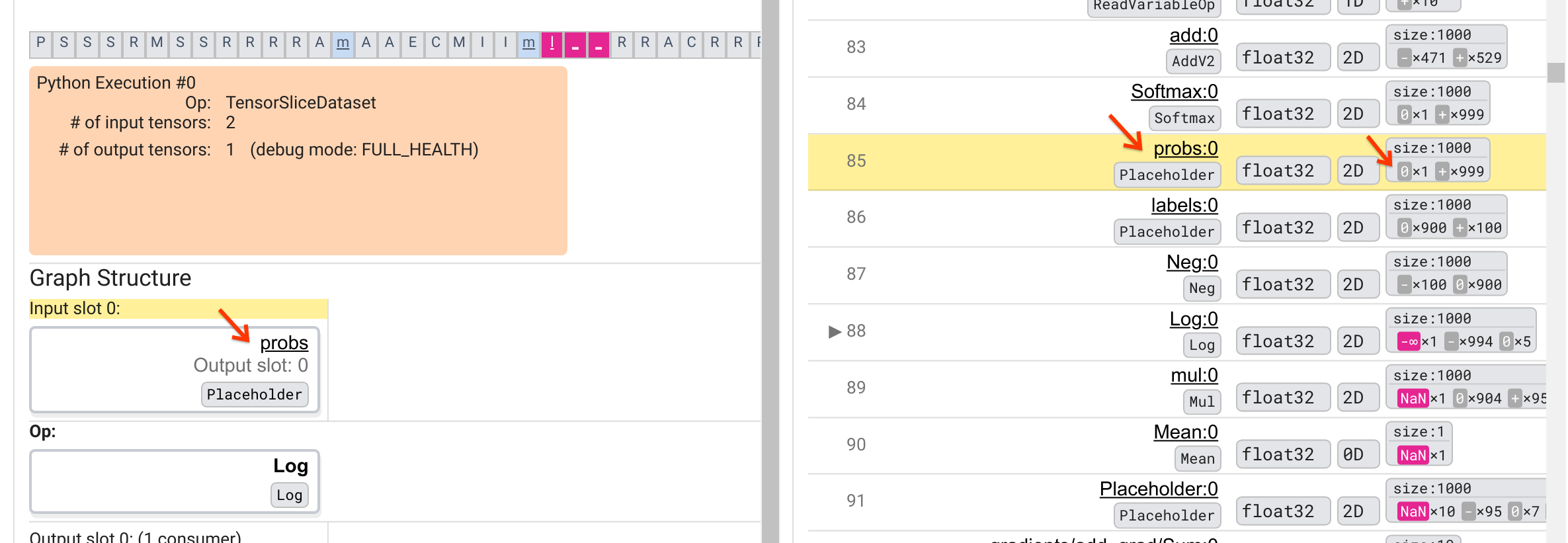
更仔細地查看第 85 列中 probs:0 張量的數值細分,揭示了為何其消費者 Log:0 會產生 -∞:在 probs:0 的 1000 個元素中,有一個元素的值為 0。-∞ 是計算 0 的自然對數的結果!如果我們能夠以某種方式確保 Log 運算只接觸到正輸入,我們就能夠防止 NaN/∞ 的發生。這可以透過對 Placeholder probs 張量套用裁剪(例如,使用 tf.clip_by_value())來達成。
我們越來越接近解決這個錯誤,但尚未完全完成。為了套用修正程式,我們需要知道 Log 運算及其 Placeholder 輸入的原始碼位於 Python 原始碼中的哪個位置。Debugger V2 提供一流的支援,可將圖表運算和執行事件追蹤到其來源。當我們在「圖表執行」中按一下 Log:0 張量時,「堆疊追蹤」區段會填入 Log 運算建立的原始堆疊追蹤。堆疊追蹤有點大,因為它包含來自 TensorFlow 內部程式碼的許多框架(例如,gen_math_ops.py 和 dumping_callback.py),對於大多數偵錯任務,我們可以安全地忽略這些框架。我們感興趣的框架是 debug_mnist_v2.py 的第 216 行(也就是我們實際嘗試偵錯的 Python 檔案)。按一下「第 216 行」會顯示「原始碼」區段中對應的程式碼行檢視。
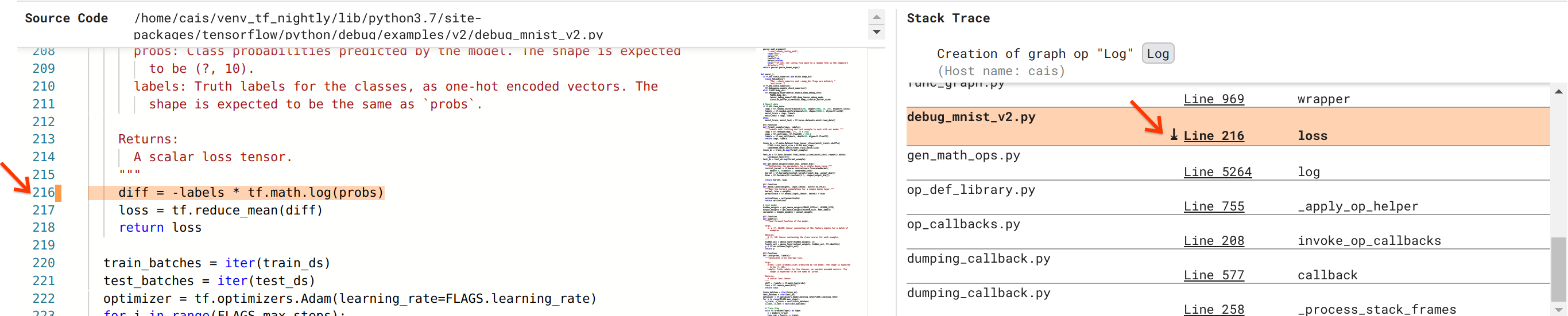
這終於將我們帶到從其 probs 輸入建立有問題的 Log 運算的原始碼。這是我們使用 @tf.function 裝飾的自訂類別交叉熵損失函數,因此已轉換為 TensorFlow 圖表。Placeholder 運算 probs 對應於損失函數的第一個輸入引數。Log 運算是使用 tf.math.log() API 呼叫建立的。
這個錯誤的值裁剪修正程式看起來會像這樣
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
它將解決這個 TF2 程式中的數值不穩定性,並使 MLP 能夠成功訓練。另一種修正數值不穩定性的可能方法是使用 tf.keras.losses.CategoricalCrossentropy。
這結束了我們的旅程,從觀察 TF2 模型錯誤到提出可修正錯誤的程式碼變更,Debugger V2 工具在此過程中提供了協助,它提供了對檢測 TF2 程式的 eager 和圖表執行歷史記錄的完整可見性,包括張量值的數值摘要以及運算、張量及其原始碼之間的關聯性。
Debugger V2 的硬體相容性
Debugger V2 支援主流訓練硬體,包括 CPU 和 GPU。也支援使用 tf.distributed.MirroredStrategy 的多 GPU 訓練。對 TPU 的支援仍處於早期階段,需要呼叫
tf.config.set_soft_device_placement(True)
然後再呼叫 enable_dump_debug_info()。它在 TPU 上可能也有其他限制。如果您在使用 Debugger V2 時遇到問題,請在我們的 GitHub 問題頁面上回報錯誤。
Debugger V2 的 API 相容性
Debugger V2 是在 TensorFlow 軟體堆疊的相對低階層實作的,因此與 tf.keras、tf.data 以及其他建構於 TensorFlow 低階層之上的 API 相容。Debugger V2 也與 TF1 向後相容,但對於 TF1 程式產生的偵錯記錄目錄,Eager Execution Timeline 將會是空的。
API 使用秘訣
關於這個偵錯 API 的常見問題是,應該在 TensorFlow 程式碼中的哪個位置插入 enable_dump_debug_info() 的呼叫。通常,API 應該盡可能在 TF2 程式中盡早呼叫,最好是在 Python 匯入行之後,以及在圖表建構和執行開始之前。這將確保完整涵蓋所有支援您的模型及其訓練的運算和圖表。
目前支援的 tensor_debug_mode 為:NO_TENSOR、CURT_HEALTH、CONCISE_HEALTH、FULL_HEALTH 和 SHAPE。它們在從每個張量擷取的資訊量和偵錯程式的效能額外負荷方面有所不同。請參閱 enable_dump_debug_info() 文件的args 區段。
效能額外負荷
偵錯 API 會對檢測 TensorFlow 程式造成效能額外負荷。額外負荷因 tensor_debug_mode、硬體類型和檢測 TensorFlow 程式的性質而異。作為參考點,在 GPU 上,NO_TENSOR 模式在批次大小為 64 的 Transformer 模型訓練期間會增加 15% 的額外負荷。其他 tensor_debug_mode 的百分比額外負荷更高:CURT_HEALTH、CONCISE_HEALTH、FULL_HEALTH 和 SHAPE 模式約為 50%。在 CPU 上,額外負荷略低。在 TPU 上,額外負荷目前較高。
與其他 TensorFlow 偵錯 API 的關係
請注意,TensorFlow 提供了其他工具和 API 來進行偵錯。您可以在 API 文件頁面的 tf.debugging.* namespace命名空間下瀏覽這類 API。在這些 API 中,最常使用的是 tf.print()。何時應該使用 Debugger V2?何時應該改用 tf.print()?在以下情況下,tf.print() 很方便
- 我們確切知道要印出哪些張量
- 我們確切知道在原始碼中的哪個位置插入這些
tf.print()陳述式 - 這類張量的數量不會太大。
對於其他情況(例如,檢查許多張量值、檢查 TensorFlow 內部程式碼產生的張量值,以及搜尋數值不穩定性的根源,如我們在上面所示範的),Debugger V2 提供了一種更快速的偵錯方式。此外,Debugger V2 提供了一種統一的方法來檢查 eager 和圖表張量。它還額外提供有關圖表結構和程式碼位置的資訊,這些資訊是 tf.print() 無法提供的。
另一個可用於偵錯涉及 ∞ 和 NaN 問題的 API 是 tf.debugging.enable_check_numerics()。與 enable_dump_debug_info() 不同,enable_check_numerics() 不會將偵錯資訊儲存到磁碟。相反地,它只會在 TensorFlow 執行階段監控 ∞ 和 NaN,並在任何運算產生這類不良數值時立即錯誤跳出,並顯示原始碼位置。與 enable_dump_debug_info() 相比,它的效能額外負荷較低,但無法提供程式執行歷史記錄的完整追蹤,也沒有像 Debugger V2 那樣的圖形使用者介面。