|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
學習目標
TensorFlow Models NLP 程式庫是建構及訓練現代高效能自然語言模型的一系列工具。
tfm.nlp.networks.EncoderScaffold 是此程式庫的核心,並且已提出許多新的網路架構來改善編碼器。在本 Colab 筆記本中,我們將學習如何自訂編碼器以採用新的網路架構。
安裝與匯入
安裝 TensorFlow Model Garden pip 套件
tf-models-official是穩定的 Model Garden 套件。請注意,其中可能不包含tensorflow_modelsgithub 存放區中的最新變更。若要包含最新變更,您可以安裝tf-models-nightly,這是每日自動建立的每夜 Model Garden 套件。pip將自動安裝所有模型和依附元件。
pip install -q opencv-python
pip install -q tf-models-official
匯入 Tensorflow 和其他程式庫
import numpy as np
import tensorflow as tf
import tensorflow_models as tfm
nlp = tfm.nlp
2023-12-14 12:09:32.926415: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-12-14 12:09:32.926462: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-12-14 12:09:32.927992: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
標準 BERT 編碼器
在學習如何自訂編碼器之前,我們先建立標準 BERT 編碼器,並使用它來例項化分類任務的 bert_classifier.BertClassifier。
cfg = {
"vocab_size": 100,
"hidden_size": 32,
"num_layers": 3,
"num_attention_heads": 4,
"intermediate_size": 64,
"activation": tfm.utils.activations.gelu,
"dropout_rate": 0.1,
"attention_dropout_rate": 0.1,
"max_sequence_length": 16,
"type_vocab_size": 2,
"initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02),
}
bert_encoder = nlp.networks.BertEncoder(**cfg)
def build_classifier(bert_encoder):
return nlp.models.BertClassifier(bert_encoder, num_classes=2)
canonical_classifier_model = build_classifier(bert_encoder)
可以使用訓練資料來訓練 canonical_classifier_model。如需如何訓練模型的詳細資訊,請參閱微調 bert 筆記本。我們在此省略訓練模型的程式碼。
訓練完成後,我們可以套用模型進行預測。
def predict(model):
batch_size = 3
np.random.seed(0)
word_ids = np.random.randint(
cfg["vocab_size"], size=(batch_size, cfg["max_sequence_length"]))
mask = np.random.randint(2, size=(batch_size, cfg["max_sequence_length"]))
type_ids = np.random.randint(
cfg["type_vocab_size"], size=(batch_size, cfg["max_sequence_length"]))
print(model([word_ids, mask, type_ids], training=False))
predict(canonical_classifier_model)
tf.Tensor( [[ 0.03545166 0.30729884] [ 0.00677404 0.17251147] [-0.07276718 0.17345032]], shape=(3, 2), dtype=float32)
自訂 BERT 編碼器
一個 BERT 編碼器包含一個嵌入網路和多個 transformer 區塊,而每個 transformer 區塊都包含一個注意力層和一個前饋層。
我們提供透過 (1) EncoderScaffold 和 (2) TransformerScaffold 自訂這些元件中每一個的簡易方法。
使用 EncoderScaffold
networks.EncoderScaffold 允許使用者提供自訂嵌入子網路 (將取代標準嵌入邏輯) 和/或自訂隱藏層類別 (將取代編碼器中的 Transformer 例項化)。
不自訂
在不進行任何自訂的情況下,networks.EncoderScaffold 的行為與標準 networks.BertEncoder 相同。
如下列範例所示,networks.EncoderScaffold 可以載入 networks.BertEncoder 的權重並輸出相同的值
default_hidden_cfg = dict(
num_attention_heads=cfg["num_attention_heads"],
intermediate_size=cfg["intermediate_size"],
intermediate_activation=cfg["activation"],
dropout_rate=cfg["dropout_rate"],
attention_dropout_rate=cfg["attention_dropout_rate"],
kernel_initializer=cfg["initializer"],
)
default_embedding_cfg = dict(
vocab_size=cfg["vocab_size"],
type_vocab_size=cfg["type_vocab_size"],
hidden_size=cfg["hidden_size"],
initializer=cfg["initializer"],
dropout_rate=cfg["dropout_rate"],
max_seq_length=cfg["max_sequence_length"]
)
default_kwargs = dict(
hidden_cfg=default_hidden_cfg,
embedding_cfg=default_embedding_cfg,
num_hidden_instances=cfg["num_layers"],
pooled_output_dim=cfg["hidden_size"],
return_all_layer_outputs=True,
pooler_layer_initializer=cfg["initializer"],
)
encoder_scaffold = nlp.networks.EncoderScaffold(**default_kwargs)
classifier_model_from_encoder_scaffold = build_classifier(encoder_scaffold)
classifier_model_from_encoder_scaffold.set_weights(
canonical_classifier_model.get_weights())
predict(classifier_model_from_encoder_scaffold)
WARNING:absl:The `Transformer` layer is deprecated. Please directly use `TransformerEncoderBlock`. WARNING:absl:The `Transformer` layer is deprecated. Please directly use `TransformerEncoderBlock`. WARNING:absl:The `Transformer` layer is deprecated. Please directly use `TransformerEncoderBlock`. tf.Tensor( [[ 0.03545166 0.30729884] [ 0.00677404 0.17251147] [-0.07276718 0.17345032]], shape=(3, 2), dtype=float32)
自訂嵌入
接下來,我們示範如何使用自訂嵌入網路。
我們先建構一個將取代預設網路的嵌入網路。這個網路將有 2 個輸入 (mask 和 word_ids) 而非 3 個,並且不會使用位置嵌入。
word_ids = tf.keras.layers.Input(
shape=(cfg['max_sequence_length'],), dtype=tf.int32, name="input_word_ids")
mask = tf.keras.layers.Input(
shape=(cfg['max_sequence_length'],), dtype=tf.int32, name="input_mask")
embedding_layer = nlp.layers.OnDeviceEmbedding(
vocab_size=cfg['vocab_size'],
embedding_width=cfg['hidden_size'],
initializer=cfg["initializer"],
name="word_embeddings")
word_embeddings = embedding_layer(word_ids)
attention_mask = nlp.layers.SelfAttentionMask()([word_embeddings, mask])
new_embedding_network = tf.keras.Model([word_ids, mask],
[word_embeddings, attention_mask])
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/initializers/initializers.py:120: UserWarning: The initializer TruncatedNormal is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once. warnings.warn(
檢查 new_embedding_network,我們可以看見它採用兩個輸入:input_word_ids 和 input_mask。
tf.keras.utils.plot_model(new_embedding_network, show_shapes=True, dpi=48)
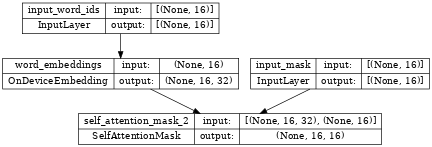
然後,我們可以使用上述 new_embedding_network 建構新的編碼器。
kwargs = dict(default_kwargs)
# Use new embedding network.
kwargs['embedding_cls'] = new_embedding_network
kwargs['embedding_data'] = embedding_layer.embeddings
encoder_with_customized_embedding = nlp.networks.EncoderScaffold(**kwargs)
classifier_model = build_classifier(encoder_with_customized_embedding)
# ... Train the model ...
print(classifier_model.inputs)
# Assert that there are only two inputs.
assert len(classifier_model.inputs) == 2
WARNING:absl:The `Transformer` layer is deprecated. Please directly use `TransformerEncoderBlock`. WARNING:absl:The `Transformer` layer is deprecated. Please directly use `TransformerEncoderBlock`. WARNING:absl:The `Transformer` layer is deprecated. Please directly use `TransformerEncoderBlock`. /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/initializers/initializers.py:120: UserWarning: The initializer TruncatedNormal is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once. warnings.warn( [<KerasTensor: shape=(None, 16) dtype=int32 (created by layer 'input_word_ids')>, <KerasTensor: shape=(None, 16) dtype=int32 (created by layer 'input_mask')>]
自訂 Transformer
使用者也可以覆寫 networks.EncoderScaffold 建構函式中的 hidden_cls 引數,以採用自訂 Transformer 層。
請參閱 nlp.layers.ReZeroTransformer 的原始碼,瞭解如何實作自訂 Transformer 層。
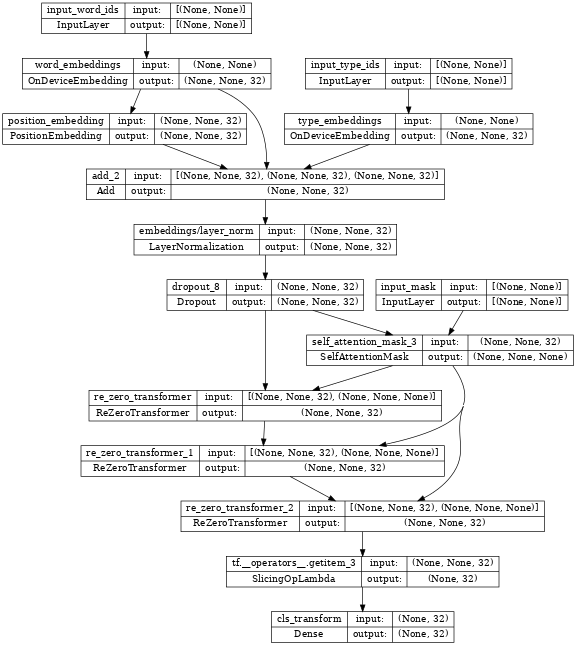
以下是使用 nlp.layers.ReZeroTransformer 的範例
kwargs = dict(default_kwargs)
# Use ReZeroTransformer.
kwargs['hidden_cls'] = nlp.layers.ReZeroTransformer
encoder_with_rezero_transformer = nlp.networks.EncoderScaffold(**kwargs)
classifier_model = build_classifier(encoder_with_rezero_transformer)
# ... Train the model ...
predict(classifier_model)
# Assert that the variable `rezero_alpha` from ReZeroTransformer exists.
assert 'rezero_alpha' in ''.join([x.name for x in classifier_model.trainable_weights])
tf.Tensor( [[-0.08663296 0.09281035] [-0.07291833 0.36477187] [-0.08730186 0.1503254 ]], shape=(3, 2), dtype=float32)
使用 nlp.layers.TransformerScaffold
上述自訂模型的方法需要重寫整個 nlp.layers.Transformer 層,但有時您可能只想自訂注意力層或前饋區塊。在這種情況下,可以使用 nlp.layers.TransformerScaffold。
自訂注意力層
使用者也可以覆寫 layers.TransformerScaffold 建構函式中的 attention_cls 引數,以採用自訂注意力層。
請參閱 nlp.layers.TalkingHeadsAttention 的原始碼,瞭解如何實作自訂 Attention 層。
以下是使用 nlp.layers.TalkingHeadsAttention 的範例
# Use TalkingHeadsAttention
hidden_cfg = dict(default_hidden_cfg)
hidden_cfg['attention_cls'] = nlp.layers.TalkingHeadsAttention
kwargs = dict(default_kwargs)
kwargs['hidden_cls'] = nlp.layers.TransformerScaffold
kwargs['hidden_cfg'] = hidden_cfg
encoder = nlp.networks.EncoderScaffold(**kwargs)
classifier_model = build_classifier(encoder)
# ... Train the model ...
predict(classifier_model)
# Assert that the variable `pre_softmax_weight` from TalkingHeadsAttention exists.
assert 'pre_softmax_weight' in ''.join([x.name for x in classifier_model.trainable_weights])
tf.Tensor( [[-0.20591784 0.09203205] [-0.0056177 -0.10278902] [-0.21681327 -0.12282 ]], shape=(3, 2), dtype=float32)
tf.keras.utils.plot_model(encoder_with_rezero_transformer, show_shapes=True, dpi=48)
自訂前饋層
同樣地,您也可以自訂前饋層。
請參閱 nlp.layers.GatedFeedforward 的原始碼,瞭解如何實作自訂前饋層。
以下是使用 nlp.layers.GatedFeedforward 的範例
# Use GatedFeedforward
hidden_cfg = dict(default_hidden_cfg)
hidden_cfg['feedforward_cls'] = nlp.layers.GatedFeedforward
kwargs = dict(default_kwargs)
kwargs['hidden_cls'] = nlp.layers.TransformerScaffold
kwargs['hidden_cfg'] = hidden_cfg
encoder_with_gated_feedforward = nlp.networks.EncoderScaffold(**kwargs)
classifier_model = build_classifier(encoder_with_gated_feedforward)
# ... Train the model ...
predict(classifier_model)
# Assert that the variable `gate` from GatedFeedforward exists.
assert 'gate' in ''.join([x.name for x in classifier_model.trainable_weights])
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/initializers/initializers.py:120: UserWarning: The initializer TruncatedNormal is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once. warnings.warn( tf.Tensor( [[-0.10270456 -0.10999684] [-0.03512481 0.15430304] [-0.23601504 -0.18162844]], shape=(3, 2), dtype=float32)
建構新的編碼器
最後,您也可以使用模型化程式庫中的建構區塊來建構新的編碼器。
請參閱 nlp.networks.AlbertEncoder 的原始碼,作為瞭解如何執行此操作的範例。
以下是使用 nlp.networks.AlbertEncoder 的範例
albert_encoder = nlp.networks.AlbertEncoder(**cfg)
classifier_model = build_classifier(albert_encoder)
# ... Train the model ...
predict(classifier_model)
tf.Tensor( [[-0.00369881 -0.2540995 ] [ 0.1235221 -0.2959229 ] [-0.08698564 -0.17653546]], shape=(3, 2), dtype=float32)
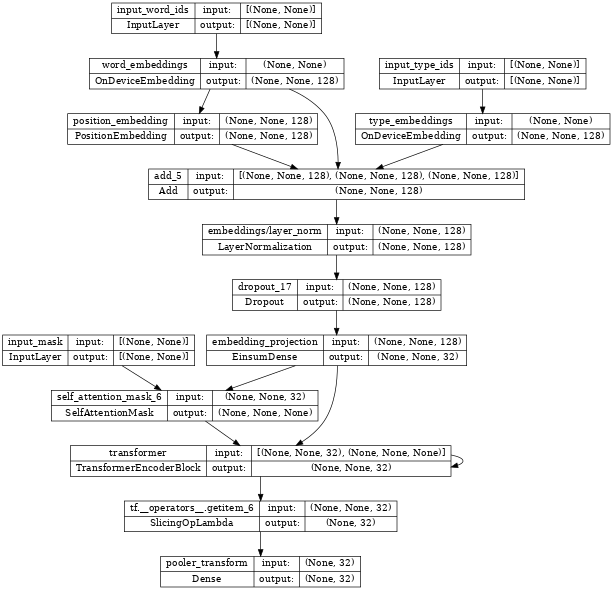
檢查 albert_encoder,我們看到它多次堆疊相同的 Transformer 層 (請注意下方「Transformer」區塊上的迴路)。
tf.keras.utils.plot_model(albert_encoder, show_shapes=True, dpi=48)