在 GitHub 上檢視原始碼
在 GitHub 上檢視原始碼這個筆記本向您展示如何訓練文字分類器來識別冒犯性內容,並使用反事實 Logit 配對 (CLP) 來避免身分用語不公平地扭曲冒犯性內容的分類結果。這類模型嘗試識別粗魯、不尊重或可能讓人不想參與討論的內容,並為內容指派毒性分數。「反事實 Logit 配對」(CLP) 技術可用於識別和減輕身分用語與毒性分數之間的關聯性,並且是 TensorFlow 模型補救程式庫的一部分。
在 Perspective API 最初發布後,使用者發現包含種族或性取向資訊的身分用語與預測的毒性分數之間存在正相關。例如,詞組「I am a lesbian」(我是女同志) 得到的毒性分數為 0.51,而「I am a man」(我是男人) 得到的毒性分數則較低,為 0.2。在此情況下,身分用語並非貶義用法,因此分數不應有如此顯著的差異。
在這個 Colab 中,您將探索如何使用 CLP 訓練具有與 Perspective API 類似偏見的文字分類器,以及如何補救這種偏見。您將按照下列步驟逐步進行
- 建構基準模型來分類文字的毒性。
- 建立
CounterfactualPackedInputs的執行個體,其中包含original_input和counterfactual_data,以評估模型在翻轉率和翻轉次數方面的效能,判斷是否需要介入。 - 使用 CLP 技術進行訓練,以避免模型輸出與敏感身分用語之間產生非預期的關聯性。
- 評估新模型在翻轉率和翻轉次數方面的效能。
本教學課程示範 CLP 技術的基本用法。在根據負責任的 AI 原則評估模型的效能時,請考量還有更多工具可供使用
- 評估不同群組之間的錯誤率
- 使用「公平性指標」中提供的其他指標進行評估
- 考慮探索「負責任的 AI 工具組」。
設定
首先安裝「公平性指標」和 TensorFlow 模型補救程式庫。
pip install --upgrade tensorflow-model-remediationpip install --upgrade fairness-indicators
匯入所有必要元件,包括 CLP 和用於評估的「公平性指標」。
import os
import requests
import tempfile
import zipfile
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_model_analysis as tfma
from google.protobuf import text_format
# Import Counterfactuals.
from tensorflow_model_remediation import counterfactual
import pkg_resources
import importlib
importlib.reload(pkg_resources)
您可以使用下方提供的公用程式函式 download_and_process_civil_comments_data 來下載預先處理的資料,並準備標籤以符合模型的輸出形狀。函式也會將資料下載為 TFRecords,以便加快後續評估速度。
將 comment_text 特徵設定為輸入,並將 toxicity 設定為標籤。
TEXT_FEATURE = 'comment_text'
LABEL = 'toxicity'
BATCH_SIZE = 512
公用程式函式
定義並訓練基準模型
為了縮短執行時間,您可以使用預先訓練的模型,預設會載入該模型。這是一個簡單的 Keras 循序模型,具有初始嵌入和卷積層,可輸出毒性預測。如果您願意,可以變更此設定,並使用上方定義的公用程式函式從頭開始訓練模型。
use_pretrained_model = True
if use_pretrained_model:
URL = 'https://storage.googleapis.com/civil_comments_model/baseline_model.zip'
ZIPPATH = 'baseline_model.zip'
DIRPATH = '/tmp/baseline_model'
with requests.get(URL, allow_redirects=True) as r:
with open(ZIPPATH, 'wb') as z:
z.write(r.content)
with zipfile.ZipFile(ZIPPATH, 'r') as zip_ref:
zip_ref.extractall('/')
baseline_model = tf.keras.models.load_model(
DIRPATH, custom_objects={'KerasLayer' : hub.KerasLayer})
else:
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.BinaryCrossentropy()
baseline_model = (
create_keras_sequential_model())
baseline_model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'])
baseline_model.fit(x=data_train[TEXT_FEATURE],
y=labels_train, batch_size=BATCH_SIZE,
epochs=1)
若要使用「公平性指標」評估原始模型的效能,您需要儲存模型。
base_dir = tempfile.mkdtemp(prefix='saved_models')
baseline_model_location = os.path.join(base_dir, 'model_export_baseline')
baseline_model.save(baseline_model_location, save_format='tf')
判斷是否需要介入
使用 CLP 嘗試降低資料集中性別相關用語的翻轉率和翻轉次數。
準備 CounterfactualPackedInputs
若要使用 CLP,您首先需要建立 CounterfactualPackedInputs 的執行個體,其中包含 original_input 和 counterfactual_data。
CounterfactualPackedInputs 看起來如下
CounterfactualPackedInputs(
original_input=(x, y, sample_weight),
counterfactual_data=(original_x, counterfactual_x,
counterfactual_sample_weight)
)
original_input 應為用於訓練 Keras 模型的原始資料集。counterfactual_data 應為 tf.data.Dataset,其中包含原始 x 值、對應的反事實值和範例權重。counterfactual_x 值與原始值幾乎相同,但已移除或取代一或多個敏感屬性。這個資料集用於配對原始值與反事實值之間的損失函數,目標是確保當敏感屬性不同時,模型的預測不會改變。
以下範例說明如果您移除「gay」一詞,counterfactual_data 會是什麼樣子
original_x: “I am a gay man”
counterfactual_x: “I am a man”
counterfactual_sample_weight”: 1
如果您處理的是文字,可以使用提供的輔助函式 build_counterfactual_data 來建立 counterfactual_data。對於所有其他資料類型,您需要直接提供 counterfactual_data。
如需使用 build_counterfactual_data 建立 counterfactual_data 的範例,請參閱「建立自訂反事實資料集 Colab」。
在此範例中,您將使用 build_counterfactual_data 移除一組性別專屬用語。您必須僅包含非貶義用語,因為貶義用語應具有不同的毒性分數。要求在包含貶義用語的範例中進行相同的預測,可能會意外傷害到較弱勢的群體。
sensitive_terms_to_remove = [
'aunt', 'boy', 'brother', 'dad', 'daughter', 'father', 'female', 'gay',
'girl', 'grandma', 'grandpa', 'grandson', 'grannie', 'granny', 'he',
'heir', 'her', 'him', 'his', 'hubbies', 'hubby', 'husband', 'king',
'knight', 'lad', 'ladies', 'lady', 'lesbian', 'lord', 'man', 'male',
'mom', 'mother', 'mum', 'nephew', 'niece', 'prince', 'princess',
'queen', 'queens', 'she', 'sister', 'son', 'uncle', 'waiter',
'waitress', 'wife', 'wives', 'woman', 'women'
]
# Convert the Pandas DataFrame to a TF Dataset
dataset_train_main = tf.data.Dataset.from_tensor_slices(
(data_train[TEXT_FEATURE].values, labels_train))
counterfactual_data = counterfactual.keras.utils.build_counterfactual_data(
original_input=dataset_train_main,
sensitive_terms_to_remove=sensitive_terms_to_remove)
counterfactual_packed_input = counterfactual.keras.utils.pack_counterfactual_data(
dataset_train_main,
counterfactual_data).batch(BATCH_SIZE)
計算範例數、翻轉率和翻轉次數
接下來執行「公平性指標」來計算翻轉率和翻轉次數,以查看模型是否錯誤地將某些性別認同用語與毒性產生關聯。執行「公平性指標」也可讓您計算範例數,以確保有足夠數量的範例可套用此技術。翻轉的定義是當範例中的身分用語變更時,分類器給出不同的預測。翻轉次數衡量的是,如果指定範例中的身分用語變更,分類器給出不同決策的次數。翻轉率衡量的是,如果指定範例中的身分用語變更,分類器給出不同決策的機率。
def get_eval_results(model_location,
eval_result_path,
validate_tfrecord_file,
slice_selection='gender',
compute_confidence_intervals=True):
"""Get Fairness Indicators eval results."""
# Define slices that you want the evaluation to run on.
eval_config = text_format.Parse("""
model_specs {
label_key: '%s'
}
metrics_specs {
metrics {class_name: "AUC"}
metrics {class_name: "ExampleCount"}
metrics {class_name: "Accuracy"}
metrics {
class_name: "FairnessIndicators"
}
metrics {
class_name: "FlipRate"
config: '{ "counterfactual_prediction_key": "toxicity", '
'"example_id_key": 1 }'
}
}
slicing_specs {
feature_keys: '%s'
}
slicing_specs {}
options {
compute_confidence_intervals { value: %s }
disabled_outputs{values: "analysis"}
}
""" % (LABEL, slice_selection, compute_confidence_intervals),
tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=model_location, tags=[tf.saved_model.SERVING])
return tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
data_location=validate_tfrecord_file,
eval_config=eval_config,
output_path=eval_result_path)
base_dir = tempfile.mkdtemp(prefix='eval')
eval_dir = os.path.join(base_dir, 'tfma_eval_result_no_cf')
base_eval_result = get_eval_results(
baseline_model_location,
eval_dir,
validate_tfrecord_file,
slice_selection='gender')
# docs-infra: no-execute
tfma.addons.fairness.view.widget_view.render_fairness_indicator(
eval_result=base_eval_result)
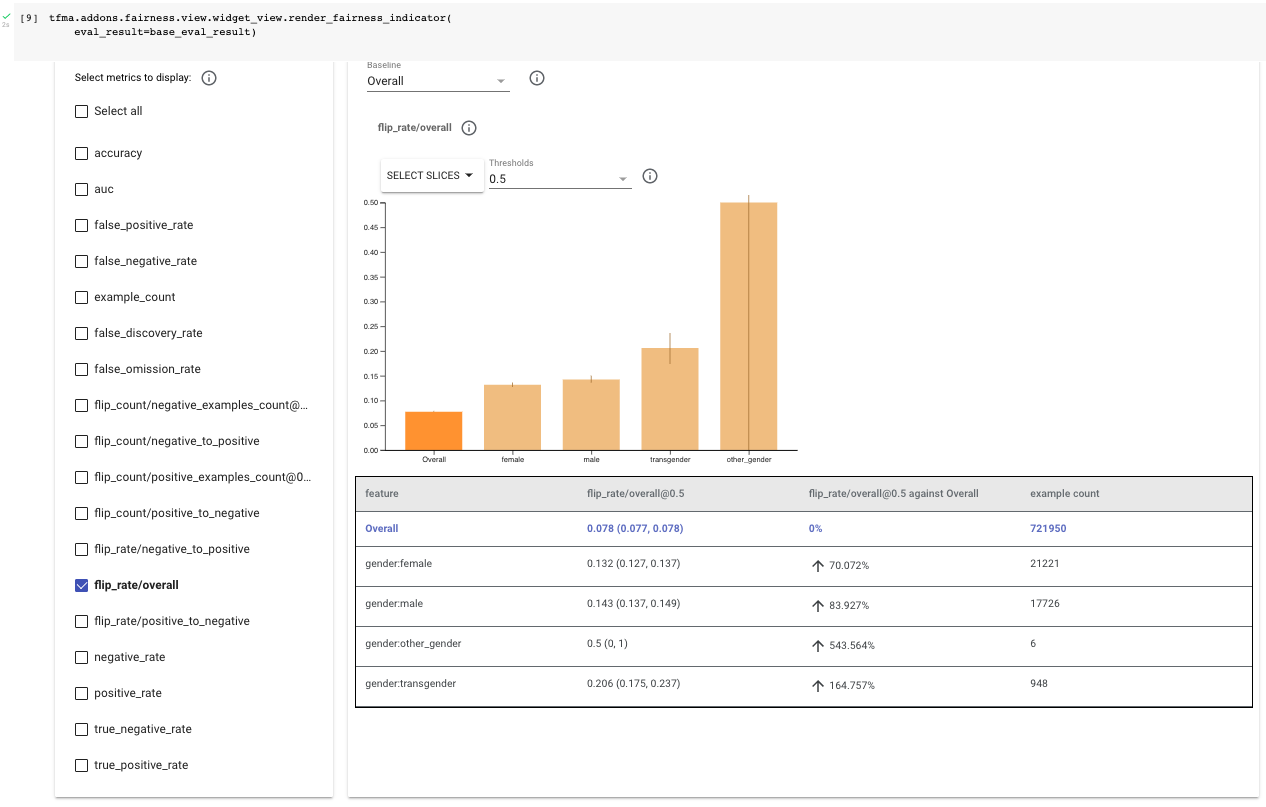
檢查評估結果,從整體翻轉率 (「flip_rate/overall」) 開始。在此範例中,您考量此資料集中的四個性別相關屬性:「女性」、「男性」、「跨性別」和「其他性別」。
首先檢查範例數。與整體資料集相比,「其他性別」和「跨性別」的範例數較少;這在某種程度上是預期的,因為在 ML 資料集中,歷史上處於邊緣地位的群體通常代表性不足。它們也具有較寬的信賴區間,這表示計算出的指標可能不具代表性。這個筆記本著重於「女性」和「男性」子群組,因為沒有足夠的資料可將此技術套用至「其他性別」和「跨性別」。評估「其他性別」和「跨性別」群體的反事實公平性非常重要。您可以收集更多資料來縮小信賴區間。
在「公平性指標」中選取 flip_rate/overall 後,請注意女性的整體翻轉率約為 13%,男性約為 14%,兩者都高於整體資料集的 8%。這表示模型很可能會根據 sensitive_terms_to_remove 中列出的用語是否存在而變更分類。
您現在將使用 CLP 嘗試降低資料集中性別相關用語的翻轉率和翻轉次數。
訓練和評估 CLP 模型
若要使用 CLP 進行訓練,請傳入您的原始預先訓練模型、反事實損失和資料 (以 CounterfactualPackedInputs 的形式)。請注意,CounterfactualModel 中有兩個選用參數:loss_weight 和 loss,您可以調整這些參數來微調模型。
接下來,正常編譯模型 (使用一般非反事實損失),並將其擬合以進行訓練。
counterfactual_weight = 1.0
base_dir = tempfile.mkdtemp(prefix='saved_models')
counterfactual_model_location = os.path.join(
base_dir, 'model_export_counterfactual')
counterfactual_model = counterfactual.keras.CounterfactualModel(
baseline_model,
loss=counterfactual.losses.PairwiseMSELoss(),
loss_weight=counterfactual_weight)
# Compile the model normally after wrapping the original model.
# Note that this means we use the baseline's model's loss here.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.BinaryCrossentropy()
counterfactual_model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'])
counterfactual_model.fit(counterfactual_packed_input,
epochs=1)
counterfactual_model.save_original_model(counterfactual_model_location,
save_format='tf')
# docs-infra: no-execute
def get_eval_results_counterfactual(
baseline_model_location,
counterfactual_model_location,
eval_result_path,
validate_tfrecord_file,
slice_selection='gender'):
"""Get Fairness Indicators eval results."""
eval_config = text_format.Parse("""
model_specs { name: 'original' label_key: '%s' }
model_specs { name: 'counterfactual' label_key: '%s' is_baseline: true }
metrics_specs {
metrics {class_name: "AUC"}
metrics {class_name: "ExampleCount"}
metrics {class_name: "Accuracy"}
metrics { class_name: "FairnessIndicators" }
metrics { class_name: "FlipRate" config: '{ "example_ids_count": 0 }' }
metrics { class_name: "FlipCount" config: '{ "example_ids_count": 0 }' }
}
slicing_specs { feature_keys: '%s' }
slicing_specs {}
options { disabled_outputs{ values: "analysis"} }
""" % (LABEL, LABEL, slice_selection,), tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name='original',
eval_saved_model_path=baseline_model_location,
eval_config=eval_config,
tags=[tf.saved_model.SERVING]),
tfma.default_eval_shared_model(
model_name='counterfactual',
eval_saved_model_path=counterfactual_model_location,
eval_config=eval_config,
tags=[tf.saved_model.SERVING]),
]
return tfma.run_model_analysis(
eval_shared_model=eval_shared_models,
data_location=validate_tfrecord_file,
eval_config=eval_config,
output_path=eval_result_path)
counterfactual_eval_dir = os.path.join(base_dir, 'tfma_eval_result_cf')
counterfactual_eval_result = get_eval_results_counterfactual(
baseline_model_location,
counterfactual_model_location,
counterfactual_eval_dir,
validate_tfrecord_file)
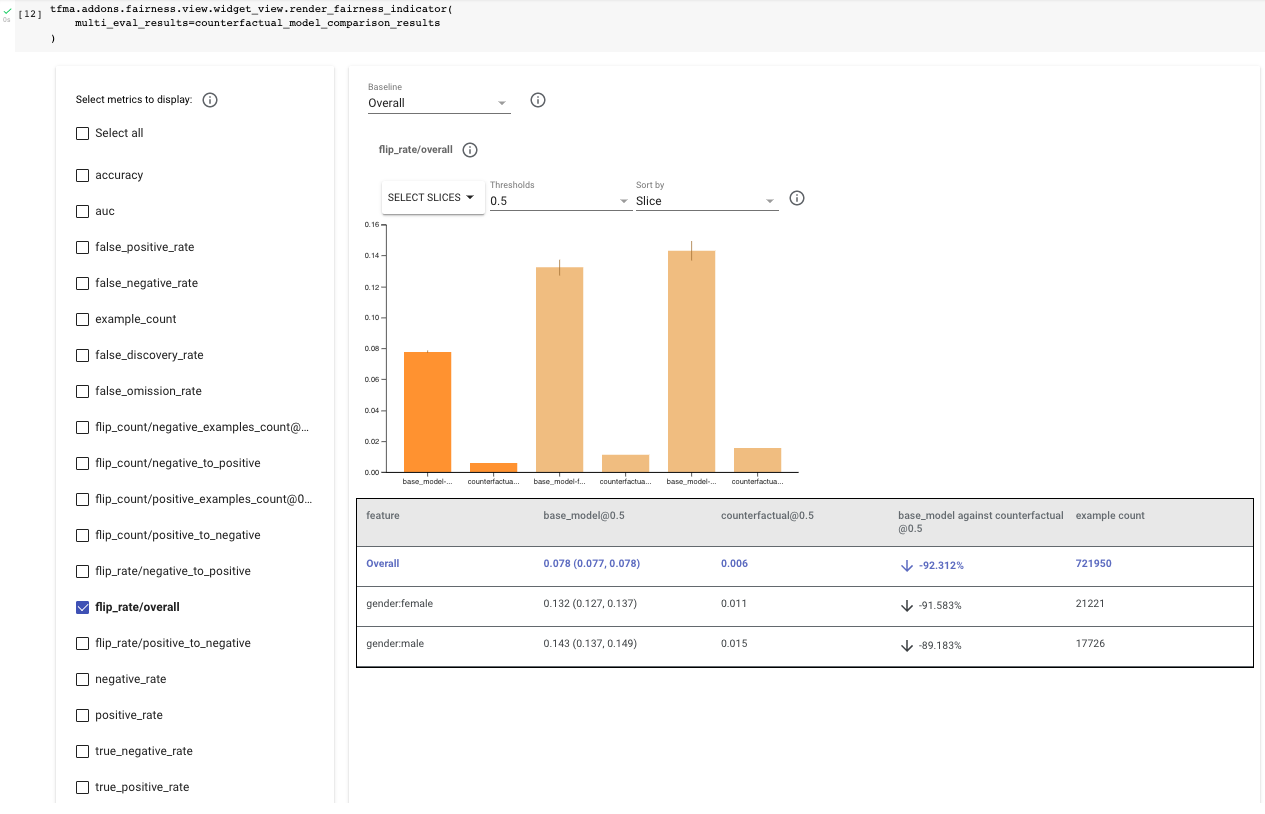
透過將原始模型和反事實模型一起傳遞至「公平性指標」,評估反事實模型,以進行並排比較。再次在「公平性指標」中選取「flip_rate/overall」,並比較這兩個模型之間女性和男性的結果。您應該會注意到整體、女性和男性的翻轉率都下降了約 90%,這使得女性的最終翻轉率約為 1.3%,男性約為 1.4%。
此外,檢閱「flip_rate/negative_to_positive」和「flip_rate/positive_to_negative」,您會注意到模型仍較有可能將性別相關內容翻轉為有毒內容,但總次數已減少超過 35%。
# docs-infra: no-execute
counterfactual_model_comparison_results = {
'base_model': base_eval_result,
'counterfactual': counterfactual_eval_result.get_results()[0],
}
tfma.addons.fairness.view.widget_view.render_fairness_indicator(
multi_eval_results=counterfactual_model_comparison_results
)
若要進一步瞭解 CLP 和其他補救技術,請探索「負責任的 AI」網站。