
神經結構化學習 (NSL) 著重於透過利用結構化訊號 (若有的話) 以及特徵輸入來訓練深度神經網路。如同 Bui 等人 (WSDM'18) 所介紹,這些結構化訊號可用於正規化神經網路的訓練,以強制模型學習準確的預測 (透過最小化監督式損失),同時維持輸入結構的相似性 (透過最小化鄰近損失,請參閱下圖)。這項技術是通用的,可應用於任意神經架構 (例如前饋 NN、卷積 NN 和循環 NN)。
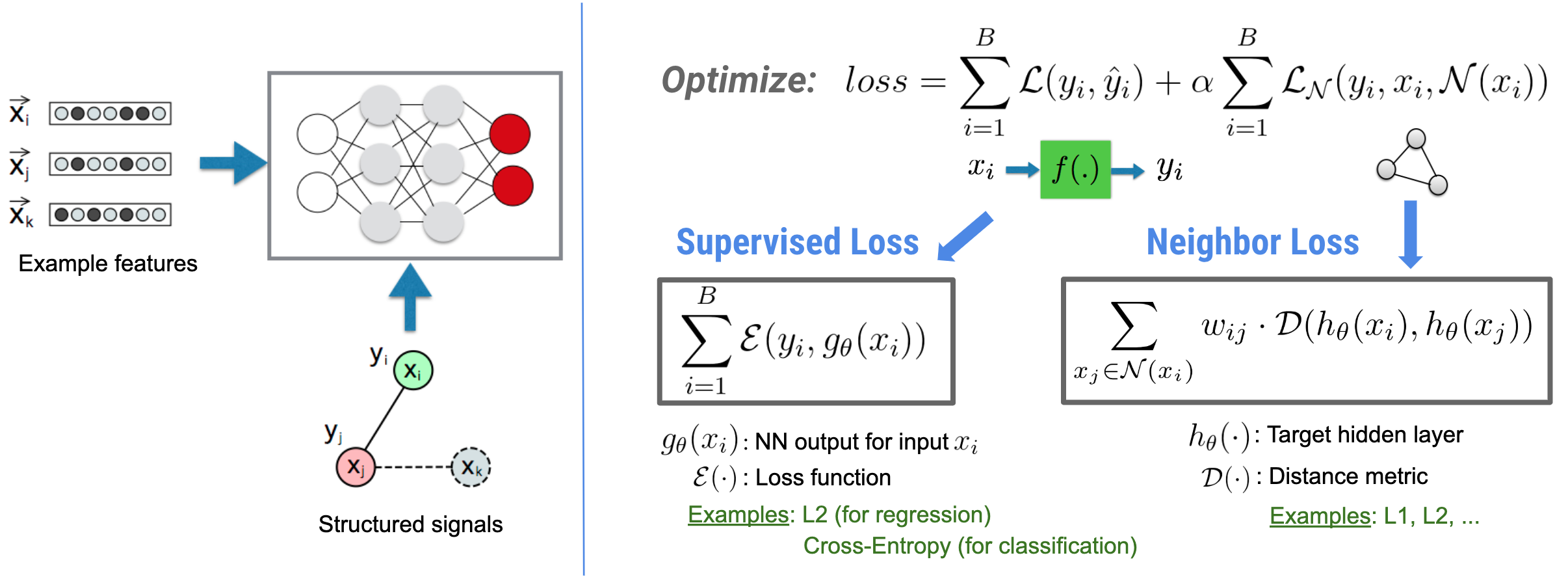
請注意,廣義鄰近損失方程式具有彈性,除了上面說明的形式之外,還可以有其他形式。例如,我們也可以選擇 \(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) 作為鄰近損失,這會計算真實值 \(y_i\) 與鄰近值 \(g_\theta(x_j)\) 的預測之間的距離。這通常用於對抗式學習 (Goodfellow 等人,ICLR'15)。因此,如果鄰近值以圖形明確表示,則 NSL 會推廣到神經圖形學習;如果鄰近值由對抗性擾動隱含地誘導,則會推廣到對抗式學習。
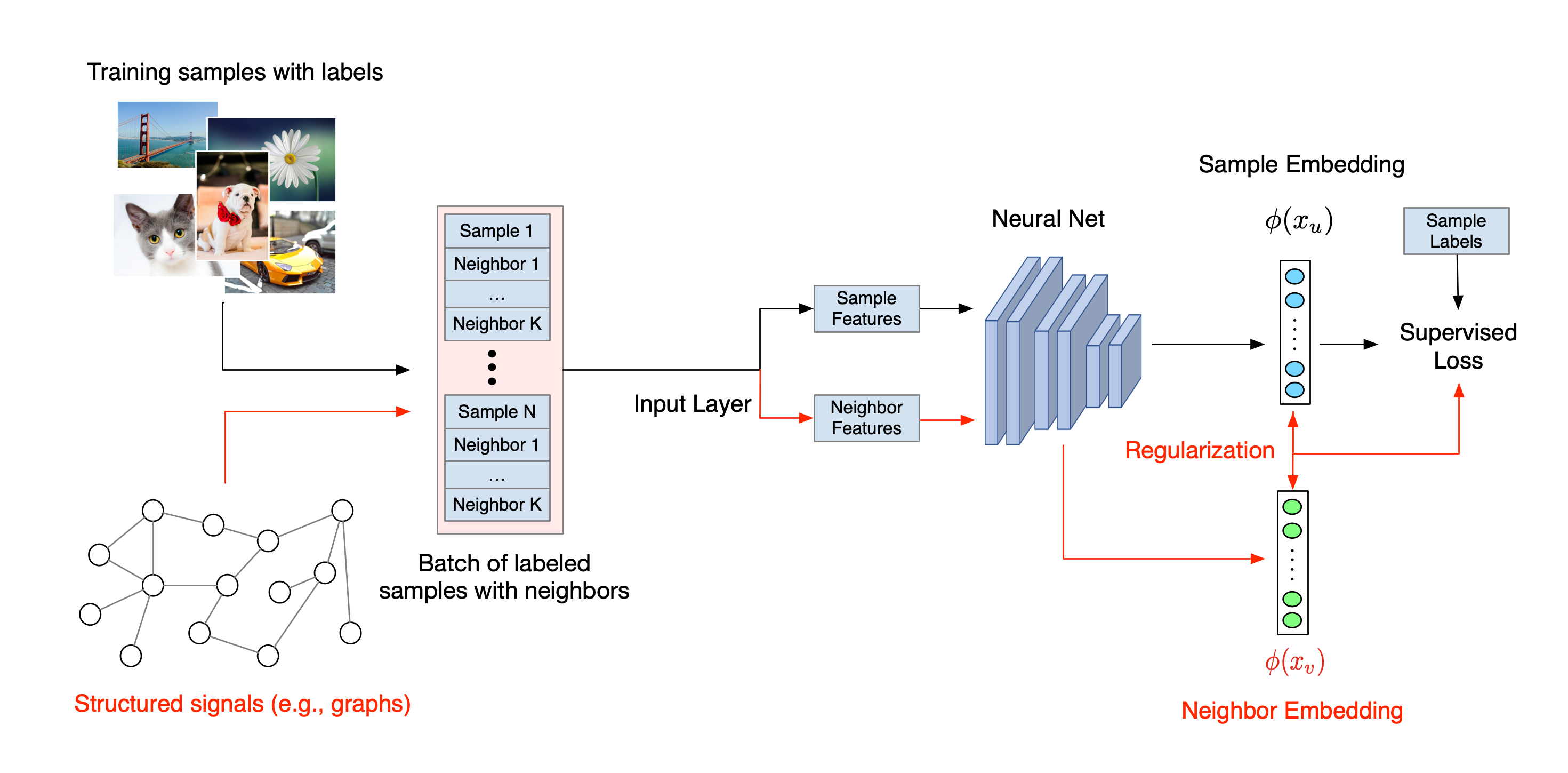
神經結構化學習的整體工作流程如下圖所示。黑色箭頭代表傳統的訓練工作流程,紅色箭頭代表 NSL 導入以利用結構化訊號的新工作流程。首先,擴增訓練樣本以包含結構化訊號。當未明確提供結構化訊號時,可以建構或誘導它們 (後者適用於對抗式學習)。接下來,將擴增的訓練樣本 (包括原始樣本及其對應的鄰近值) 饋送到神經網路以計算其嵌入。計算樣本的嵌入與其鄰近值的嵌入之間的距離,並將其用作鄰近損失,這被視為正規化項並新增至最終損失。對於基於明確鄰近值的正規化,我們通常將鄰近損失計算為樣本的嵌入與鄰近值的嵌入之間的距離。但是,神經網路的任何層都可用於計算鄰近損失。另一方面,對於基於誘導鄰近值的正規化 (對抗式),我們將鄰近損失計算為誘導對抗性鄰近值的輸出預測與真實值標籤之間的距離。
為何使用 NSL?
NSL 帶來以下優點
- 更高的準確性:樣本之間的結構化訊號可以提供特徵輸入中不一定可用的資訊;因此,聯合訓練方法 (同時使用結構化訊號和特徵) 已被證明在各種任務中優於許多現有方法 (僅依賴使用特徵進行訓練),例如文件分類和語意意圖分類 (Bui 等人,WSDM'18 和 Kipf 等人,ICLR'17)。
- 穩健性:使用對抗式範例訓練的模型已被證明對旨在誤導模型預測或分類的對抗性擾動具有穩健性 (Goodfellow 等人,ICLR'15 和 Miyato 等人,ICLR'16)。當訓練樣本數量較少時,使用對抗式範例進行訓練也有助於提高模型準確性 (Tsipras 等人,ICLR'19)。
- 所需的標記資料更少:NSL 使神經網路能夠利用標記和未標記資料,這將學習範例擴展到半監督式學習。具體而言,NSL 允許網路在監督式設定中使用標記資料進行訓練,同時驅動網路學習可能具有或不具有標籤的「鄰近樣本」的相似隱藏表示。當標記資料量相對較小時,這項技術已顯示出在提高模型準確性方面大有可為 (Bui 等人,WSDM'18 和 Miyato 等人,ICLR'16)。
逐步教學課程
為了獲得神經結構化學習的實務經驗,我們提供了教學課程,涵蓋結構化訊號可以明確給定、建構或誘導的各種情境。以下是一些範例
使用自然圖形進行文件分類的圖形正規化。在本教學課程中,我們將探索使用圖形正規化來分類形成自然 (有機) 圖形的文件。
使用合成圖形進行情感分類的圖形正規化。在本教學課程中,我們將示範如何透過建構 (合成) 結構化訊號,使用圖形正規化來分類電影評論情感。
用於圖片分類的對抗式學習。在本教學課程中,我們將探索使用對抗式學習 (誘導結構化訊號) 來分類包含數字的圖片。
更多範例和教學課程可在我們的 GitHub 存放區的 examples 目錄中找到。