
總覽
TensorFlow Model Analysis (TFMA) 是一個用於執行模型評估的程式庫。
- 適用對象:機器學習工程師或資料科學家
- 對象需求:想要分析及瞭解他們的 TensorFlow 模型
- 產品定位:獨立程式庫或 TFX 管線的元件
- 產品功能:以分散式方式,針對大量資料,依據訓練時定義的相同指標評估模型。這些指標會針對資料分區進行比較,並在 Jupyter 或 Colab 筆記本中視覺化。
- 不同於:TensorBoard 等提供模型內省功能的某些模型內省工具
TFMA 使用 Apache Beam,以分散式方式針對大量資料執行運算。以下各節說明如何設定基本 TFMA 評估管線。如要進一步瞭解基礎實作方式,請參閱架構。
如果您只想立即開始使用,請參閱我們的 colab 筆記本。
這個頁面也可以從 tensorflow.org 查看。
支援的模型類型
TFMA 的設計宗旨是支援以 TensorFlow 為基礎的模型,但也相當容易擴充,以便支援其他架構。過去,TFMA 需要建立 EvalSavedModel 才能使用 TFMA,但最新版的 TFMA 支援多種模型類型,可滿足使用者的各種需求。設定 EvalSavedModel 只有在使用以 tf.estimator 為基礎的模型,且需要自訂訓練時間指標時才需要。
請注意,由於 TFMA 現在以服務模型為基礎執行,因此 TFMA 不再自動評估訓練時間新增的指標。但有個例外情況,就是使用 Keras 模型,因為 Keras 會將使用的指標與儲存的模型一起儲存。不過,如果這是硬性規定,則最新的 TFMA 具有回溯相容性,因此 EvalSavedModel 仍然可以在 TFMA 管線中執行。
下表摘要說明預設支援的模型
| 模型類型 | 訓練時間指標 | 訓練後指標 |
|---|---|---|
| TF2 (keras) | 是* | 是 |
| TF2 (通用) | 不適用 | 是 |
| EvalSavedModel (estimator) | 是 | 是 |
| 否 (pd.DataFrame 等) | 不適用 | 是 |
- 訓練時間指標是指在訓練時間定義並與模型一起儲存的指標 (TFMA EvalSavedModel 或 Keras 儲存模型)。訓練後指標是指透過
tfma.MetricConfig新增的指標。 - 通用 TF2 模型是指匯出可用於推論的簽名,且不以 Keras 或 Estimator 為基礎的自訂模型。
如要進一步瞭解如何設定及配置這些不同的模型類型,請參閱常見問題。
設定
執行評估前,需要進行少量設定。首先,必須定義 tfma.EvalConfig 物件,以便為要評估的模型、指標和分區提供規格。其次,需要建立 tfma.EvalSharedModel,指向評估期間要使用的實際模型。定義完成後,即可呼叫 tfma.run_model_analysis 和適當的資料集來執行評估。如要瞭解詳情,請參閱設定指南。
如果在 TFX 管線中執行,請參閱 TFX 指南,瞭解如何將 TFMA 配置為以 TFX Evaluator 元件執行。
範例
單一模型評估
以下範例使用 tfma.run_model_analysis,針對服務模型執行評估。如要瞭解所需的不同設定,請參閱設定指南。
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
如要進行分散式評估,請使用分散式執行器建構 Apache Beam 管線。在管線中,使用 tfma.ExtractEvaluateAndWriteResults 進行評估並寫出結果。結果可以使用 tfma.load_eval_result 載入以進行視覺化。
例如
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
模型驗證
如要針對候選模型和基準模型執行模型驗證,請更新設定以加入門檻設定,並將兩個模型傳遞至 tfma.run_model_analysis。
例如
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
視覺化
TFMA 評估結果可以使用 TFMA 內含的前端元件在 Jupyter 筆記本中視覺化。例如
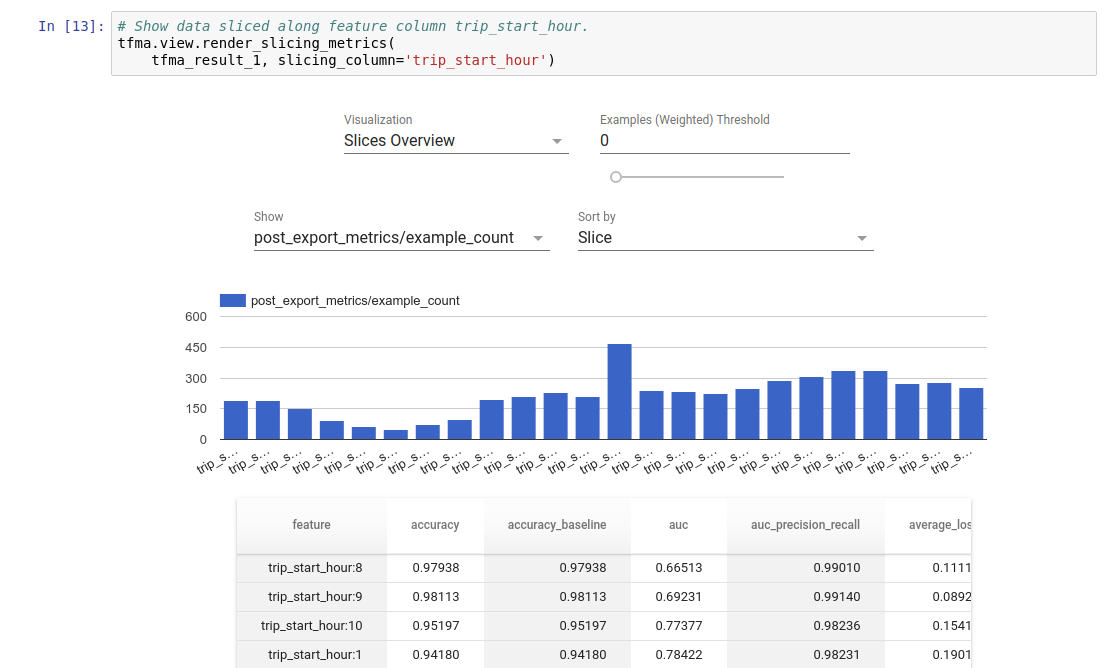 .
.