
簡介
TFX 是以 TensorFlow 為基礎的 Google 生產規模機器學習 (ML) 平台。它提供設定架構和共用程式庫,以整合定義、啟動及監控機器學習系統所需的常用組件。
TFX 1.0
我們很高興宣布 TFX 1.0.0 版本正式推出。這是 TFX 的初始 Beta 後版本,提供穩定的公開 API 和 Artifacts。您可以放心,在 RFC 中定義的相容性範圍內升級後,您未來的 TFX 管線仍可繼續運作。
安裝

![]()
pip install tfx
每夜建置套件
TFX 也將每夜建置套件託管於 Google Cloud 的 https://pypi-nightly.tensorflow.org。若要安裝最新的每夜建置套件,請使用下列指令
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
這會安裝 TFX 主要依附元件 (例如 TensorFlow Model Analysis (TFMA)、TensorFlow Data Validation (TFDV)、TensorFlow Transform (TFT)、TFX Basic Shared Libraries (TFX-BSL)、ML Metadata (MLMD)) 的每夜建置套件。
關於 TFX
TFX 是用於在生產環境中建構和管理 ML 工作流程的平台。TFX 提供下列功能
用於建構 ML 管線的工具組。TFX 管線可讓您在多個平台上編排 ML 工作流程,例如:Apache Airflow、Apache Beam 和 Kubeflow Pipelines。
一組標準組件,您可以將其用作管線的一部分,或用作 ML 訓練指令碼的一部分。TFX 標準組件提供經過驗證的功能,可協助您輕鬆開始建構 ML 流程。
程式庫,提供許多標準組件的基本功能。您可以使用 TFX 程式庫將此功能新增至您自己的自訂組件,或單獨使用它們。
TFX 是以 TensorFlow 為基礎的 Google 生產規模機器學習工具組。它提供設定架構和共用程式庫,以整合定義、啟動及監控機器學習系統所需的常用組件。
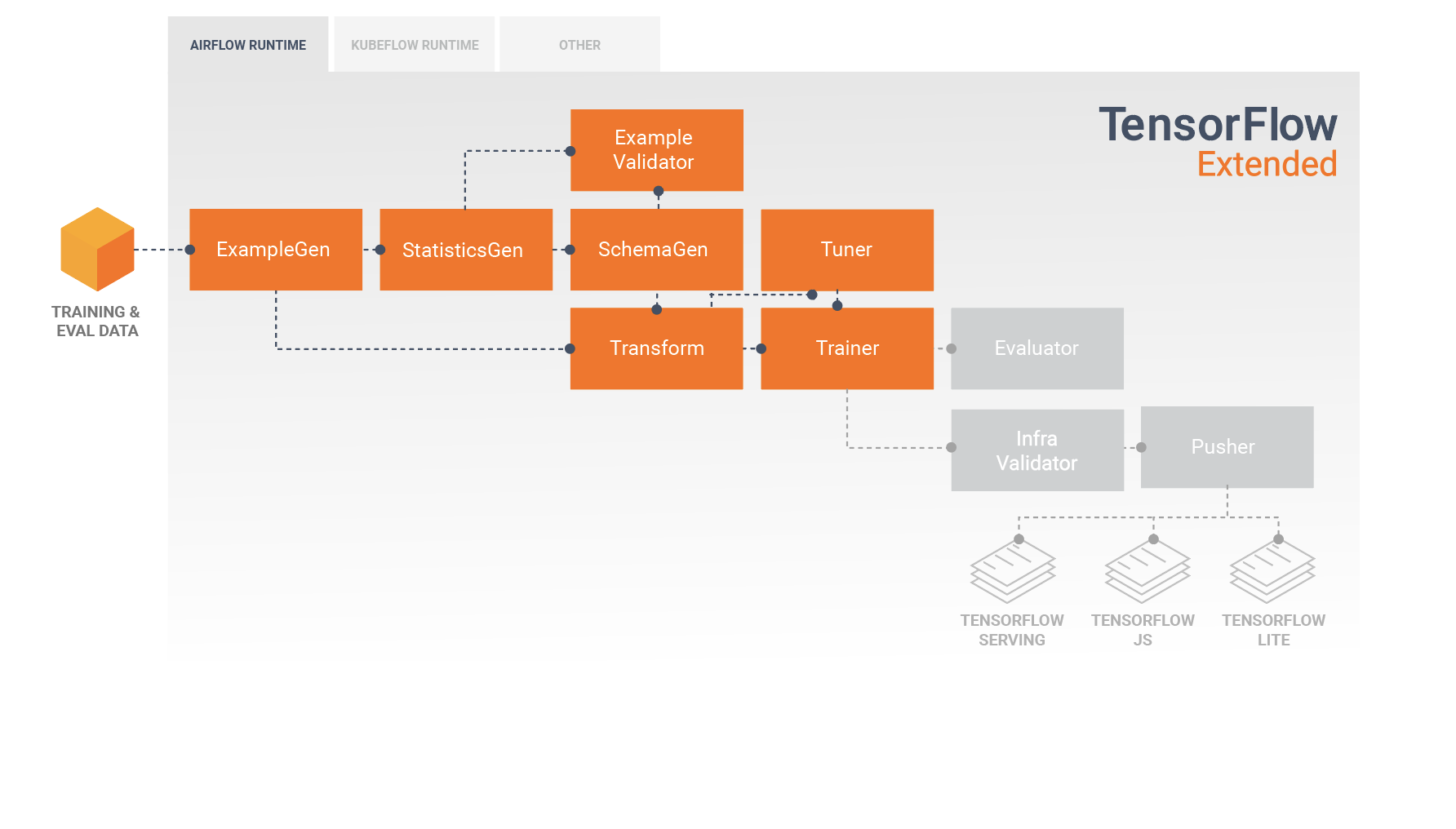
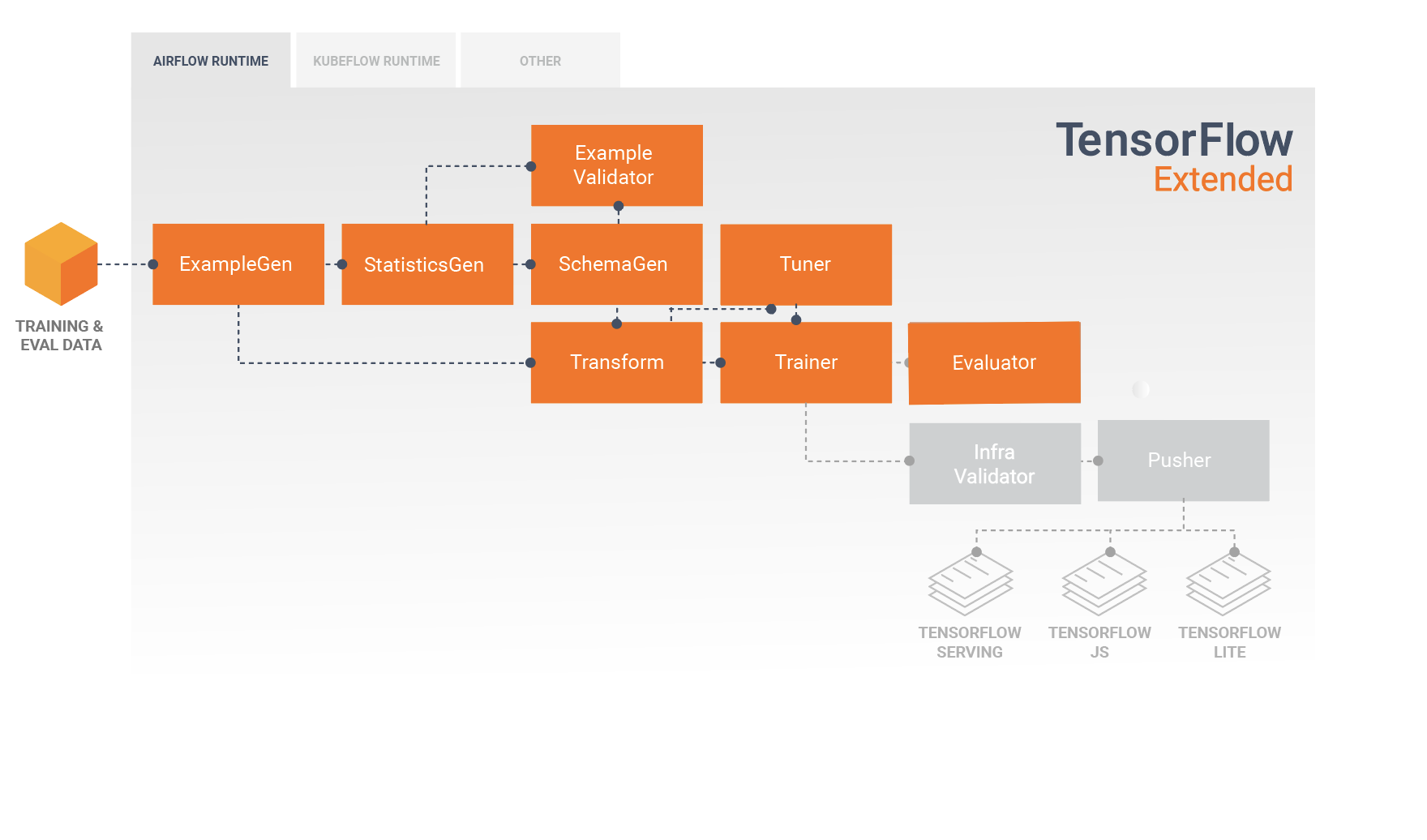
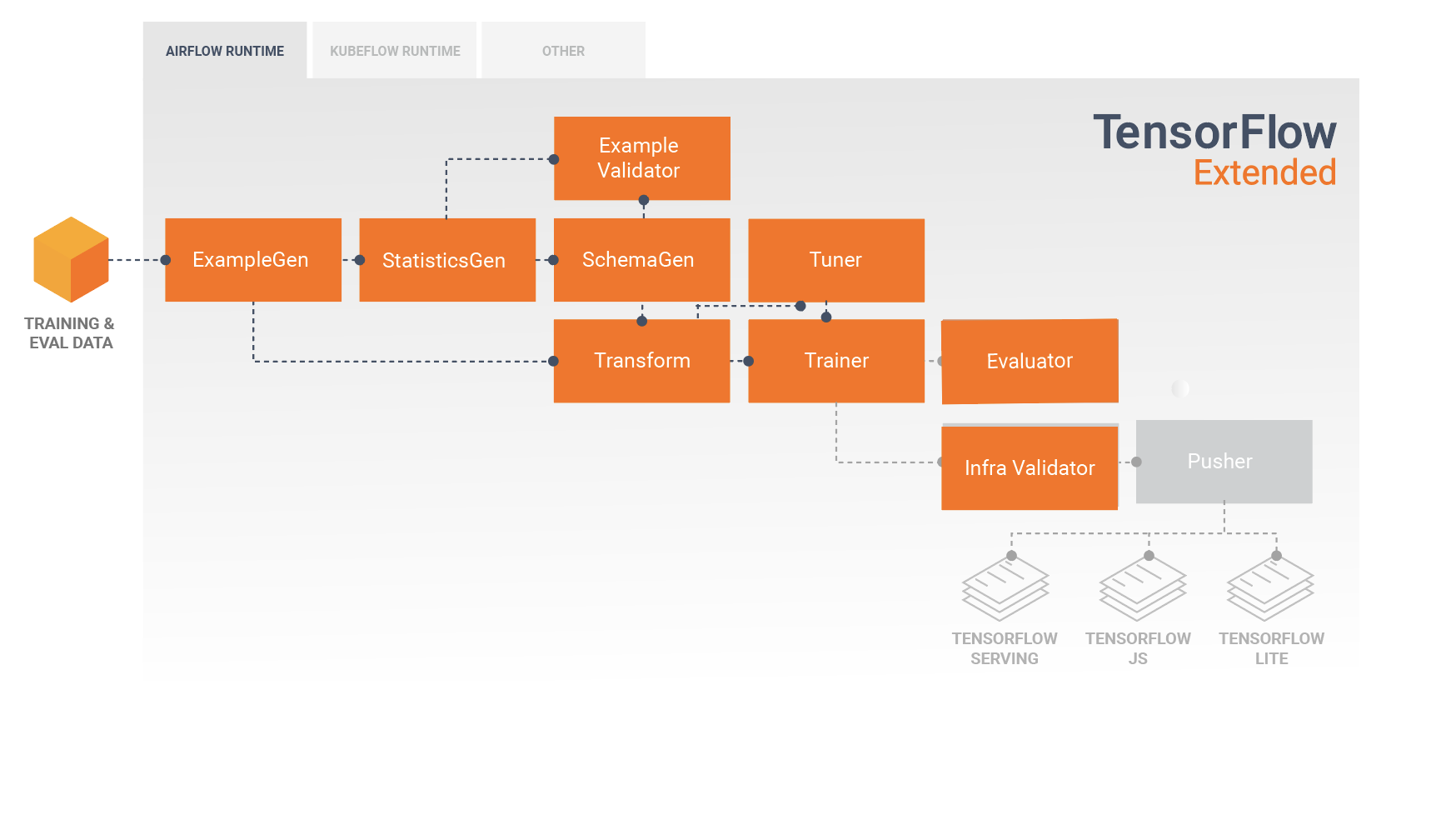
TFX 標準組件
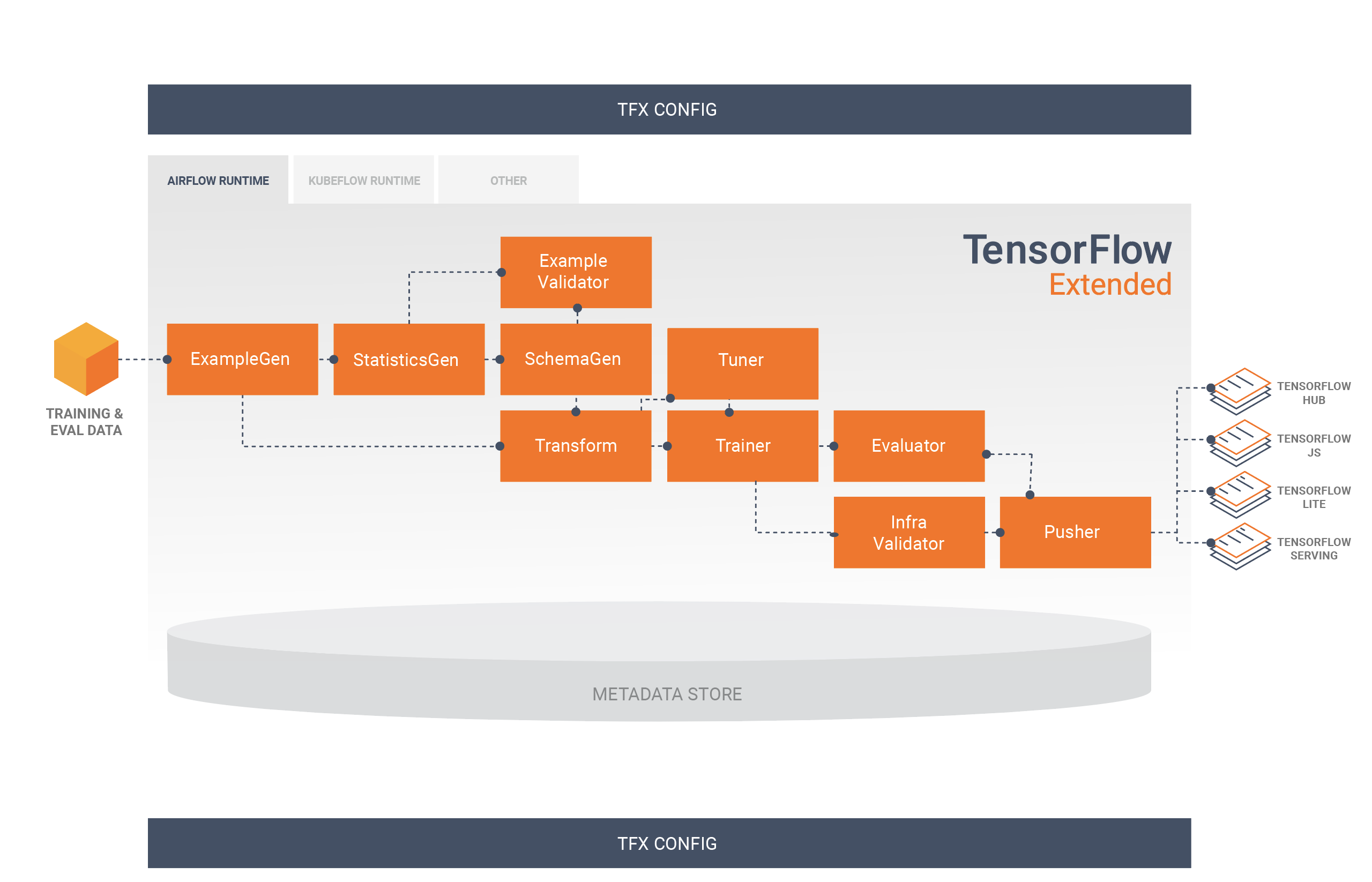
TFX 管線是一連串實作 ML 管線的組件,專為可擴展、高效能的機器學習任務而設計。其中包括模型建構、訓練、部署推論,以及管理線上、原生行動裝置和 JavaScript 目標的部署作業。
TFX 管線通常包含下列組件
ExampleGen 是管線的初始輸入組件,可擷取輸入資料集並選擇性地分割資料集。
StatisticsGen 計算資料集的統計資訊。
SchemaGen 檢查統計資訊並建立資料綱要。
ExampleValidator 尋找資料集中的異常和遺失值。
Transform 對資料集執行特徵工程。
Trainer 訓練模型。
Tuner 調整模型的超參數。
Evaluator 深入分析訓練結果,並協助您驗證匯出的模型,確保模型「夠好」可以推送到生產環境。
InfraValidator 檢查模型是否真的可從基礎架構部署,並防止不良模型被推送。
Pusher 在部署基礎架構上部署模型。
BulkInferrer 對具有未標記推論請求的模型執行批次處理。
此圖表說明這些組件之間資料的流動
TFX 程式庫
TFX 包含程式庫和管線組件。此圖表說明 TFX 程式庫和管線組件之間的關係
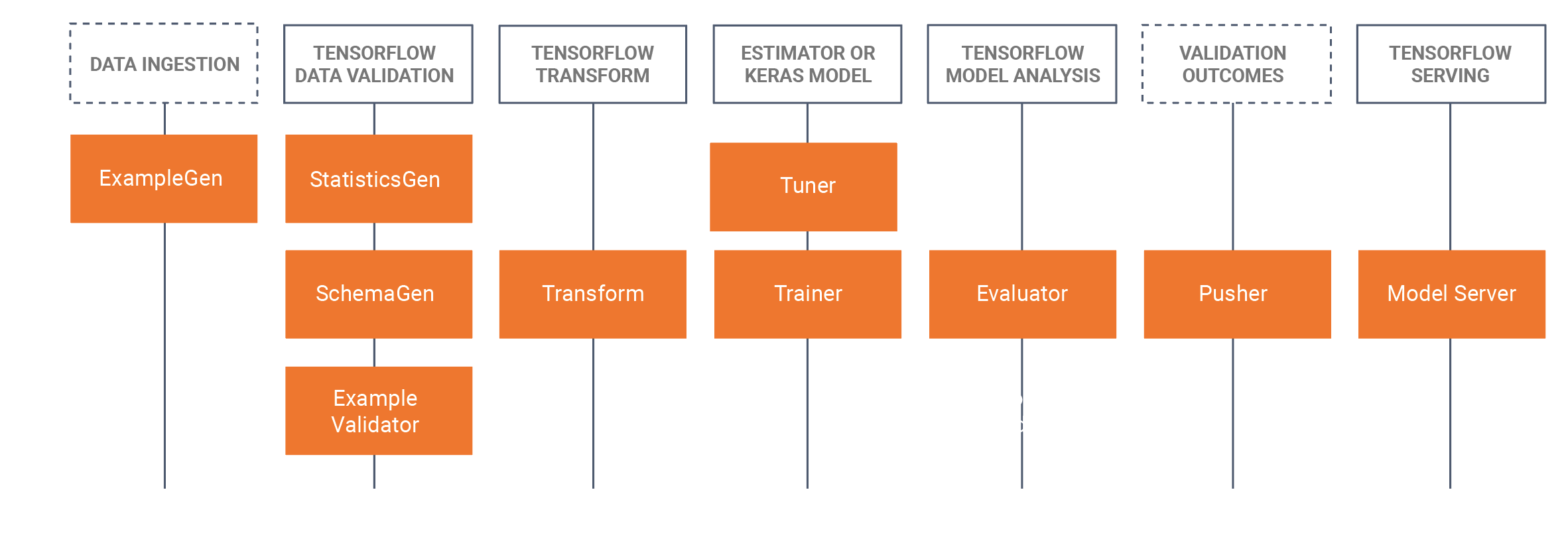
TFX 提供多個 Python 套件,這些套件是程式庫,用於建立管線組件。您將使用這些程式庫來建立管線的組件,以便您的程式碼可以專注於您管線的獨特之處。
TFX 程式庫包括
TensorFlow Data Validation (TFDV) 是一個用於分析和驗證機器學習資料的程式庫。它設計為高度可擴展,並能與 TensorFlow 和 TFX 良好協作。TFDV 包括
- 訓練和測試資料摘要統計資訊的可擴展計算。
- 與資料分佈和統計資訊檢視器的整合,以及成對資料集的刻面比較 (Facets)。
- 自動資料綱要產生,用於描述對資料的期望,例如必要值、範圍和詞彙。
- 綱要檢視器,可協助您檢查綱要。
- 異常偵測,用於識別異常,例如遺失的特徵、超出範圍的值或錯誤的特徵類型等等。
- 異常檢視器,讓您可以查看哪些特徵有異常,並進一步瞭解以更正它們。
TensorFlow Transform (TFT) 是一個使用 TensorFlow 預先處理資料的程式庫。TensorFlow Transform 適用於需要完整遍歷的資料,例如
- 通過平均值和標準差正規化輸入值。
- 通過在所有輸入值上產生詞彙表,將字串轉換為整數。
- 通過根據觀察到的資料分佈將浮點數分配到儲存桶,將其轉換為整數。
TensorFlow 用於使用 TFX 訓練模型。它會擷取訓練資料和模型建構程式碼,並建立 SavedModel 結果。它還整合了由 TensorFlow Transform 建立的特徵工程管線,用於預先處理輸入資料。
KerasTuner 用於調整模型的超參數。
TensorFlow Model Analysis (TFMA) 是一個用於評估 TensorFlow 模型的程式庫。它與 TensorFlow 一起使用,以建立 EvalSavedModel,這成為其分析的基礎。它允許使用者以分散式方式在大量資料上評估其模型,使用其訓練器中定義的相同指標。這些指標可以在不同的資料切片上計算,並在 Jupyter 筆記本中視覺化。
TensorFlow Metadata (TFMD) 為元數據提供標準表示法,這些元數據在使用 TensorFlow 訓練機器學習模型時很有用。元數據可以手動產生,也可以在輸入資料分析期間自動產生,並且可以用於資料驗證、探索和轉換。元數據序列化格式包括
- 描述表格資料 (例如 tf.Examples) 的綱要。
- 此類資料集的摘要統計資訊集合。
ML Metadata (MLMD) 是一個用於記錄和檢索與 ML 開發人員和資料科學家工作流程相關聯的元數據的程式庫。大多數情況下,元數據使用 TFMD 表示法。MLMD 使用 SQL-Lite、MySQL 和其他類似的資料儲存區來管理持久性。
支援技術
必要項目
- Apache Beam 是一個開放原始碼、統一的模型,用於定義批次和串流資料並行處理管線。TFX 使用 Apache Beam 來實作資料並行管線。然後,管線由 Beam 支援的分散式處理後端之一執行,其中包括 Apache Flink、Apache Spark、Google Cloud Dataflow 等。
選用項目
Orchestrators (例如 Apache Airflow 和 Kubeflow) 使配置、操作、監控和維護 ML 管線變得更加容易。
Apache Airflow 是一個用於以程式設計方式編寫、排程和監控工作流程的平台。TFX 使用 Airflow 將工作流程編寫為任務的有向無環圖 (DAG)。Airflow 調度器在遵循指定依附元件的同時,在工作人員陣列上執行任務。豐富的命令列工具使對 DAG 執行複雜操作變得輕而易舉。豐富的使用者介面讓您可以輕鬆地視覺化在生產環境中運行的管線、監控進度,並在需要時排除問題。當工作流程定義為程式碼時,它們會變得更易於維護、版本控制、測試和協作。
Kubeflow 致力於簡化、可攜式且可擴展地在 Kubernetes 上部署機器學習 (ML) 工作流程。Kubeflow 的目標不是重新建立其他服務,而是提供一種直接的方式來將用於 ML 的最佳開放原始碼系統部署到多樣化的基礎架構。Kubeflow Pipelines 能夠在 Kubeflow 上組合和執行可重現的工作流程,並與實驗和基於筆記本的體驗整合。Kubernetes 上的 Kubeflow Pipelines 服務包括託管的元數據儲存區、基於容器的 Orchestration 引擎、筆記本伺服器和 UI,以協助使用者大規模開發、執行和管理複雜的 ML 管線。Kubeflow Pipelines SDK 允許以程式設計方式建立和共用組件以及組合管線。
可攜性與互通性
TFX 設計為可移植到多個環境和 Orchestration 架構,包括 Apache Airflow、Apache Beam 和 Kubeflow。它也可移植到不同的運算平台,包括內部部署和雲端平台,例如 Google Cloud Platform (GCP)。特別是,TFX 可與多個託管的 GCP 服務互通,例如用於訓練和預測的 Cloud AI Platform,以及用於分散式資料處理的 Cloud Dataflow,適用於 ML 生命週期的其他多個方面。
模型與 SavedModel
模型
模型是訓練過程的輸出。它是訓練過程中學習到的權重的序列化記錄。這些權重隨後可用於計算新輸入範例的預測。對於 TFX 和 TensorFlow,「模型」指的是包含到目前為止學習到的權重的檢查點。
請注意,「模型」也可能指 TensorFlow 計算圖的定義 (即 Python 檔案),該定義表達如何計算預測。這兩種含義可能會根據上下文互換使用。
SavedModel
- SavedModel 是什麼:TensorFlow 模型的通用、語言中立、密封、可恢復的序列化格式。
- 為何重要:它使更高等級的系統能夠使用單一抽象化來生產、轉換和使用 TensorFlow 模型。
SavedModel 是在生產環境中部署 TensorFlow 模型,或為原生行動裝置或 JavaScript 應用程式匯出已訓練模型的建議序列化格式。例如,若要將模型轉換為用於進行預測的 REST 服務,您可以將模型序列化為 SavedModel,並使用 TensorFlow Serving 部署它。如需更多資訊,請參閱部署 TensorFlow 模型。
綱要
某些 TFX 組件使用對輸入資料的描述,稱為綱要。綱要是 schema.proto 的實例。綱要是一種 協議緩衝區,更廣為人知的是「protobuf」。綱要可以指定特徵值的資料類型、特徵是否必須出現在所有範例中、允許的值範圍和其他屬性。使用 TensorFlow Data Validation (TFDV) 的好處之一是,它將通過從訓練資料中推斷類型、類別和範圍來自動產生綱要。
以下是綱要 protobuf 的摘錄
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
下列組件使用綱要
- TensorFlow Data Validation
- TensorFlow Transform
在典型的 TFX 管線中,TensorFlow Data Validation 會產生綱要,該綱要由其他組件使用。
使用 TFX 進行開發
TFX 為機器學習專案的每個階段提供強大的平台,從本地機器的研究、實驗和開發,到部署。為了避免程式碼重複並消除 訓練/部署偏差 的潛在可能性,強烈建議您為模型訓練和已訓練模型的部署實作 TFX 管線,並使用 Transform 組件,這些組件利用 TensorFlow Transform 程式庫進行訓練和推論。這樣做,您將一致地使用相同的預先處理和分析程式碼,並避免訓練使用的資料與生產環境中饋送到已訓練模型的資料之間存在差異,同時受益於一次編寫該程式碼。
資料探索、視覺化呈現和清理
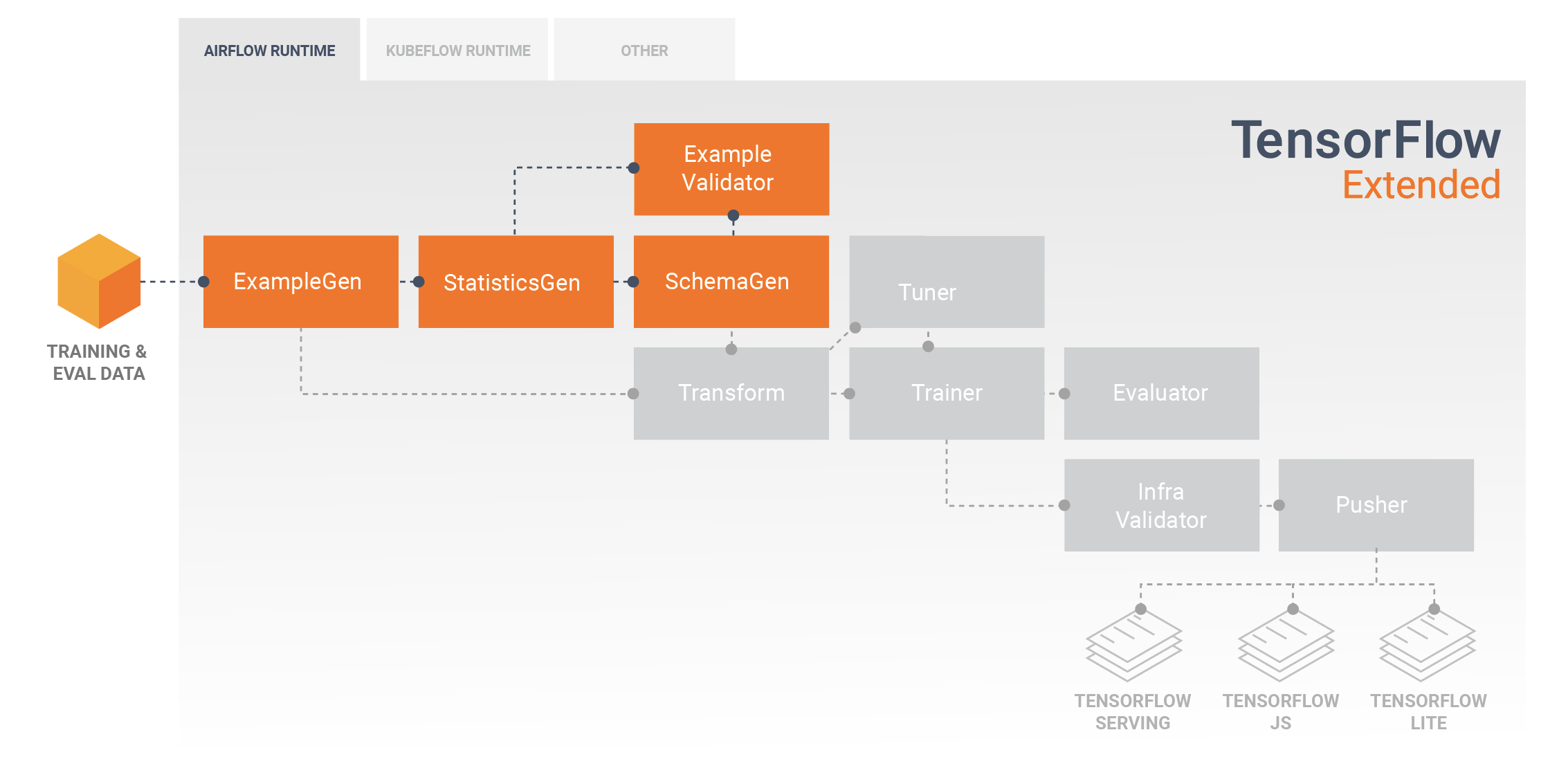
TFX 管線通常從 ExampleGen 組件開始,該組件接受輸入資料並將其格式化為 tf.Examples。通常,這是在資料已分割為訓練和評估資料集之後完成的,因此實際上會有兩個 ExampleGen 組件副本,每個副本分別用於訓練和評估。之後通常是 StatisticsGen 組件和 SchemaGen 組件,它們將檢查您的資料並推斷資料綱要和統計資訊。綱要和統計資訊將由 ExampleValidator 組件使用,該組件將在您的資料中尋找異常、遺失值和不正確的資料類型。所有這些組件都利用 TensorFlow Data Validation 程式庫的功能。
在對資料集進行初始探索、視覺化呈現和清理時,TensorFlow Data Validation (TFDV) 是一個有價值的工具。TFDV 檢查您的資料並推斷資料類型、類別和範圍,然後自動協助識別異常和遺失值。它還提供視覺化呈現工具,可以幫助您檢查和理解您的資料集。在您的管線完成後,您可以從 MLMD 讀取元數據,並在 Jupyter 筆記本中使用 TFDV 的視覺化呈現工具來分析您的資料。
在您的初始模型訓練和部署之後,TFDV 可以用於監控來自對您已部署模型的推論請求的新資料,並尋找異常和/或漂移。這對於由於趨勢或季節性而隨時間變化的時間序列資料尤其有用,並且可以幫助告知何時存在資料問題或何時需要在新資料上重新訓練模型。
資料視覺化呈現
在您完成資料通過使用 TFDV 的管線部分 (通常為 StatisticsGen、SchemaGen 和 ExampleValidator) 的首次運行後,您可以在 Jupyter 風格的筆記本中視覺化呈現結果。對於其他運行,您可以在進行調整時比較這些結果,直到您的資料對您的模型和應用程式而言達到最佳狀態。
您將首先查詢 ML Metadata (MLMD) 以找到這些組件的執行結果,然後使用 TFDV 中的視覺化呈現支援 API 在您的筆記本中建立視覺化呈現。這包括 tfdv.load_statistics() 和 tfdv.visualize_statistics()。使用此視覺化呈現,您可以更好地理解資料集的特性,並在必要時進行修改。
開發和訓練模型
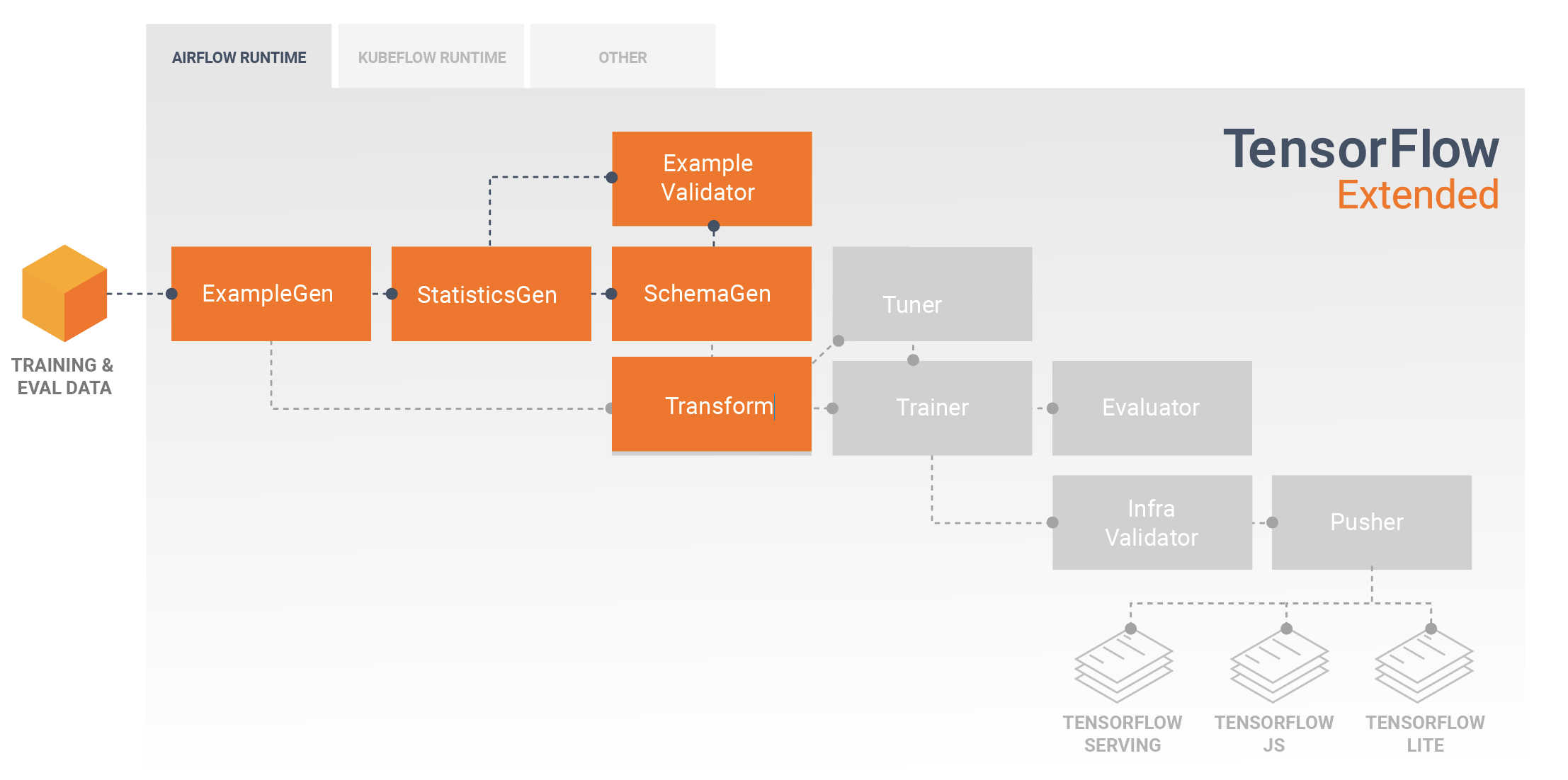
典型的 TFX 管線將包含 Transform 組件,該組件將通過利用 TensorFlow Transform (TFT) 程式庫的功能來執行特徵工程。Transform 組件使用 SchemaGen 組件建立的綱要,並應用資料轉換來建立、組合和轉換將用於訓練模型的特徵。如果發送用於推論請求的資料中也可能存在遺失值和類型轉換,則也應在 Transform 組件中完成遺失值清理和類型轉換。在 TFX 中設計用於訓練的 TensorFlow 程式碼時,有一些重要的注意事項。
Transform 組件的結果是一個 SavedModel,它將在 TensorFlow 中的模型建構程式碼中匯入和使用,在 Trainer 組件期間。此 SavedModel 包含在 Transform 組件中建立的所有資料工程轉換,以便在訓練和推論期間使用完全相同的程式碼執行相同的轉換。使用模型建構程式碼 (包括來自 Transform 組件的 SavedModel),您可以使用您的訓練和評估資料並訓練您的模型。
在使用基於 Estimator 的模型時,模型建構程式碼的最後一部分應將您的模型儲存為 SavedModel 和 EvalSavedModel。儲存為 EvalSavedModel 可確保訓練時使用的指標在評估期間也可用 (請注意,這對於基於 keras 的模型不是必需的)。儲存 EvalSavedModel 需要您在 Trainer 組件中匯入 TensorFlow Model Analysis (TFMA) 程式庫。
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
可以在 Trainer 之前新增選用的 Tuner 組件,以調整模型的超參數 (例如,層數)。在給定模型和超參數的搜尋空間的情況下,調整演算法將根據目標找到最佳超參數。
分析和理解模型效能
在初始模型開發和訓練之後,分析並真正理解模型的效能非常重要。典型的 TFX 管線將包含 Evaluator 組件,該組件利用 TensorFlow Model Analysis (TFMA) 程式庫的功能,該程式庫為此開發階段提供強大的工具組。Evaluator 組件使用您在上面匯出的模型,並允許您指定 tfma.SlicingSpec 列表,您可以在視覺化呈現和分析模型效能時使用。每個 SlicingSpec 定義您要檢查的訓練資料切片,例如分類特徵的特定類別或數值特徵的特定範圍。
例如,這對於嘗試理解您的模型在不同客戶群中的效能非常重要,這些客戶群可以按年購買額、地理資料、年齡組或性別細分。這對於長尾資料集尤其重要,在長尾資料集中,主要群體的效能可能會掩蓋重要但較小群體不可接受的效能。例如,您的模型對於一般員工可能表現良好,但對於高階主管人員則表現極差,而您可能需要知道這一點。
模型分析與視覺化呈現
在您完成資料通過訓練模型和在訓練結果上運行 Evaluator 組件 (TFMA) 的首次運行後,您可以在 Jupyter 風格的筆記本中視覺化呈現結果。對於其他運行,您可以在進行調整時比較這些結果,直到您的結果對您的模型和應用程式而言達到最佳狀態。
您將首先查詢 ML Metadata (MLMD) 以找到這些組件的執行結果,然後使用 TFMA 中的視覺化呈現支援 API 在您的筆記本中建立視覺化呈現。這包括 tfma.load_eval_results 和 tfma.view.render_slicing_metrics。使用此視覺化呈現,您可以更好地理解模型的特性,並在必要時進行修改。
驗證模型效能
作為分析模型效能的一部分,您可能想要針對基準線 (例如目前部署的模型) 驗證效能。模型驗證是通過將候選模型和基準模型都傳遞給 Evaluator 組件來執行的。Evaluator 計算候選模型和基準模型的指標 (例如 AUC、loss),以及對應的一組差異指標。然後可以應用閾值,並用於控制將模型推送到生產環境。
驗證模型是否可以部署
在部署已訓練的模型之前,您可能想要驗證模型是否真的可以在部署基礎架構中部署。這在生產環境中尤其重要,以確保新發布的模型不會阻止系統提供預測。InfraValidator 組件將在沙箱環境中對您的模型進行 Canary 部署,並選擇性地發送真實請求以檢查您的模型是否正常工作。
部署目標
一旦您開發和訓練了您滿意的模型,現在就可以將其部署到一個或多個部署目標,在這些目標中它將接收推論請求。TFX 支援部署到三種類型的部署目標。已匯出為 SavedModel 的已訓練模型可以部署到任何或所有這些部署目標。
推論:TensorFlow Serving
TensorFlow Serving (TFS) 是一個靈活、高效能的機器學習模型部署系統,專為生產環境設計。它使用 SavedModel,並將通過 REST 或 gRPC 介面接受推論請求。它在一個或多個網路伺服器上作為一組進程運行,使用多種先進架構之一來處理同步和分散式運算。如需更多關於開發和部署 TFS 解決方案的資訊,請參閱 TFS 文件。
在典型的管線中,在 Trainer 組件中訓練的 SavedModel 將首先在 InfraValidator 組件中進行基礎架構驗證。InfraValidator 啟動 Canary TFS 模型伺服器以實際部署 SavedModel。如果驗證通過,Pusher 組件最終會將 SavedModel 部署到您的 TFS 基礎架構。這包括處理多個版本和模型更新。
原生行動裝置和 IoT 應用程式中的推論:TensorFlow Lite
在 JavaScript 中進行推論:TensorFlow JS
使用 Airflow 建立 TFX Pipeline
請查看
使用 Kubeflow 建立 TFX Pipeline
設定
Kubeflow 需要 Kubernetes 叢集來大規模執行 pipelines。請參閱 Kubeflow 部署指南,其中引導您了解
設定和執行 TFX pipeline
請按照
pipeline 動作的命令列介面
TFX 提供了一個統一的 CLI,可協助執行全方位的 pipeline 動作,例如在各種協調器(包括 Apache Airflow、Apache Beam 和 Kubeflow)上建立、更新、執行、列出和刪除 pipeline。如需詳細資訊,請參閱