
一旦您的資料進入 TFX 管線,您就可以使用 TFX 元件來分析和轉換資料。您甚至可以在訓練模型之前使用這些工具。
分析和轉換資料的原因有很多
- 找出資料中的問題。常見問題包括
- 遺失資料,例如具有空白值的功能。
- 標籤被視為功能,因此您的模型可以在訓練期間搶先看到正確答案。
- 功能的值超出您預期的範圍。
- 資料異常。
- 轉移學習模型具有與訓練資料不符的預先處理。
- 設計更有效的功能集。例如,您可以識別
- 特別有用的功能。
- 多餘的功能。
- 尺度差異過大的功能,可能會減緩學習速度。
- 幾乎沒有或沒有獨特預測資訊的功能。
TFX 工具既可以協助尋找資料錯誤,也可以協助功能工程。
TensorFlow Data Validation
總覽
TensorFlow Data Validation 可識別訓練和服務資料中的異常,並可透過檢查資料自動建立結構描述。元件可以設定為偵測資料中不同類型的異常。它可以
- 藉由將資料統計資料與編纂使用者期望的結構描述進行比較,來執行有效性檢查。
- 藉由比較訓練和服務資料中的範例,偵測訓練-服務偏差。
- 藉由查看一系列資料來偵測資料漂移。
我們會個別記錄這些功能
以結構描述為基礎的範例驗證
TensorFlow Data Validation 藉由將資料統計資料與結構描述進行比較,來識別輸入資料中的任何異常。結構描述編纂輸入資料預期會滿足的屬性 (例如資料類型或類別值),並且可以由使用者修改或取代。
Tensorflow Data Validation 通常會在 TFX 管線的環境中多次叫用:(i) 針對從 ExampleGen 取得的每個分割,(ii) 針對 Transform 使用的所有預先轉換資料,以及 (iii) 針對 Transform 產生的所有後轉換資料。在 Transform (ii-iii) 的環境中叫用時,可以透過定義 stats_options_updater_fn 來設定統計資料選項和以結構描述為基礎的限制。這在驗證非結構化資料 (例如文字功能) 時特別有用。如需範例,請參閱使用者程式碼。
進階結構描述功能
本節涵蓋更進階的結構描述設定,可協助進行特殊設定。
稀疏功能
在範例中編碼稀疏功能通常會引入多個預期對所有範例具有相同價數的功能。例如,稀疏功能
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
稀疏功能定義需要一個或多個索引功能和一個值功能,這些功能會參照結構描述中存在的功能。明確定義稀疏功能可讓 TFDV 檢查所有參照功能的價數是否相符。
某些使用案例會在功能之間引入類似的價數限制,但不一定會編碼稀疏功能。使用稀疏功能應該可以解除您的封鎖,但並非理想做法。
結構描述環境
預設情況下,驗證會假設管線中的所有範例都遵守單一結構描述。在某些情況下,有必要引入輕微的結構描述變化,例如訓練期間需要用作標籤的功能 (且應經過驗證),但在服務期間會遺失。環境可用於表達此類需求,特別是 default_environment()、in_environment()、not_in_environment()。
例如,假設訓練需要名為 'LABEL' 的功能,但預期服務中會遺失。這可以透過以下方式表達
- 在結構描述中定義兩個不同的環境:["SERVING", "TRAINING"],並僅將 'LABEL' 與環境 "TRAINING" 建立關聯。
- 將訓練資料與環境 "TRAINING" 建立關聯,並將服務資料與環境 "SERVING" 建立關聯。
結構描述產生
輸入資料結構描述指定為 TensorFlow 結構描述的執行個體。
開發人員可以仰賴 TensorFlow Data Validation 的自動結構描述建構,而無需從頭開始手動建構結構描述。具體而言,TensorFlow Data Validation 會根據管線中可用的訓練資料統計資料自動建構初始結構描述。使用者可以簡單地檢閱此自動產生的結構描述、根據需要修改、簽入版本控制系統,並明確地將其推送至管線以進行進一步驗證。
TFDV 包含 infer_schema() 以自動產生結構描述。例如
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
這會根據下列規則觸發自動結構描述產生
如果結構描述已自動產生,則會按原樣使用。
否則,TensorFlow Data Validation 會檢查可用的資料統計資料,並計算適用於資料的結構描述。
注意:自動產生的結構描述是盡力而為,僅嘗試推斷資料的基本屬性。預期使用者會根據需要檢閱和修改。
訓練-服務偏差偵測
總覽
TensorFlow Data Validation 可以偵測訓練和服務資料之間的分配偏差。當訓練資料的功能值分配與服務資料顯著不同時,就會發生分配偏差。分配偏差的主要原因之一是使用完全不同的語料庫來產生訓練資料,以克服所需語料庫中初始資料的不足。另一個原因是錯誤的取樣機制,只選擇服務資料的子樣本進行訓練。
範例情境
如需設定訓練-服務偏差偵測的相關資訊,請參閱TensorFlow Data Validation 開始使用指南。
漂移偵測
資料漂移偵測支援連續資料跨度之間 (即跨度 N 和跨度 N+1 之間) 的偵測,例如不同日期的訓練資料之間。我們以類別功能的 L-infinity 距離和數值功能的近似 Jensen-Shannon 散度來表達漂移。您可以設定閾值距離,以便在漂移高於可接受程度時收到警告。設定正確的距離通常是需要領域知識和實驗的迭代過程。
如需設定漂移偵測的相關資訊,請參閱TensorFlow Data Validation 開始使用指南。
使用視覺化檢查您的資料
TensorFlow Data Validation 提供視覺化功能值分配的工具。藉由在 Jupyter Notebook 中使用 Facets 檢查這些分配,您可以捕捉到常見的資料問題。
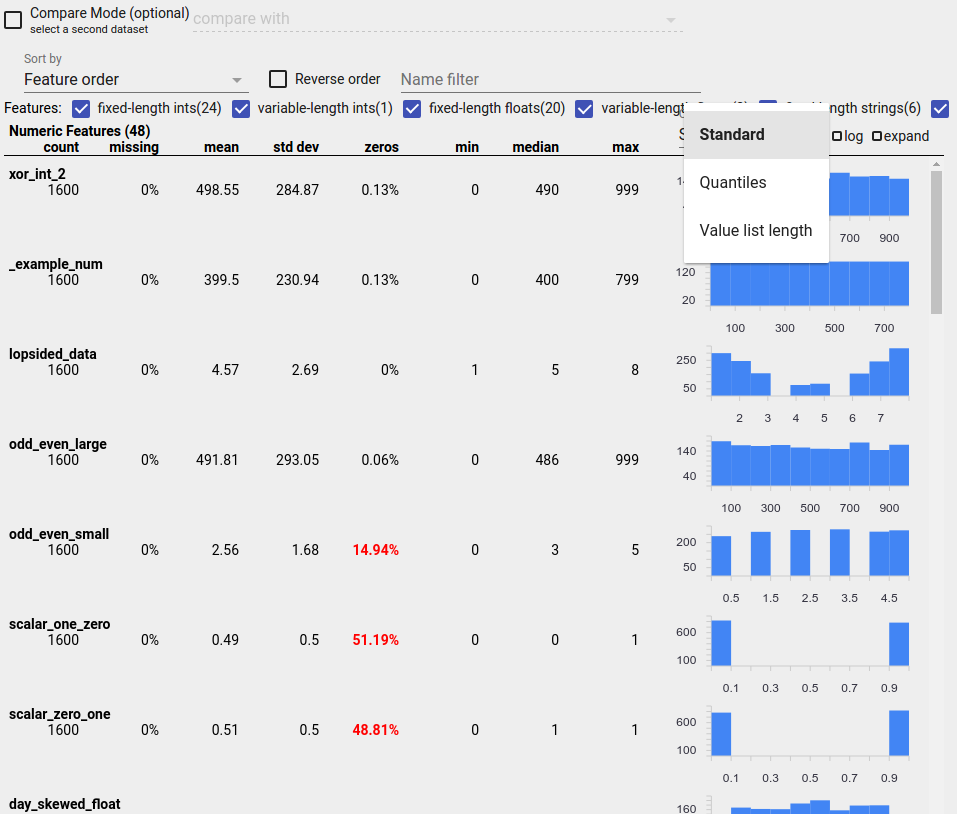
識別可疑的分配
您可以使用 Facets Overview 顯示畫面來尋找可疑的功能值分配,藉此識別資料中的常見錯誤。
不平衡資料
不平衡功能是指其中一個值佔主導地位的功能。不平衡功能可能會自然發生,但如果某個功能始終具有相同的值,則可能是資料錯誤。若要在 Facets Overview 中偵測不平衡功能,請從「排序依據」下拉式選單中選擇「不均勻性」。
最不平衡的功能將列在每個功能類型清單的頂端。例如,以下螢幕擷取畫面顯示一個全為零的功能,以及一個高度不平衡的功能,位於「數值功能」清單的頂端
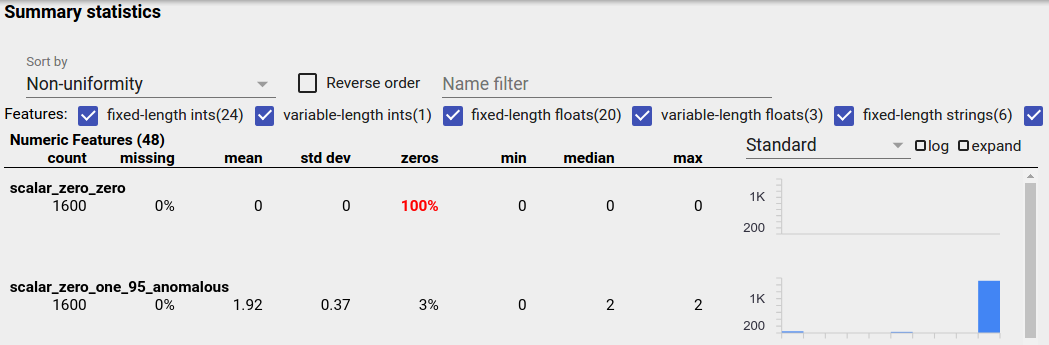
均勻分配資料
均勻分配功能是指所有可能的值以幾乎相同的頻率出現的功能。與不平衡資料一樣,此分配可能會自然發生,但也可能是由資料錯誤產生。
若要在 Facets Overview 中偵測均勻分配功能,請從「排序依據」下拉式選單中選擇「不均勻性」,然後勾選「反向順序」核取方塊
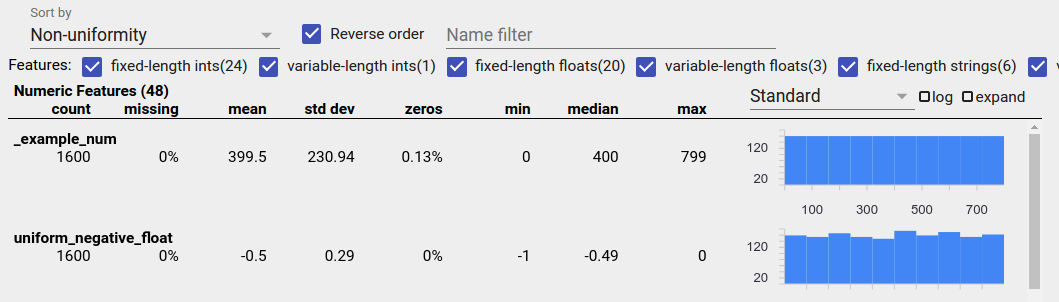
如果字串資料有 20 個或更少個唯一值,則會使用長條圖表示,如果超過 20 個唯一值,則會使用累積分配圖表示。因此,對於字串資料,均勻分配可能會顯示為類似上方的平面長條圖,或類似下方的直線

可能產生均勻分配資料的錯誤
以下是一些可能產生均勻分配資料的常見錯誤
使用字串來表示非字串資料類型,例如日期。例如,對於日期時間功能,您將會有很多唯一值,例如「2017-03-01-11-45-03」。唯一值將均勻分配。
將索引 (例如「列號碼」) 包含為功能。同樣地,您在這裡也有許多唯一值。
遺失資料
若要檢查功能是否完全遺失值
- 從「排序依據」下拉式選單中選擇「遺失/零值量」。
- 勾選「反向順序」核取方塊。
- 查看「遺失」欄以查看功能遺失值的執行個體百分比。
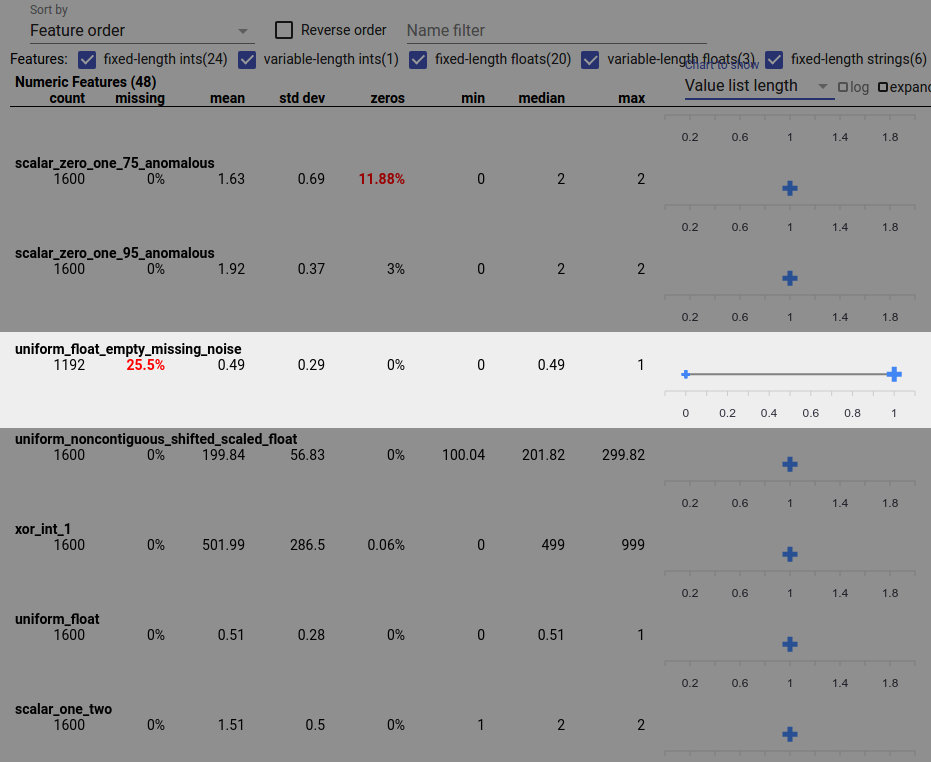
資料錯誤也可能導致不完整的功能值。例如,您可能會預期功能的值清單始終具有三個元素,但發現有時只有一個元素。若要檢查不完整的值或其他功能值清單不具有預期元素數量的案例
從右側的「要顯示的圖表」下拉式選單中選擇「值清單長度」。
查看每個功能列右側的圖表。圖表顯示功能的值清單長度範圍。例如,以下螢幕擷取畫面中醒目顯示的列顯示一個具有某些零長度值清單的功能
功能之間尺度差異過大
如果您的功能尺度差異過大,則模型可能難以學習。例如,如果某些功能的變動範圍為 0 到 1,而其他功能的變動範圍為 0 到 1,000,000,000,則您的尺度差異很大。比較跨功能的「最大值」和「最小值」欄,以尋找尺度差異過大的情況。
考慮正規化功能值以減少這些尺度差異過大的情況。
具有無效標籤的標籤
TensorFlow 的 Estimator 對於它們接受作為標籤的資料類型有限制。例如,二元分類器通常僅適用於 {0, 1} 標籤。
檢閱 Facets Overview 中的標籤值,並確保它們符合 Estimator 的需求。