
一般資訊
是否仍然需要 EvalSavedModel?
先前 TFMA 要求所有指標都必須使用特殊的 EvalSavedModel 儲存在 tensorflow 圖表中。現在,指標可以使用 beam.CombineFn 實作在 TF 圖表外計算。
主要差異包括
EvalSavedModel需要從訓練器匯出特殊項目,而服務模型則可直接使用,無需變更訓練程式碼。- 使用
EvalSavedModel時,訓練時新增的任何指標都會在評估時自動提供。若未使用EvalSavedModel,則必須重新新增這些指標。- 此規則的例外情況是,如果使用 keras 模型,指標也會自動新增,因為 keras 會將指標資訊與儲存的模型一起儲存。
TFMA 是否可搭配圖表內指標和外部指標運作?
TFMA 允許使用混合方法,其中某些指標可在圖表內計算,而其他指標則可在圖表外計算。如果您目前有 EvalSavedModel,則可繼續使用。
有兩種情況
- 將 TFMA
EvalSavedModel用於特徵擷取和指標計算,同時也新增以組合器為基礎的其他指標。在這種情況下,您會從EvalSavedModel取得所有圖表內指標,以及可能先前不支援的以組合器為基礎的其他指標。 - 將 TFMA
EvalSavedModel用於特徵/預測擷取,但使用以組合器為基礎的指標進行所有指標計算。如果EvalSavedModel中存在您想要用於分區的特徵轉換,但偏好在圖表外執行所有指標計算,則此模式非常實用。
設定
支援哪些模型類型?
TFMA 支援 keras 模型、以一般 TF2 簽名 API 為基礎的模型,以及以 TF 估算器為基礎的模型 (雖然視使用案例而定,以估算器為基礎的模型可能需要使用 EvalSavedModel)。
請參閱入門指南,瞭解支援的所有模型類型和任何限制。
如何設定 TFMA 以搭配原生 keras 型模型運作?
以下是以 keras 模型為基礎的範例設定,其依據下列假設
- 儲存的模型用於服務,並使用簽名名稱
serving_default(可以使用model_specs[0].signature_name變更此名稱)。 - 應評估
model.compile(...)的內建指標 (可以使用 tfma.EvalConfig 中的options.include_default_metric停用此評估)。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
請參閱指標,瞭解可設定的其他指標類型。
如何設定 TFMA 以搭配一般 TF2 簽名型模型運作?
以下是一般 TF2 模型的範例設定。在下方,signature_name 是應該用於評估的特定簽名名稱。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
請參閱指標,瞭解可設定的其他指標類型。
如何設定 TFMA 以搭配估算器型模型運作?
在這種情況下,有三種選擇。
選項 1:使用服務模型
如果使用此選項,則訓練期間新增的任何指標將不會包含在評估中。
以下是假設 serving_default 是所用簽名名稱的範例設定
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
請參閱指標,瞭解可設定的其他指標類型。
選項 2:搭配以組合器為基礎的其他指標使用 EvalSavedModel
在這種情況下,同時使用 EvalSavedModel 進行特徵/預測擷取和評估,並新增以組合器為基礎的其他指標。
以下是範例設定
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
請參閱指標,瞭解可設定的其他指標類型,並參閱EvalSavedModel,瞭解設定 EvalSavedModel 的詳細資訊。
選項 3:僅將 EvalSavedModel 模型用於特徵/預測擷取
與選項 (2) 類似,但僅使用 EvalSavedModel 進行特徵/預測擷取。如果只需要外部指標,但有您想要分區的特徵轉換,則此選項非常實用。與選項 (1) 類似,訓練期間新增的任何指標將不會包含在評估中。
在這種情況下,設定與上述相同,只是停用了 include_default_metrics。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
請參閱指標,瞭解可設定的其他指標類型,並參閱EvalSavedModel,瞭解設定 EvalSavedModel 的詳細資訊。
如何設定 TFMA 以搭配 keras model-to-estimator 型模型運作?
keras model_to_estimator 設定與估算器設定類似。不過,model-to-estimator 的運作方式有一些特定差異。特別是,model-to-esimtator 會以字典形式傳回其輸出,其中字典鍵是相關 keras 模型中最後一個輸出層的名稱 (如果未提供名稱,keras 會為您選擇預設名稱,例如 dense_1 或 output_1)。從 TFMA 的角度來看,即使模型轉估算器可能僅適用於單一模型,此行為也類似於多輸出模型會輸出的內容。為了考量此差異,需要額外步驟來設定輸出名稱。不過,與估算器相同的三個選項都適用。
以下是以估算器為基礎的設定所需變更範例
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
如何設定 TFMA 以搭配預先計算的 (即模型不可知的) 預測運作?(TFRecord 和 tf.Example)
為了設定 TFMA 以搭配預先計算的預測運作,必須停用預設的 tfma.PredictExtractor,且必須設定 tfma.InputExtractor 以剖析預測以及其他輸入特徵。這可透過使用用於預測的特徵索引鍵名稱以及標籤和權重來設定 tfma.ModelSpec 來完成。
以下是範例設定
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
請參閱指標,瞭解可設定的指標詳細資訊。
請注意,雖然正在設定 tfma.ModelSpec,但實際上並未使用模型 (即沒有 tfma.EvalSharedModel)。執行模型分析的呼叫可能如下所示
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
如何設定 TFMA 以搭配預先計算的 (即模型不可知的) 預測運作?(pd.DataFrame)
對於可放入記憶體的小型資料集,TFRecord 的替代方案是 pandas.DataFrame。TFMA 可以使用 tfma.analyze_raw_data API 在 pandas.DataFrame 上運作。如需 tfma.MetricsSpec 和 tfma.SlicingSpec 的說明,請參閱設定指南。請參閱指標,瞭解可設定的指標詳細資訊。
以下是範例設定
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
指標
支援哪些指標類型?
TFMA 支援各種指標,包括
是否支援多輸出模型中的指標?
是。請參閱指標指南,瞭解更多詳細資訊。
是否支援多模型中的指標?
是。請參閱指標指南,瞭解更多詳細資訊。
指標設定 (名稱等) 是否可自訂?
是。指標設定可以自訂 (例如,設定特定門檻等),方法是在指標設定中新增 config 設定。請參閱指標指南,瞭解更多詳細資訊。
是否支援自訂指標?
是。方法是撰寫自訂 tf.keras.metrics.Metric 實作,或撰寫自訂 beam.CombineFn 實作。指標指南提供更多詳細資訊。
不支援哪些指標類型?
只要您的指標可以使用 beam.CombineFn 計算,對於可以根據 tfma.metrics.Metric 計算的指標類型就沒有限制。如果使用衍生自 tf.keras.metrics.Metric 的指標,則必須符合下列條件
- 應可針對每個範例獨立計算指標的充分統計量,然後將這些充分統計量相加,跨所有範例結合這些統計量,並僅根據這些充分統計量判斷指標值。
- 例如,對於準確度,充分統計量為「總正確數」和「範例總數」。可以針對個別範例計算這兩個數字,並將其加總以取得一組範例的正確值。最終準確度可以使用「總正確數/範例總數」計算。
附加元件
我可以使用 TFMA 評估模型中的公平性或偏見嗎?
TFMA 包含 FairnessIndicators 附加元件,可提供匯出後指標,以評估分類模型中非預期偏見的影響。
自訂
如果我需要更多自訂功能,該怎麼辦?
TFMA 非常彈性,可讓您使用自訂 Extractors、Evaluators 和/或 Writers 自訂管線的幾乎所有部分。架構文件中更詳細地討論了這些抽象概念。
疑難排解、偵錯和取得協助
為什麼 MultiClassConfusionMatrix 指標與二元 ConfusionMatrix 指標不符
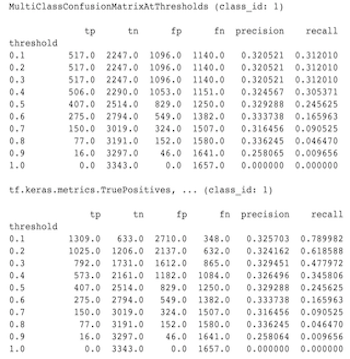
這些實際上是不同的計算。二元化會針對每個類別 ID 獨立執行比較 (即,每個類別的預測會與提供的門檻個別比較)。在這種情況下,可能有兩個或多個類別都表示它們符合預測,因為它們的預測值大於門檻 (在較低門檻下,情況會更明顯)。在多類別混淆矩陣的情況下,仍然只有一個真正的預測值,而且它符合實際值或不符合實際值。門檻僅用於在預測小於門檻時強制預測與任何類別都不符。門檻越高,二元化類別的預測就越難符合。同樣地,門檻越低,二元化類別的預測就越容易符合。這表示在門檻 > 0.5 時,二元化值和多類別矩陣值會更接近對齊,而在門檻 < 0.5 時,它們會更遠。
例如,假設我們有 10 個類別,其中類別 2 的預測機率為 0.8,但實際類別為類別 1,其機率為 0.15。如果您對類別 1 進行二元化並使用 0.1 的門檻,則類別 1 會被視為正確 (0.15 > 0.1),因此會計為 TP。但是,對於多類別情況,類別 2 會被視為正確 (0.8 > 0.1),且由於類別 1 是實際類別,因此會計為 FN。由於在較低門檻下,更多值會被視為正數,因此一般而言,二元化混淆矩陣的 TP 和 FP 計數會高於多類別混淆矩陣,而 TN 和 FN 計數會較低。
以下是觀察到的 MultiClassConfusionMatrixAtThresholds 與其中一個類別二元化對應計數之間差異的範例。
為什麼我的 precision@1 和 recall@1 指標具有相同的值?
在 k 值上限為 1 時,精確度和召回率是相同的。TP / (TP + FP) 的精確度與 TP / (TP + FN) 的召回率相等。最上層預測一律為正數,且會符合或不符合標籤。換句話說,使用 N 個範例時,TP + FP = N。但是,如果標籤不符合最上層預測,則這也表示符合非最上層 k 預測,且在最上層 k 設定為 1 的情況下,所有非最上層 1 預測都會為 0。這表示 FN 必須為 (N - TP) 或 N = TP + FN。最終結果是 precision@1 = TP / N = recall@1。請注意,這僅適用於每個範例有一個標籤的情況,不適用於多標籤。
為什麼我的 mean_label 和 mean_prediction 指標始終為 0.5?
這很可能是因為指標是針對二元分類問題設定的,但模型輸出的是兩個類別的機率,而不只是一個類別的機率。當使用 tensorflow 的分類 API 時,這很常見。解決方案是選擇您想要預測依據的類別,然後對該類別進行二元化。例如
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
如何解讀 MultiLabelConfusionMatrixPlot?
給定特定標籤,MultiLabelConfusionMatrixPlot (和相關的 MultiLabelConfusionMatrix) 可用於比較其他標籤的結果及其預測,當選取的標籤實際上為真時。例如,假設我們有三個類別:bird、plane 和 superman,而且我們正在分類圖片,以指出圖片是否包含其中一個或多個類別。MultiLabelConfusionMatrix 會計算每個實際類別與其他每個類別 (稱為預測類別) 的笛卡兒乘積。請注意,雖然配對是 (actual, predicted),但 predicted 類別不一定表示正數預測,它僅表示實際與預測矩陣中的預測欄。例如,假設我們已計算下列矩陣
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot 有三種方式可顯示此資料。在所有情況下,從實際類別的角度來看,讀取表格的方式都是逐列讀取。
1) 總預測計數
在這種情況下,針對給定列 (即實際類別),其他類別的 TP + FP 計數是多少。對於上述計數,我們的顯示方式如下
| 預測 bird | 預測 plane | 預測 superman | |
|---|---|---|---|
| 實際 bird | 6 | 4 | 2 |
| 實際 plane | 4 | 4 | 4 |
| 實際 superman | 5 | 5 | 4 |
當圖片實際上包含 bird 時,我們正確預測了 6 個。同時,我們也預測 plane (正確或錯誤) 4 次,以及 superman (正確或錯誤) 2 次。
2) 不正確預測計數
在這種情況下,針對給定列 (即實際類別),其他類別的 FP 計數是多少。對於上述計數,我們的顯示方式如下
| 預測 bird | 預測 plane | 預測 superman | |
|---|---|---|---|
| 實際 bird | 0 | 2 | 1 |
| 實際 plane | 1 | 0 | 3 |
| 實際 superman | 2 | 3 | 0 |
當圖片實際上包含 bird 時,我們錯誤地預測 plane 2 次和 superman 1 次。
3) 偽陰性計數
在這種情況下,針對給定列 (即實際類別),其他類別的 FN 計數是多少。對於上述計數,我們的顯示方式如下
| 預測 bird | 預測 plane | 預測 superman | |
|---|---|---|---|
| 實際 bird | 2 | 2 | 4 |
| 實際 plane | 1 | 4 | 3 |
| 實際 superman | 2 | 2 | 5 |
當圖片實際上包含 bird 時,我們未能預測到它 2 次。同時,我們未能預測到 plane 2 次和 superman 4 次。
為什麼我會收到關於找不到預測金鑰的錯誤?
有些模型的輸出會以字典形式呈現其預測。例如,二元分類問題的 TF 估算器會輸出包含 probabilities、class_ids 等的字典。在大多數情況下,TFMA 具有尋找常用金鑰名稱的預設值,例如 predictions、probabilities 等。但是,如果您的模型非常自訂,則可能會在 TFMA 不知道的名稱下輸出金鑰。在這些情況下,必須將 prediciton_key 設定新增至 tfma.ModelSpec,以識別輸出儲存在哪個金鑰名稱下。