
總覽
TensorFlow 模型分析 (TFMA) 管道的描繪方式如下
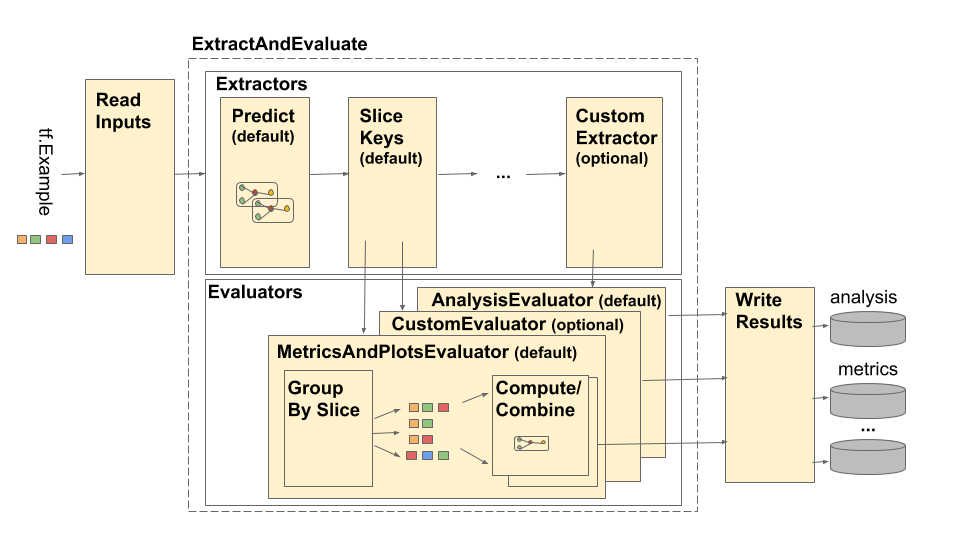
管道由四個主要元件組成
- 讀取輸入
- 擷取
- 評估
- 寫入結果
這些元件使用兩種主要類型:tfma.Extracts 和 tfma.evaluators.Evaluation。tfma.Extracts 類型代表在管道處理期間擷取的資料,而且可能對應於模型的一個或多個範例。tfma.evaluators.Evaluation 代表評估擷取內容在擷取過程各個點的輸出。為了提供彈性的 API,這些類型只是 dict,其中的鍵由不同的實作定義 (保留供使用)。這些類型的定義如下
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
請注意,tfma.Extracts 永遠不會直接寫出,它們必須一律經過評估器,才能產生 tfma.evaluators.Evaluation,然後再寫出。另請注意,tfma.Extracts 是儲存在 beam.pvalue.PCollection 中的 dict (也就是 beam.PTransform 會將 beam.pvalue.PCollection[tfma.Extracts] 做為輸入),而 tfma.evaluators.Evaluation 是一個 dict,其值為 beam.pvalue.PCollection (也就是 beam.PTransform 會將 dict 本身做為 beam.value.PCollection 輸入的引數)。換句話說,tfma.evaluators.Evaluation 是在管道建構時間使用,但 tfma.Extracts 是在管道執行階段使用。
讀取輸入
ReadInputs 階段是由轉換組成,該轉換會接收原始輸入 (tf.train.Example、CSV 等),並將它們轉換為擷取內容。目前擷取內容是以原始輸入位元組的形式表示,並儲存在 tfma.INPUT_KEY 下,但擷取內容可以是與擷取管道相容的任何形式,也就是說,它會建立 tfma.Extracts 做為輸出,而且這些擷取內容與下游擷取器相容。不同的擷取器必須清楚記錄它們的需求。
擷取
擷取程序是一系列依序執行的 beam.PTransform。tfma.Extracts 擷取器會將 tfma.Extracts 做為輸入,並傳回 tfma.Extracts 做為輸出。原型擷取器是 tfma.extractors.PredictExtractor,它會使用讀取輸入轉換產生的輸入擷取內容,並透過模型執行以產生預測擷取內容。自訂擷取器可以插入在任何點,前提是它們的轉換符合 tfma.Extracts 輸入和 tfma.Extracts 輸出 API。擷取器的定義如下
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
InputExtractor
tfma.extractors.InputExtractor 用於從 tf.train.Example 記錄擷取原始特徵、原始標籤和原始範例權重,以用於指標分區和計算。根據預設,這些值會儲存在擷取鍵 features、labels 和 example_weights 下。單一輸出模型標籤和範例權重會直接儲存為 np.ndarray 值。多重輸出模型標籤和範例權重會儲存為 np.ndarray 值的 dict (以輸出名稱做為鍵)。如果執行多模型評估,標籤和範例權重會進一步嵌入在另一個 dict 內 (以模型名稱做為鍵)。
PredictExtractor
tfma.extractors.PredictExtractor 執行模型預測,並將它們儲存在 tfma.Extracts dict 中的 predictions 鍵下。單一輸出模型預測會直接儲存為預測輸出值。多重輸出模型預測會儲存為輸出值 dict (以輸出名稱做為鍵)。如果執行多模型評估,預測會進一步嵌入在另一個 dict 內 (以模型名稱做為鍵)。使用的實際輸出值取決於模型 (例如,TF 估算器以 dict 形式傳回輸出,而 keras 則傳回 np.ndarray 值)。
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor 使用分區規格,根據擷取的特徵判斷哪些分區適用於每個範例輸入,並將對應的分區值新增至擷取內容,以供評估器稍後使用。
評估
評估是取得擷取內容並評估它的程序。雖然在擷取管道結束時執行評估很常見,但有些使用案例需要在擷取程序中較早執行評估。因此,評估器會與擷取器建立關聯,評估器應根據這些擷取器的輸出進行評估。評估器的定義如下
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
請注意,評估器是將 tfma.Extracts 做為輸入的 beam.PTransform。實作可以對擷取內容執行額外轉換,做為評估程序的一部分,這沒有任何限制。與必須傳回 tfma.Extracts dict 的擷取器不同,評估器可以產生的輸出類型沒有限制,不過大多數評估器也會傳回 dict (例如,指標名稱和值)。
MetricsAndPlotsEvaluator
tfma.evaluators.MetricsAndPlotsEvaluator 接收 features、labels 和 predictions 做為輸入,透過 tfma.slicer.FanoutSlices 執行它們以依分區分組,然後執行指標和繪圖計算。它會以指標和繪圖鍵和值的字典形式產生輸出 (這些稍後會轉換為序列化 proto,以供 tfma.writers.MetricsAndPlotsWriter 輸出)。
寫入結果
WriteResults 階段是評估輸出寫出到磁碟的位置。WriteResults 使用寫入器,根據輸出鍵寫出資料。例如,tfma.evaluators.Evaluation 可能包含 metrics 和 plots 的鍵。然後,這些會與名為「metrics」和「plots」的指標和繪圖字典建立關聯。寫入器會指定如何寫出每個檔案
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
我們提供 tfma.writers.MetricsAndPlotsWriter,它會將指標和繪圖字典轉換為序列化 proto,並將它們寫入磁碟。
如果您想要使用不同的序列化格式,您可以建立自訂寫入器並改用該寫入器。由於傳遞至寫入器的 tfma.evaluators.Evaluation 包含所有評估器的組合輸出,因此提供了 tfma.writers.Write 輔助轉換,寫入器可以在其 ptransform 實作中使用,以根據輸出鍵選取適當的 beam.PCollection (請參閱下方的範例)。
自訂
tfma.run_model_analysis 方法採用 extractors、evaluators 和 writers 引數,用於自訂管道使用的擷取器、評估器和寫入器。如果未提供任何引數,則預設會使用 tfma.default_extractors、tfma.default_evaluators 和 tfma.default_writers。
自訂擷取器
若要建立自訂擷取器,請建立 tfma.extractors.Extractor 類型,它會包裝 beam.PTransform,將 tfma.Extracts 做為輸入並傳回 tfma.Extracts 做為輸出。擷取器範例可在 tfma.extractors 下取得。
自訂評估器
若要建立自訂評估器,請建立 tfma.evaluators.Evaluator 類型,它會包裝 beam.PTransform,將 tfma.Extracts 做為輸入並傳回 tfma.evaluators.Evaluation 做為輸出。非常基本的評估器可能只會接收傳入的 tfma.Extracts,並輸出它們以儲存在表格中。這正是 tfma.evaluators.AnalysisTableEvaluator 的用途。更複雜的評估器可能會執行額外的處理和資料彙總。請參閱 tfma.evaluators.MetricsAndPlotsEvaluator 做為範例。
請注意,tfma.evaluators.MetricsAndPlotsEvaluator 本身可以自訂,以支援自訂指標 (如需詳細資訊,請參閱指標)。
自訂寫入器
若要建立自訂寫入器,請建立 tfma.writers.Writer 類型,它會包裝 beam.PTransform,將 tfma.evaluators.Evaluation 做為輸入並傳回 beam.pvalue.PDone 做為輸出。以下是寫出包含指標之 TFRecords 的寫入器基本範例
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
寫入器的輸入取決於相關評估器的輸出。以上述範例而言,輸出是由 tfma.evaluators.MetricsAndPlotsEvaluator 產生的序列化 proto。tfma.evaluators.AnalysisTableEvaluator 的寫入器會負責寫出 tfma.Extracts 的 beam.pvalue.PCollection。
請注意,寫入器會透過使用的輸出鍵 (例如 tfma.METRICS_KEY、tfma.ANALYSIS_KEY 等) 與評估器的輸出建立關聯。
逐步範例
以下範例說明當同時使用 tfma.evaluators.MetricsAndPlotsEvaluator 和 tfma.evaluators.AnalysisTableEvaluator 時,擷取和評估管道中涉及的步驟
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files