
ExampleGen TFX 管道元件會將資料擷取到 TFX 管道中。它會取用外部檔案/服務來產生範例,其他 TFX 元件將會讀取這些範例。它也提供一致且可設定的分割區,並為 ML 最佳做法隨機調整資料集。
- 取用:來自外部資料來源 (例如 CSV、
TFRecord、Avro、Parquet 和 BigQuery) 的資料。 - 發出:
tf.Example記錄、tf.SequenceExample記錄或 Proto 格式,取決於酬載格式。
ExampleGen 和其他元件
ExampleGen 為使用 TensorFlow 資料驗證程式庫的元件 (例如 SchemaGen、StatisticsGen 和 Example Validator) 提供資料。它也為 Transform 提供資料,後者使用 TensorFlow Transform 程式庫,並最終在推論期間提供給部署目標。
資料來源和格式
目前 TFX 的標準安裝包含適用於下列資料來源和格式的完整 ExampleGen 元件
自訂執行器也適用,可為下列資料來源和格式開發 ExampleGen 元件
如要進一步瞭解如何使用及開發自訂執行器,請參閱原始碼和這項討論中的使用範例。
此外,下列資料來源和格式以自訂元件範例的形式提供
擷取 Apache Beam 支援的資料格式
Apache Beam 支援從廣泛的資料來源和格式擷取資料 (請參閱下文)。這些功能可用於為 TFX 建立自訂 ExampleGen 元件,一些現有的 ExampleGen 元件已展示此功能 (請參閱下文)。
如何使用 ExampleGen 元件
對於支援的資料來源 (目前為 CSV 檔案、具有 tf.Example、tf.SequenceExample 和 Proto 格式的 TFRecord 檔案,以及 BigQuery 查詢的結果),ExampleGen 管道元件可以直接在部署中使用,而且幾乎不需要自訂。例如:
example_gen = CsvExampleGen(input_base='data_root')
或者如下所示,直接匯入具有 tf.Example 的外部 TFRecord
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
跨度、版本和分割
跨度是訓練範例的分組。如果您的資料持續儲存在檔案系統上,則每個跨度可能會儲存在不同的目錄中。跨度的語意並未硬式編碼到 TFX 中;跨度可能對應於一天的資料、一小時的資料,或對您的工作有意義的任何其他分組。
每個跨度可以容納多個資料版本。舉例來說,如果您從跨度中移除一些範例以清理品質不佳的資料,可能會產生該跨度的新版本。根據預設,TFX 元件會在跨度內最新的版本上運作。
跨度內的每個版本可以進一步細分為多個分割。分割跨度最常見的用途是將其分割為訓練和評估資料。
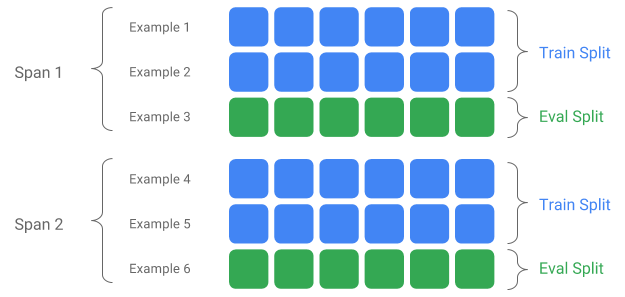
自訂輸入/輸出分割
如要自訂 ExampleGen 將輸出的訓練/評估分割比例,請為 ExampleGen 元件設定 output_config。例如:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
請注意在此範例中 hash_buckets 的設定方式。
對於已分割的輸入來源,請為 ExampleGen 元件設定 input_config
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
對於以檔案為基礎的範例產生器 (例如 CsvExampleGen 和 ImportExampleGen),pattern 是相對應於輸入檔案的 glob 相對檔案模式,根目錄由輸入基本路徑指定。對於以查詢為基礎的範例產生器 (例如 BigQueryExampleGen、PrestoExampleGen),pattern 是 SQL 查詢。
根據預設,整個輸入基本目錄會被視為單一輸入分割,而訓練和評估輸出分割會以 2:1 的比例產生。
如需 ExampleGen 的輸入和輸出分割設定,請參閱 proto/example_gen.proto。如需下游元件如何運用自訂分割,請參閱下游元件指南。
分割方法
使用 hash_buckets 分割方法時,除了整個記錄之外,也可以使用特徵來分割範例。如果特徵存在,ExampleGen 會使用該特徵的指紋作為分割金鑰。
此功能可用於針對範例的特定屬性維持穩定的分割:例如,如果選取「user_id」作為分割特徵名稱,則使用者將始終被放入相同的分割中。
「特徵」的含義以及如何將「特徵」與指定的名稱相符的解讀方式取決於 ExampleGen 實作和範例類型。
對於現成的 ExampleGen 實作
- 如果產生 tf.Example,則「特徵」表示 tf.Example.features.feature 中的項目。
- 如果產生 tf.SequenceExample,則「特徵」表示 tf.SequenceExample.context.feature 中的項目。
- 僅支援 int64 和位元組特徵。
在下列情況下,ExampleGen 會擲回執行階段錯誤
- 指定的特徵名稱在範例中不存在。
- 空白特徵:
tf.train.Feature()。 - 不支援的特徵類型,例如浮點特徵。
如要根據範例中的特徵輸出訓練/評估分割,請為 ExampleGen 元件設定 output_config。例如:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
請注意在此範例中 partition_feature_name 的設定方式。
跨度
跨度可以透過在輸入 glob 模式中使用 '{SPAN}' 規格來擷取
- 此規格會比對數字,並將資料對應到相關的跨度編號。例如,'data_{SPAN}-*.tfrecord' 將收集類似 'data_12-a.tfrecord'、'data_12-b.tfrecord' 的檔案。
- 您可以選擇性地指定此規格的整數寬度 (在對應時)。例如,'data_{SPAN:2}.file' 會對應到類似 'data_02.file' 和 'data_27.file' 的檔案 (分別作為跨度 2 和跨度 27 的輸入),但不會對應到 'data_1.file' 或 'data_123.file'。
- 如果缺少 SPAN 規格,則假設跨度始終為 '0'。
- 如果指定了 SPAN,管道將處理最新的跨度,並將跨度編號儲存在中繼資料中。
例如,假設有輸入資料
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
輸入設定如下所示
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
當觸發管道時,它將處理
- '/tmp/span-2/train/data' 作為訓練分割
- '/tmp/span-2/eval/data' 作為評估分割
跨度編號為 '2'。如果稍後 '/tmp/span-3/...' 準備就緒,只需再次觸發管道,它就會提取跨度 '3' 進行處理。以下顯示使用跨度規格的程式碼範例
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
可以使用 RangeConfig 擷取特定跨度,詳情如下。
日期
如果您的資料來源依日期在檔案系統上組織,則 TFX 支援將日期直接對應到跨度編號。有三個規格可表示從日期到跨度的對應:{YYYY}、{MM} 和 {DD}
- 如果指定了任何規格,則這三個規格應全部出現在輸入 glob 模式中
- SPAN 規格或這組日期規格只能擇一指定。
- 系統會計算日曆日期 (年取自 YYYY,月取自 MM,日取自 DD),然後將跨度編號計算為自 Unix 紀元 (即 1970-01-01) 以來的日數。例如,'log-{YYYY}{MM}{DD}.data' 會比對到檔案 'log-19700101.data',並將其作為跨度 0 的輸入取用,而 'log-20170101.data' 則作為跨度 17167 的輸入取用。
- 如果指定了這組日期規格,管道將處理最新的日期,並將對應的跨度編號儲存在中繼資料中。
例如,假設有依日曆日期組織的輸入資料
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
輸入設定如下所示
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
當觸發管道時,它將處理
- '/tmp/1970-01-03/train/data' 作為訓練分割
- '/tmp/1970-01-03/eval/data' 作為評估分割
跨度編號為 '2'。如果稍後 '/tmp/1970-01-04/...' 準備就緒,只需再次觸發管道,它就會提取跨度 '3' 進行處理。以下顯示使用日期規格的程式碼範例
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
版本
版本可以透過在輸入 glob 模式中使用 '{VERSION}' 規格來擷取
- 此規格會比對數字,並將資料對應到 SPAN 下的相關 VERSION 編號。請注意,版本規格可以與跨度或日期規格結合使用。
- 此規格也可以選擇性地指定寬度,方式與 SPAN 規格相同。例如 'span-{SPAN}/version-{VERSION:4}/data-*'。
- 如果缺少 VERSION 規格,則版本會設定為 None。
- 如果同時指定了 SPAN 和 VERSION,管道將處理最新跨度的最新版本,並將版本編號儲存在中繼資料中。
- 如果指定了 VERSION,但未指定 SPAN (或日期規格),則會擲回錯誤。
例如,假設有輸入資料
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
輸入設定如下所示
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
當觸發管道時,它將處理
- '/tmp/span-2/ver-2/train/data' 作為訓練分割
- '/tmp/span-2/ver-2/eval/data' 作為評估分割
跨度編號為 '2',版本編號為 '2'。如果稍後 '/tmp/span-2/ver-3/...' 準備就緒,只需再次觸發管道,它就會提取跨度 '2' 和版本 '3' 進行處理。以下顯示使用版本規格的程式碼範例
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
範圍設定
TFX 支援使用範圍設定 (用於描述不同 TFX 實體的範圍的抽象設定) 在以檔案為基礎的 ExampleGen 中擷取和處理特定跨度。如要擷取特定跨度,請為以檔案為基礎的 ExampleGen 元件設定 range_config。例如,假設有輸入資料
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
如要明確擷取和處理跨度 '1' 的資料,除了輸入設定之外,我們還需指定範圍設定。請注意,ExampleGen 僅支援單一跨度靜態範圍 (指定處理特定個別跨度)。因此,對於 StaticRange,start_span_number 必須等於 end_span_number。ExampleGen 將使用提供的跨度,以及用於零填充的跨度寬度資訊 (如果已提供),以所需跨度編號取代提供的分割模式中的 SPAN 規格。以下顯示使用範例
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
如果使用日期規格而非 SPAN 規格,範圍設定也可用於處理特定日期。例如,假設有依日曆日期組織的輸入資料
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
如要明確擷取和處理 1970 年 1 月 2 日的資料,我們執行以下操作
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
自訂 ExampleGen
如果目前可用的 ExampleGen 元件不符合您的需求,您可以建立自訂 ExampleGen,讓您能夠從不同的資料來源或以不同的資料格式讀取資料。
以檔案為基礎的 ExampleGen 自訂 (實驗性)
首先,使用自訂 Beam PTransform 擴充 BaseExampleGenExecutor,它提供從您的訓練/評估輸入分割到 TF 範例的轉換。例如,CsvExampleGen 執行器提供從輸入 CSV 分割到 TF 範例的轉換。
然後,使用上述執行器建立元件,如 CsvExampleGen 元件中所述。或者,將自訂執行器傳遞到標準 ExampleGen 元件,如下所示。
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
現在,我們也支援使用此方法讀取 Avro 和 Parquet 檔案。
其他資料格式
Apache Beam 支援透過 Beam I/O 轉換讀取許多其他資料格式。您可以使用類似於 Avro 範例的模式,透過利用 Beam I/O 轉換來建立自訂 ExampleGen 元件
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
在撰寫本文時,目前 Beam Python SDK 支援的格式和資料來源包括
- Amazon S3
- Apache Avro
- Apache Hadoop
- Apache Kafka
- Apache Parquet
- Google Cloud BigQuery
- Google Cloud BigTable
- Google Cloud Datastore
- Google Cloud Pub/Sub
- Google Cloud Storage (GCS)
- MongoDB
請查看 Beam 文件以取得最新清單。
以查詢為基礎的 ExampleGen 自訂 (實驗性)
首先,使用自訂 Beam PTransform 擴充 BaseExampleGenExecutor,它從外部資料來源讀取資料。然後,透過擴充 QueryBasedExampleGen 建立簡單的元件。
這可能需要或不需要額外的連線設定。例如,BigQuery 執行器使用預設的 beam.io 連接器讀取資料,後者抽象化連線設定詳細資料。Presto 執行器需要自訂 Beam PTransform 和 自訂連線設定 protobuf 作為輸入。
如果自訂 ExampleGen 元件需要連線設定,請建立新的 protobuf 並透過 custom_config 傳入,custom_config 現在是選用的執行參數。以下範例說明如何使用已設定的元件。
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
ExampleGen 下游元件
下游元件支援自訂分割設定。
StatisticsGen
預設行為是針對所有分割執行統計資料產生。
如要排除任何分割,請為 StatisticsGen 元件設定 exclude_splits。例如:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
預設行為是根據所有分割產生結構描述。
如要排除任何分割,請為 SchemaGen 元件設定 exclude_splits。例如:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ExampleValidator
預設行為是根據結構描述驗證輸入範例上所有分割的統計資料。
如要排除任何分割,請為 ExampleValidator 元件設定 exclude_splits。例如:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Transform
預設行為是從 'train' 分割分析和產生中繼資料,並轉換所有分割。
如要指定分析分割和轉換分割,請為 Transform 元件設定 splits_config。例如:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Trainer 和 Tuner
預設行為是在 'train' 分割上訓練,並在 'eval' 分割上評估。
如要指定訓練分割和評估分割,請為 Trainer 元件設定 train_args 和 eval_args。例如:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Evaluator
預設行為是提供在 'eval' 分割上計算的指標。
如要在自訂分割上計算評估統計資料,請為 Evaluator 元件設定 example_splits。例如:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
如需更多詳細資料,請參閱 CsvExampleGen API 參考資料、FileBasedExampleGen API 實作和 ImportExampleGen API 參考資料。