
TensorFlow Data Validation (TFDV) 可以分析訓練和服務資料,以執行下列作業:
核心 API 支援各項功能,並提供以核心 API 為基礎且可在 Notebook 環境中呼叫的便利方法。
計算描述性資料統計資料
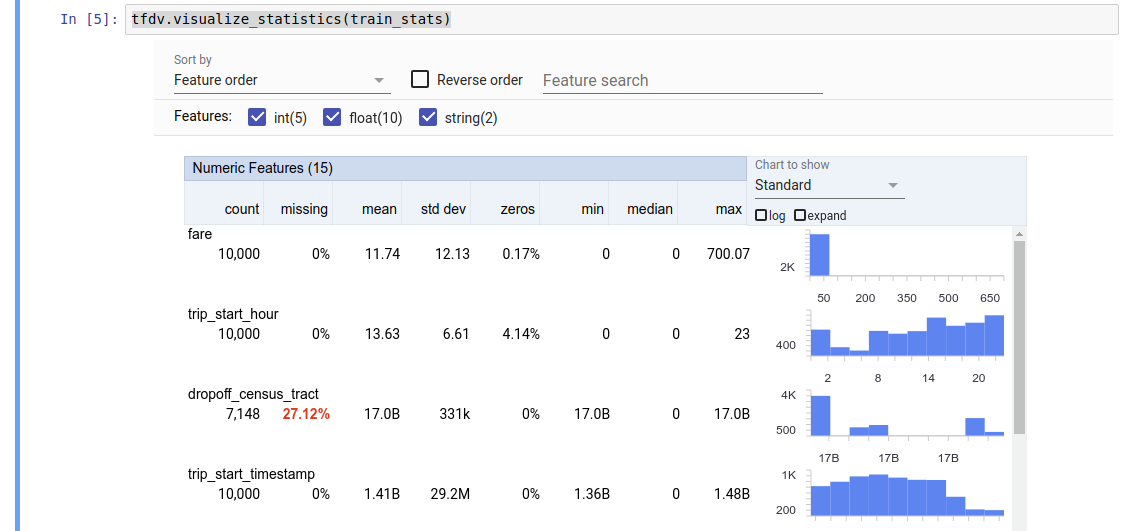
TFDV 可以計算描述性統計資料,快速總覽資料,包括呈現的功能,以及值分佈的形狀。「Facets Overview」等工具可以簡潔地視覺化呈現這些統計資料,以便輕鬆瀏覽。
例如,假設 path 指向 TFRecord 格式的檔案 (其中包含 tensorflow.Example 類型的記錄)。下列程式碼片段說明如何使用 TFDV 計算統計資料
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
傳回值是 DatasetFeatureStatisticsList 通訊協定緩衝區。範例 Notebook 包含使用 Facets Overview 視覺化呈現統計資料的範例
tfdv.visualize_statistics(stats)
先前的範例假設資料儲存在 TFRecord 檔案中。TFDV 也支援 CSV 輸入格式,並可擴充以支援其他常見格式。您可以在這裡找到可用的資料解碼器。此外,TFDV 也為以 pandas DataFrame 表示記憶體內資料的使用者提供 tfdv.generate_statistics_from_dataframe 公用程式函式。
除了計算預設的資料統計資料集外,TFDV 也可以計算語意網域 (例如圖片、文字) 的統計資料。如要啟用語意網域統計資料的計算功能,請將 tfdv.StatsOptions 物件與設為 True 的 enable_semantic_domain_stats 傳遞至 tfdv.generate_statistics_from_tfrecord。
在 Google Cloud 上執行
TFDV 在內部使用 Apache Beam 的資料平行處理架構,以便擴充統計資料在大型資料集上的計算規模。對於希望更深入整合 TFDV 的應用程式 (例如在資料產生管線結尾附加統計資料產生,為自訂格式的資料產生統計資料),API 也公開了用於產生統計資料的 Beam PTransform。
如要在 Google Cloud 上執行 TFDV,必須下載 TFDV Wheel 檔案,並提供給 Dataflow 工作站。將 Wheel 檔案下載到目前目錄,如下所示
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
下列程式碼片段顯示在 Google Cloud 上使用 TFDV 的範例
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
在此案例中,產生的統計資料 Proto 會儲存在寫入 GCS_STATS_OUTPUT_PATH 的 TFRecord 檔案中。
注意:在 Google Cloud 上呼叫任何 tfdv.generate_statistics_... 函式 (例如 tfdv.generate_statistics_from_tfrecord) 時,您必須提供 output_path。指定 None 可能會造成錯誤。
推論資料的結構描述
結構描述說明資料的預期屬性。其中部分屬性如下:
- 預期呈現的功能
- 其類型
- 每個範例中功能的值數量
- 所有範例中每個功能的呈現
- 功能的預期網域。
簡而言之,結構描述說明「正確」資料的預期條件,因此可用於偵測資料中的錯誤 (如下所述)。此外,相同的結構描述可用於設定 TensorFlow Transform 以進行資料轉換。請注意,結構描述應為相當靜態的結構描述,例如多個資料集可以符合相同的結構描述,而統計資料 (如上所述) 則可能因資料集而異。
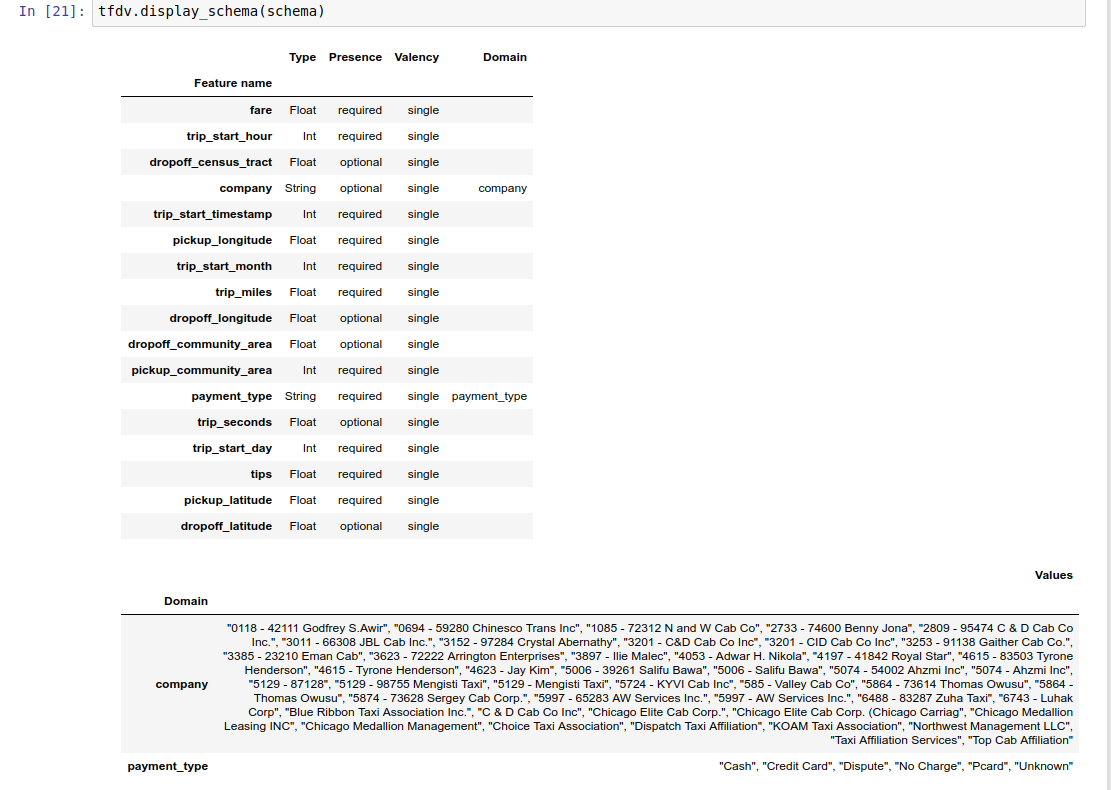
由於編寫結構描述可能相當繁瑣,尤其是對於具有大量功能的資料集而言,因此 TFDV 提供一種根據描述性統計資料產生結構描述初始版本的方法
schema = tfdv.infer_schema(stats)
一般而言,TFDV 使用保守的啟發法,從統計資料中推論穩定的資料屬性,以避免過度將結構描述擬合至特定資料集。強烈建議您檢查推論的結構描述,並在必要時加以精簡,以擷取 TFDV 的啟發法可能遺漏的任何資料網域知識。
根據預設,如果功能的 value_count.min 等於 value_count.max,tfdv.infer_schema 會推論每個必要功能的形狀。將 infer_feature_shape 引數設為 False,即可停用形狀推論。
結構描述本身會儲存為 Schema 通訊協定緩衝區,因此可以使用標準通訊協定緩衝區 API 進行更新/編輯。TFDV 也提供一些公用程式方法,讓這些更新更容易執行。舉例來說,假設結構描述包含下列節,以說明採用單一值的必要字串功能 payment_type
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
如要標記功能應在至少 50% 的範例中填入
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
範例 Notebook 包含結構描述的簡單視覺化呈現方式 (以表格形式列出每個功能及其結構描述中編碼的主要特性)。
檢查資料是否有錯誤
有了結構描述,就能檢查資料集是否符合結構描述中設定的預期條件,或是否存在任何資料異常。您可以檢查資料是否有錯誤:(a) 在整個資料集中彙總,方法是將資料集的統計資料與結構描述比對;或 (b) 逐個範例檢查錯誤。
將資料集的統計資料與結構描述比對
如要檢查彙總中的錯誤,TFDV 會將資料集的統計資料與結構描述比對,並標記任何差異。例如:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
結果是 Anomalies 通訊協定緩衝區的執行個體,並說明統計資料與結構描述不符的任何錯誤。舉例來說,假設 other_path 的資料包含 payment_type 功能的值,但超出結構描述中指定的網域。
這會產生異常
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
表示在 < 1% 的功能值中找到網域外的值。
如果這是預期的結果,則可以更新結構描述,如下所示
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
如果異常確實表示資料錯誤,則應先修正基礎資料,再用於訓練。
這個模組可以偵測到的各種異常類型在此列出。
範例 Notebook 包含異常的簡單視覺化呈現方式 (以表格形式列出偵測到錯誤的功能,以及每個錯誤的簡短說明)。

逐個範例檢查錯誤
TFDV 也提供逐個範例驗證資料的選項,而不是將資料集範圍的統計資料與結構描述進行比較。TFDV 提供相關函式,可逐個範例驗證資料,然後為找到的異常範例產生摘要統計資料。例如:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
validate_examples_in_tfrecord 傳回的 anomalous_example_stats 是 DatasetFeatureStatisticsList 通訊協定緩衝區,其中每個資料集都包含一組顯示特定異常的範例。您可以使用此緩衝區判斷資料集中顯示特定異常的範例數量,以及這些範例的特性。
結構描述環境
根據預設,驗證會假設管線中的所有資料集都遵循單一結構描述。在某些情況下,必須導入輕微的結構描述變化,例如在訓練期間需要用作標籤的功能 (且應經過驗證),但在服務期間則會遺失。
環境可用於表達這類需求。特別是,結構描述中的功能可以使用 default_environment、in_environment 和 not_in_environment 與一組環境建立關聯。
例如,如果 tips 功能在訓練中用作標籤,但在服務資料中遺失。如果未指定環境,則會顯示為異常。
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

為修正此問題,我們需要將所有功能的預設環境設為「TRAINING」和「SERVING」,並從 SERVING 環境中排除「tips」功能。
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
檢查資料偏移和偏移
除了檢查資料集是否符合結構描述中設定的預期條件外,TFDV 也提供偵測下列項目的功能:
- 訓練和服務資料之間的偏移
- 不同日期訓練資料之間的偏移
TFDV 會根據結構描述中指定的偏移/偏移比較子,比較不同資料集的統計資料,藉此執行這項檢查。例如,如要檢查訓練和服務資料集中的「payment_type」功能之間是否有任何偏移
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
注意:L-infinity 範數只會偵測類別功能的偏移。在 skew_comparator 中指定 jensen_shannon_divergence 閾值,而非指定 infinity_norm 閾值,即可偵測數值和類別功能的偏移。
與檢查資料集是否符合結構描述中設定的預期條件相同,結果也是 Anomalies 通訊協定緩衝區的執行個體,並說明訓練和服務資料集之間的任何偏移。舉例來說,假設服務資料包含更多 payement_type 功能值為 Cash 的範例,這會產生偏移異常
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
如果異常確實表示訓練和服務資料之間存在偏移,則必須進一步調查,因為這可能會直接影響模型效能。
範例 Notebook 包含檢查以偏移為基礎的異常的簡單範例。
偵測不同日期訓練資料之間的偏移可以透過類似方式完成
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
注意:L-infinity 範數只會偵測類別功能的偏移。在 skew_comparator 中指定 jensen_shannon_divergence 閾值,而非指定 infinity_norm 閾值,即可偵測數值和類別功能的偏移。
編寫自訂資料連接器
如要計算資料統計資料,TFDV 提供數種便利方法,可用於處理各種格式的輸入資料 (例如 tf.train.Example 的 TFRecord、CSV 等)。如果您的資料格式不在這個清單中,您需要編寫自訂資料連接器來讀取輸入資料,並將其與 TFDV 核心 API 連接,以計算資料統計資料。
TFDV 用於計算資料統計資料的核心 API 是 Beam PTransform,可接受輸入範例批次的 PCollection (輸入範例批次以 Arrow RecordBatch 表示),並輸出包含單一 DatasetFeatureStatisticsList 通訊協定緩衝區的 PCollection。
在您實作以 Arrow RecordBatch 批次處理輸入範例的自訂資料連接器後,您需要將其與 tfdv.GenerateStatistics API 連接,以計算資料統計資料。以 tf.train.Example 的 TFRecord 為例。tfx_bsl 提供 TFExampleRecord 資料連接器,以下說明如何將其與 tfdv.GenerateStatistics API 連接。
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
計算資料切片的統計資料
您可以將 TFDV 設定為計算資料切片的統計資料。您可以透過提供切片函式來啟用切片,這些函式會接收 Arrow RecordBatch,並輸出 (切片金鑰, 記錄批次) 形式的元組序列。TFDV 提供簡單的方式產生以功能值為基礎的切片函式,這些函式可以在計算統計資料時,以 tfdv.StatsOptions 的一部分提供。
啟用切片時,輸出 DatasetFeatureStatisticsList Proto 包含多個 DatasetFeatureStatistics Proto,每個切片各一個。每個切片都由唯一的名稱識別,該名稱會設為 DatasetFeatureStatistics Proto 中的資料集名稱。根據預設,除了設定的切片外,TFDV 也會計算整體資料集的統計資料。
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])