
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
本教學課程示範如何使用字元型 RNN 產生文字。您將使用 Andrej Karpathy 的 遞迴神經網路不合理的有效性中的莎士比亞著作資料集。給定此資料中的字元序列 ("Shakespear"),訓練模型以預測序列中的下一個字元 ("e")。透過重複呼叫模型,即可產生更長的文字序列。
本教學課程包含使用 tf.keras 和立即執行實作的可執行程式碼。以下是本教學課程中的模型訓練 30 個週期,並以提示字元 "Q" 開始時的範例輸出
QUEENE: I had thought thou hadst a Roman; for the oracle, Thus by All bids the man against the word, Which are so weak of care, by old care done; Your children were in your holy love, And the precipitation through the bleeding throne. BISHOP OF ELY: Marry, and will, my lord, to weep in such a one were prettiest; Yet now I was adopted heir Of the world's lamentable day, To watch the next way with his father with his face? ESCALUS: The cause why then we are all resolved more sons. VOLUMNIA: O, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, it is no sin it should be dead, And love and pale as any will to that word. QUEEN ELIZABETH: But how long have I heard the soul for this world, And show his hands of life be proved to stand. PETRUCHIO: I say he look'd on, if I must be content To stay him from the fatal of our country's bliss. His lordship pluck'd from this sentence then for prey, And then let us twain, being the moon, were she such a case as fills m
雖然有些句子符合文法,但大多數句子沒有意義。模型尚未學習單字的意義,但請思考
模型是以字元為基礎。在開始訓練時,模型不知道如何拼寫英文字,甚至不知道單字是文字單位。
輸出的結構類似於劇本,文字區塊通常以說話者姓名開頭,全部為大寫字母,與資料集類似。
如下所示,模型是以小批文字 (每個 100 個字元) 進行訓練,並且仍然能夠產生具有連貫結構的較長文字序列。
設定
匯入 TensorFlow 和其他程式庫
import tensorflow as tf
import numpy as np
import os
import time
下載莎士比亞資料集
變更以下行以在您自己的資料上執行此程式碼。
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
讀取資料
首先,查看文字
# Read, then decode for py2 compat.
text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# length of text is the number of characters in it
print(f'Length of text: {len(text)} characters')
# Take a look at the first 250 characters in text
print(text[:250])
# The unique characters in the file
vocab = sorted(set(text))
print(f'{len(vocab)} unique characters')
處理文字
向量化文字
在訓練之前,您需要將字串轉換為數值表示法。
tf.keras.layers.StringLookup 層可以將每個字元轉換為數值 ID。它只需要先將文字分割成權杖。
example_texts = ['abcdefg', 'xyz']
chars = tf.strings.unicode_split(example_texts, input_encoding='UTF-8')
chars
現在建立 tf.keras.layers.StringLookup 層
ids_from_chars = tf.keras.layers.StringLookup(
vocabulary=list(vocab), mask_token=None)
它會從權杖轉換為字元 ID
ids = ids_from_chars(chars)
ids
由於本教學課程的目標是產生文字,因此反轉此表示法並從中復原人類可讀的字串也很重要。為此,您可以使用 tf.keras.layers.StringLookup(..., invert=True)。
chars_from_ids = tf.keras.layers.StringLookup(
vocabulary=ids_from_chars.get_vocabulary(), invert=True, mask_token=None)
此層會從 ID 向量復原字元,並將其作為字元的 tf.RaggedTensor 傳回
chars = chars_from_ids(ids)
chars
您可以使用 tf.strings.reduce_join 將字元重新聯結成字串。
tf.strings.reduce_join(chars, axis=-1).numpy()
def text_from_ids(ids):
return tf.strings.reduce_join(chars_from_ids(ids), axis=-1)
預測工作
給定一個字元或字元序列,最有可能的下一個字元是什麼?這是您要訓練模型執行的工作。模型的輸入將是字元序列,您訓練模型以預測輸出,即每個時間步的下一個字元。
由於 RNN 維護取決於先前看過的元素的內部狀態,因此給定到目前為止計算的所有字元,下一個字元是什麼?
建立訓練範例和目標
接下來將文字劃分為範例序列。每個輸入序列將包含文字中的 seq_length 個字元。
對於每個輸入序列,對應的目標包含相同長度的文字,但向右移動一個字元。
因此,將文字分成 seq_length+1 個區塊。例如,假設 seq_length 為 4,而我們的文字為 "Hello"。輸入序列將為 "Hell",而目標序列為 "ello"。
若要執行此操作,首先使用 tf.data.Dataset.from_tensor_slices 函數將文字向量轉換為字元索引串流。
all_ids = ids_from_chars(tf.strings.unicode_split(text, 'UTF-8'))
all_ids
ids_dataset = tf.data.Dataset.from_tensor_slices(all_ids)
for ids in ids_dataset.take(10):
print(chars_from_ids(ids).numpy().decode('utf-8'))
seq_length = 100
batch 方法可讓您輕鬆地將這些個別字元轉換為所需大小的序列。
sequences = ids_dataset.batch(seq_length+1, drop_remainder=True)
for seq in sequences.take(1):
print(chars_from_ids(seq))
如果您將權杖重新聯結成字串,會更容易看出這在做什麼
for seq in sequences.take(5):
print(text_from_ids(seq).numpy())
為了進行訓練,您需要 (輸入, 標籤) 配對的資料集。其中 輸入 和 標籤 是序列。在每個時間步,輸入是目前字元,而標籤是下一個字元。
以下是一個函數,它會將序列作為輸入,複製並移動它,以對齊每個時間步的輸入和標籤
def split_input_target(sequence):
input_text = sequence[:-1]
target_text = sequence[1:]
return input_text, target_text
split_input_target(list("Tensorflow"))
dataset = sequences.map(split_input_target)
for input_example, target_example in dataset.take(1):
print("Input :", text_from_ids(input_example).numpy())
print("Target:", text_from_ids(target_example).numpy())
建立訓練批次
您已使用 tf.data 將文字分割成可管理的序列。但在將此資料饋送到模型之前,您需要隨機排序資料並將其封裝成批次。
# Batch size
BATCH_SIZE = 64
# Buffer size to shuffle the dataset
# (TF data is designed to work with possibly infinite sequences,
# so it doesn't attempt to shuffle the entire sequence in memory. Instead,
# it maintains a buffer in which it shuffles elements).
BUFFER_SIZE = 10000
dataset = (
dataset
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE, drop_remainder=True)
.prefetch(tf.data.experimental.AUTOTUNE))
dataset
建構模型
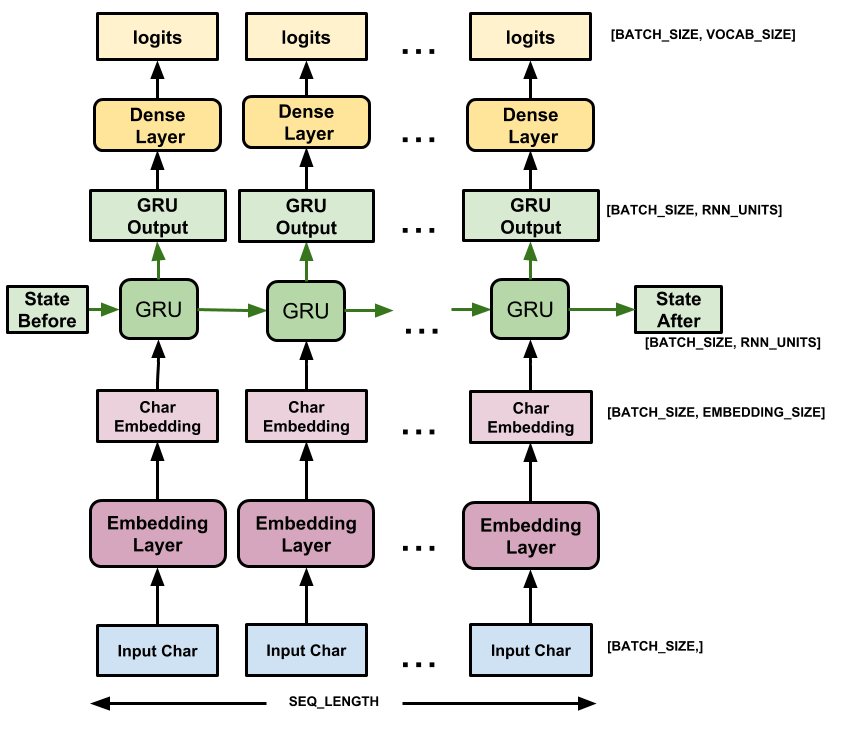
本節將模型定義為 keras.Model 子類別 (如需詳細資訊,請參閱透過子類別化建立新的層和模型)。
此模型有三層
tf.keras.layers.Embedding:輸入層。可訓練的查閱表,會將每個字元 ID 對應到具有embedding_dim維度的向量;tf.keras.layers.GRU:一種大小為units=rnn_units的 RNN 類型 (您也可以在此處使用 LSTM 層。)tf.keras.layers.Dense:輸出層,具有vocab_size個輸出。它會為詞彙表中的每個字元輸出一個邏輯值。這些是根據模型得出的每個字元的對數可能性。
# Length of the vocabulary in StringLookup Layer
vocab_size = len(ids_from_chars.get_vocabulary())
# The embedding dimension
embedding_dim = 256
# Number of RNN units
rnn_units = 1024
class MyModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, rnn_units):
super().__init__(self)
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(rnn_units,
return_sequences=True,
return_state=True)
self.dense = tf.keras.layers.Dense(vocab_size)
def call(self, inputs, states=None, return_state=False, training=False):
x = inputs
x = self.embedding(x, training=training)
if states is None:
states = self.gru.get_initial_state(x)
x, states = self.gru(x, initial_state=states, training=training)
x = self.dense(x, training=training)
if return_state:
return x, states
else:
return x
model = MyModel(
vocab_size=vocab_size,
embedding_dim=embedding_dim,
rnn_units=rnn_units)
對於每個字元,模型會查閱嵌入,使用嵌入作為輸入執行 GRU 一個時間步,並套用密集層以產生邏輯值,以預測下一個字元的對數可能性
試用模型
現在執行模型,看看它是否如預期般運作。
首先檢查輸出的形狀
for input_example_batch, target_example_batch in dataset.take(1):
example_batch_predictions = model(input_example_batch)
print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")
在上述範例中,輸入的序列長度為 100,但模型可以在任何長度的輸入上執行
model.summary()
若要從模型取得實際預測,您需要從輸出分佈中取樣,以取得實際字元索引。此分佈由字元詞彙表上的邏輯值定義。
針對批次中的第一個範例試用
sampled_indices = tf.random.categorical(example_batch_predictions[0], num_samples=1)
sampled_indices = tf.squeeze(sampled_indices, axis=-1).numpy()
這在每個時間步為我們提供了下一個字元索引的預測
sampled_indices
解碼這些內容以查看此未訓練模型預測的文字
print("Input:\n", text_from_ids(input_example_batch[0]).numpy())
print()
print("Next Char Predictions:\n", text_from_ids(sampled_indices).numpy())
訓練模型
此時,問題可以視為標準分類問題。給定先前的 RNN 狀態和此時間步的輸入,預測下一個字元的類別。
附加最佳化工具和損失函數
標準 tf.keras.losses.sparse_categorical_crossentropy 損失函數在此案例中有效,因為它適用於預測的最後一個維度。
由於您的模型會傳回邏輯值,因此您需要設定 from_logits 旗標。
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True)
example_batch_mean_loss = loss(target_example_batch, example_batch_predictions)
print("Prediction shape: ", example_batch_predictions.shape, " # (batch_size, sequence_length, vocab_size)")
print("Mean loss: ", example_batch_mean_loss)
新初始化的模型不應對自身過於自信,輸出邏輯值應具有相似的大小。若要確認這一點,您可以檢查平均損失的指數是否約等於詞彙表大小。損失高得多表示模型確信其錯誤答案,並且初始化不良
tf.exp(example_batch_mean_loss).numpy()
使用 tf.keras.Model.compile 方法設定訓練程序。使用具有預設引數和損失函數的 tf.keras.optimizers.Adam。
model.compile(optimizer='adam', loss=loss)
設定檢查點
使用 tf.keras.callbacks.ModelCheckpoint 以確保在訓練期間儲存檢查點
# Directory where the checkpoints will be saved
checkpoint_dir = './training_checkpoints'
# Name of the checkpoint files
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)
執行訓練
為了保持合理的訓練時間,請使用 10 個週期來訓練模型。在 Colab 中,將執行階段設定為 GPU 以加快訓練速度。
EPOCHS = 20
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])
產生文字
使用此模型產生文字最簡單的方式是在迴圈中執行它,並在執行時追蹤模型的內部狀態。
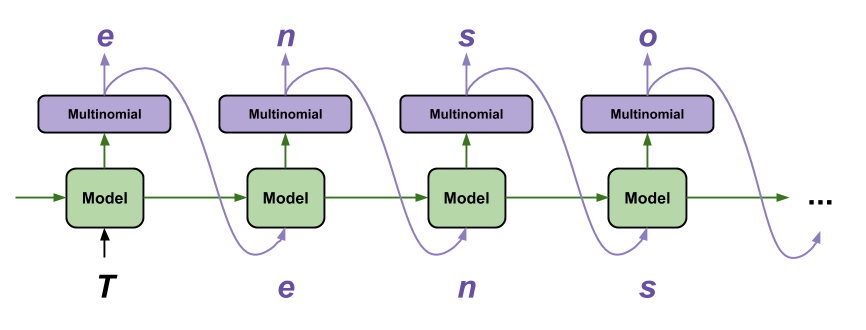
每次您呼叫模型時,您都會傳入一些文字和內部狀態。模型會傳回下一個字元的預測及其新狀態。傳入預測和狀態以繼續產生文字。
以下是單一步驟預測
class OneStep(tf.keras.Model):
def __init__(self, model, chars_from_ids, ids_from_chars, temperature=1.0):
super().__init__()
self.temperature = temperature
self.model = model
self.chars_from_ids = chars_from_ids
self.ids_from_chars = ids_from_chars
# Create a mask to prevent "[UNK]" from being generated.
skip_ids = self.ids_from_chars(['[UNK]'])[:, None]
sparse_mask = tf.SparseTensor(
# Put a -inf at each bad index.
values=[-float('inf')]*len(skip_ids),
indices=skip_ids,
# Match the shape to the vocabulary
dense_shape=[len(ids_from_chars.get_vocabulary())])
self.prediction_mask = tf.sparse.to_dense(sparse_mask)
@tf.function
def generate_one_step(self, inputs, states=None):
# Convert strings to token IDs.
input_chars = tf.strings.unicode_split(inputs, 'UTF-8')
input_ids = self.ids_from_chars(input_chars).to_tensor()
# Run the model.
# predicted_logits.shape is [batch, char, next_char_logits]
predicted_logits, states = self.model(inputs=input_ids, states=states,
return_state=True)
# Only use the last prediction.
predicted_logits = predicted_logits[:, -1, :]
predicted_logits = predicted_logits/self.temperature
# Apply the prediction mask: prevent "[UNK]" from being generated.
predicted_logits = predicted_logits + self.prediction_mask
# Sample the output logits to generate token IDs.
predicted_ids = tf.random.categorical(predicted_logits, num_samples=1)
predicted_ids = tf.squeeze(predicted_ids, axis=-1)
# Convert from token ids to characters
predicted_chars = self.chars_from_ids(predicted_ids)
# Return the characters and model state.
return predicted_chars, states
one_step_model = OneStep(model, chars_from_ids, ids_from_chars)
在迴圈中執行它以產生一些文字。查看產生的文字,您會看到模型知道何時大寫、建立段落並模仿類似莎士比亞的寫作詞彙。由於訓練週期次數很少,因此它尚未學會形成連貫的句子。
start = time.time()
states = None
next_char = tf.constant(['ROMEO:'])
result = [next_char]
for n in range(1000):
next_char, states = one_step_model.generate_one_step(next_char, states=states)
result.append(next_char)
result = tf.strings.join(result)
end = time.time()
print(result[0].numpy().decode('utf-8'), '\n\n' + '_'*80)
print('\nRun time:', end - start)
您可以執行以改善結果的最簡單方法是將其訓練更長時間 (嘗試 EPOCHS = 30)。
您也可以試驗不同的開始字串、嘗試新增另一個 RNN 層以提高模型的準確性,或調整溫度參數以產生更多或更少的隨機預測。
如果您希望模型更快產生文字,您可以執行的最簡單操作是批次處理文字產生。在以下範例中,模型產生 5 個輸出的時間與產生 1 個輸出的時間大致相同。
start = time.time()
states = None
next_char = tf.constant(['ROMEO:', 'ROMEO:', 'ROMEO:', 'ROMEO:', 'ROMEO:'])
result = [next_char]
for n in range(1000):
next_char, states = one_step_model.generate_one_step(next_char, states=states)
result.append(next_char)
result = tf.strings.join(result)
end = time.time()
print(result, '\n\n' + '_'*80)
print('\nRun time:', end - start)
匯出產生器
此單一步驟模型可以輕鬆地儲存和還原,讓您可以在接受 tf.saved_model 的任何位置使用它。
tf.saved_model.save(one_step_model, 'one_step')
one_step_reloaded = tf.saved_model.load('one_step')
states = None
next_char = tf.constant(['ROMEO:'])
result = [next_char]
for n in range(100):
next_char, states = one_step_reloaded.generate_one_step(next_char, states=states)
result.append(next_char)
print(tf.strings.join(result)[0].numpy().decode("utf-8"))
進階:自訂訓練
上述訓練程序很簡單,但無法讓您進行太多控制。它使用老師強制,這會阻止將錯誤的預測回饋到模型,因此模型永遠無法學會從錯誤中復原。
因此,既然您已了解如何手動執行模型,接下來您將實作訓練迴圈。如果您想要實作課程學習以協助穩定模型的開放迴路輸出,這會提供一個起點。
自訂訓練迴圈最重要的部分是訓練步驟函數。
使用 tf.GradientTape 追蹤梯度。您可以閱讀立即執行指南,以深入瞭解此方法。
基本程序如下
- 在
tf.GradientTape下執行模型並計算損失。 - 計算更新並使用最佳化工具將其套用至模型。
class CustomTraining(MyModel):
@tf.function
def train_step(self, inputs):
inputs, labels = inputs
with tf.GradientTape() as tape:
predictions = self(inputs, training=True)
loss = self.loss(labels, predictions)
grads = tape.gradient(loss, model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, model.trainable_variables))
return {'loss': loss}
上述 train_step 方法的實作遵循 Keras 的 train_step 慣例。這是選用的,但它可讓您變更訓練步驟的行為,並且仍然可以使用 keras 的 Model.compile 和 Model.fit 方法。
model = CustomTraining(
vocab_size=len(ids_from_chars.get_vocabulary()),
embedding_dim=embedding_dim,
rnn_units=rnn_units)
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True))
model.fit(dataset, epochs=1)
或者,如果您需要更多控制權,您可以編寫自己的完整自訂訓練迴圈
EPOCHS = 10
mean = tf.metrics.Mean()
for epoch in range(EPOCHS):
start = time.time()
mean.reset_states()
for (batch_n, (inp, target)) in enumerate(dataset):
logs = model.train_step([inp, target])
mean.update_state(logs['loss'])
if batch_n % 50 == 0:
template = f"Epoch {epoch+1} Batch {batch_n} Loss {logs['loss']:.4f}"
print(template)
# saving (checkpoint) the model every 5 epochs
if (epoch + 1) % 5 == 0:
model.save_weights(checkpoint_prefix.format(epoch=epoch))
print()
print(f'Epoch {epoch+1} Loss: {mean.result().numpy():.4f}')
print(f'Time taken for 1 epoch {time.time() - start:.2f} sec')
print("_"*80)
model.save_weights(checkpoint_prefix.format(epoch=epoch))