
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
TensorFlow Ranking 可以處理異質的密集和稀疏特徵,並擴展到數百萬個資料點。然而,建構和部署學習排序模型以大規模運作,除了單純設計模型之外,還會產生額外的挑戰。Ranking 程式庫提供工作流程公用程式類別,用於為大規模排序應用程式建構分散式訓練。如需這些功能的詳細資訊,請參閱 TensorFlow Ranking 總覽。
本教學課程說明如何建構排序模型,透過使用 Ranking 程式庫對管線處理架構的支援,啟用分散式處理策略。
ANTIQUE 資料集
在本教學課程中,您將為 ANTIQUE(問答資料集)建構排序模型。在給定查詢和答案清單的情況下,目標是以最佳排序相關指標 (例如 NDCG) 對答案進行排序。如需排序指標的詳細資訊,請檢閱評估指標離線指標。
ANTIQUE 是公開可用的開放網域非事實型問答資料集,收集自 Yahoo! Answers。每個問題都有一個答案清單,其相關性等級為 0-4,0 代表不相關,4 代表完全相關。清單大小可能會因查詢而異,因此我們使用 50 的固定「清單大小」,其中清單會被截斷或以預設值填補。資料集分為 2206 個查詢用於訓練,200 個查詢用於測試。如需詳細資訊,請參閱 arXiv 上的技術論文。
設定
下載並安裝 TensorFlow Ranking 和 TensorFlow Serving 套件。
pip install -q tensorflow-ranking tensorflow-serving-apipip install -U "tensorflow-text==2.11.*"
透過筆記本匯入 TensorFlow Ranking 程式庫和實用程式庫。
import pathlib
import tensorflow as tf
import tensorflow_ranking as tfr
import tensorflow_text as tf_text
from tensorflow_serving.apis import input_pb2
from google.protobuf import text_format
資料準備
下載訓練、測試資料和詞彙檔案。
wget -O "/tmp/train.tfrecords" "http://ciir.cs.umass.edu/downloads/Antique/tf-ranking/ELWC/train.tfrecords"wget -O "/tmp/test.tfrecords" "http://ciir.cs.umass.edu/downloads/Antique/tf-ranking//ELWC/test.tfrecords"wget -O "/tmp/vocab.txt" "http://ciir.cs.umass.edu/downloads/Antique/tf-ranking/vocab.txt"
此處,資料集以特定於排序的 ExampleListWithContext (ELWC) 格式儲存。下一節將詳細說明如何以 ELWC 格式產生和儲存資料。
用於排序的 ELWC 資料格式
單一問題的資料包含代表問題的 query_tokens 清單 (「情境」),以及答案清單 (「範例」)。每個答案都表示為 document_tokens 清單和 relevance 分數。以下程式碼顯示問題資料的簡化表示法
example_list_with_context = {
"context": {
"query_tokens": ["this", "is", "a", "question"]
},
"examples": [
{
"document_tokens": ["this", "is", "a", "relevant", "answer"],
"relevance": [4]
},
{
"document_tokens": ["irrelevant", "data"],
"relevance": [0]
}
]
}
先前章節中下載的資料檔案包含此類資料的序列化 protobuffer 表示法。當以文字形式檢視時,這些 protobuffer 相當長,但會編碼相同的資料。
CONTEXT = text_format.Parse(
"""
features {
feature {
key: "query_tokens"
value { bytes_list { value: ["this", "is", "a", "question"] } }
}
}""", tf.train.Example())
EXAMPLES = [
text_format.Parse(
"""
features {
feature {
key: "document_tokens"
value { bytes_list { value: ["this", "is", "a", "relevant", "answer"] } }
}
feature {
key: "relevance"
value { int64_list { value: 4 } }
}
}""", tf.train.Example()),
text_format.Parse(
"""
features {
feature {
key: "document_tokens"
value { bytes_list { value: ["irrelevant", "data"] } }
}
feature {
key: "relevance"
value { int64_list { value: 0 } }
}
}""", tf.train.Example()),
]
ELWC = input_pb2.ExampleListWithContext()
ELWC.context.CopyFrom(CONTEXT)
for example in EXAMPLES:
example_features = ELWC.examples.add()
example_features.CopyFrom(example)
print(ELWC)
examples {
features {
feature {
key: "document_tokens"
value {
bytes_list {
value: "this"
value: "is"
value: "a"
value: "relevant"
value: "answer"
}
}
}
feature {
key: "relevance"
value {
int64_list {
value: 4
}
}
}
}
}
examples {
features {
feature {
key: "document_tokens"
value {
bytes_list {
value: "irrelevant"
value: "data"
}
}
}
feature {
key: "relevance"
value {
int64_list {
value: 0
}
}
}
}
}
context {
features {
feature {
key: "query_tokens"
value {
bytes_list {
value: "this"
value: "is"
value: "a"
value: "question"
}
}
}
}
}
雖然文字格式很冗長,但 protos 可以有效率地序列化為位元組字串 (並剖析回 proto)
serialized_elwc = ELWC.SerializeToString()
print(serialized_elwc)
b"\nL\nJ\n4\n\x0fdocument_tokens\x12!\n\x1f\n\x04this\n\x02is\n\x01a\n\x08relevant\n\x06answer\n\x12\n\trelevance\x12\x05\x1a\x03\n\x01\x04\n?\n=\n\x12\n\trelevance\x12\x05\x1a\x03\n\x01\x00\n'\n\x0fdocument_tokens\x12\x14\n\x12\n\nirrelevant\n\x04data\x12-\n+\n)\n\x0cquery_tokens\x12\x19\n\x17\n\x04this\n\x02is\n\x01a\n\x08question"
以下剖析器設定會將二進位表示法剖析為張量字典
def parse_elwc(elwc):
return tfr.data.parse_from_example_list(
[elwc],
list_size=2,
context_feature_spec={"query_tokens": tf.io.RaggedFeature(dtype=tf.string)},
example_feature_spec={
"document_tokens":
tf.io.RaggedFeature(dtype=tf.string),
"relevance":
tf.io.FixedLenFeature(shape=[], dtype=tf.int64, default_value=0)
},
size_feature_name="_list_size_",
mask_feature_name="_mask_")
parse_elwc(serialized_elwc)
{'_list_size_': <tf.Tensor: shape=(1,), dtype=int32, numpy=array([2], dtype=int32)>,
'_mask_': <tf.Tensor: shape=(1, 2), dtype=bool, numpy=array([[ True, True]])>,
'document_tokens': <tf.RaggedTensor [[[b'this', b'is', b'a', b'relevant', b'answer'], [b'irrelevant', b'data']]]>,
'query_tokens': <tf.RaggedTensor [[b'this', b'is', b'a', b'question']]>,
'relevance': <tf.Tensor: shape=(1, 2), dtype=int64, numpy=array([[4, 0]])>}
請注意,使用 ELWC,您也可以產生 size 和/或 mask 特徵,以指示有效大小和/或遮罩清單中的有效項目,只要定義 size_feature_name 和/或 mask_feature_name 即可。
上述剖析器在 tfr.data 中定義,並包裝在我們預先定義的資料集建構工具 tfr.keras.pipeline.BaseDatasetBuilder 中。
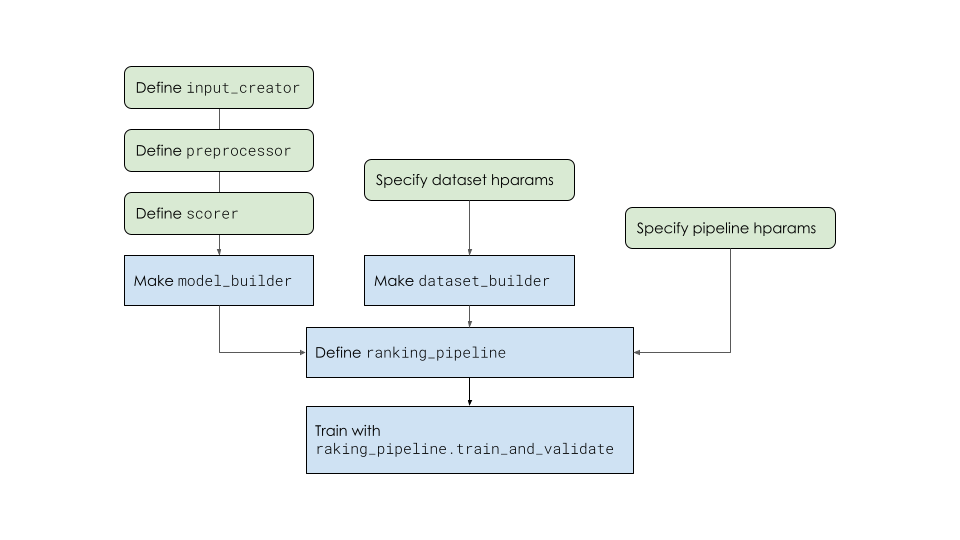
排序管線總覽
按照下圖所示的步驟,使用排序管線訓練排序模型。特別是,此範例使用針對具有 feature_spec 的資料集定義的 tfr.keras.model.FeatureSpecInputCreator 和 tfr.keras.pipeline.BaseDatasetBuilder。
建立模型建構工具
不要直接建構 tf.keras.Model 物件,而是建立 model_builder,它會在排序管線中呼叫以建構 tf.keras.Model,因為所有訓練參數都必須在 strategy.scope (在排序管線的 train_and_validate 函式中呼叫) 下定義,才能使用分散式策略進行訓練。
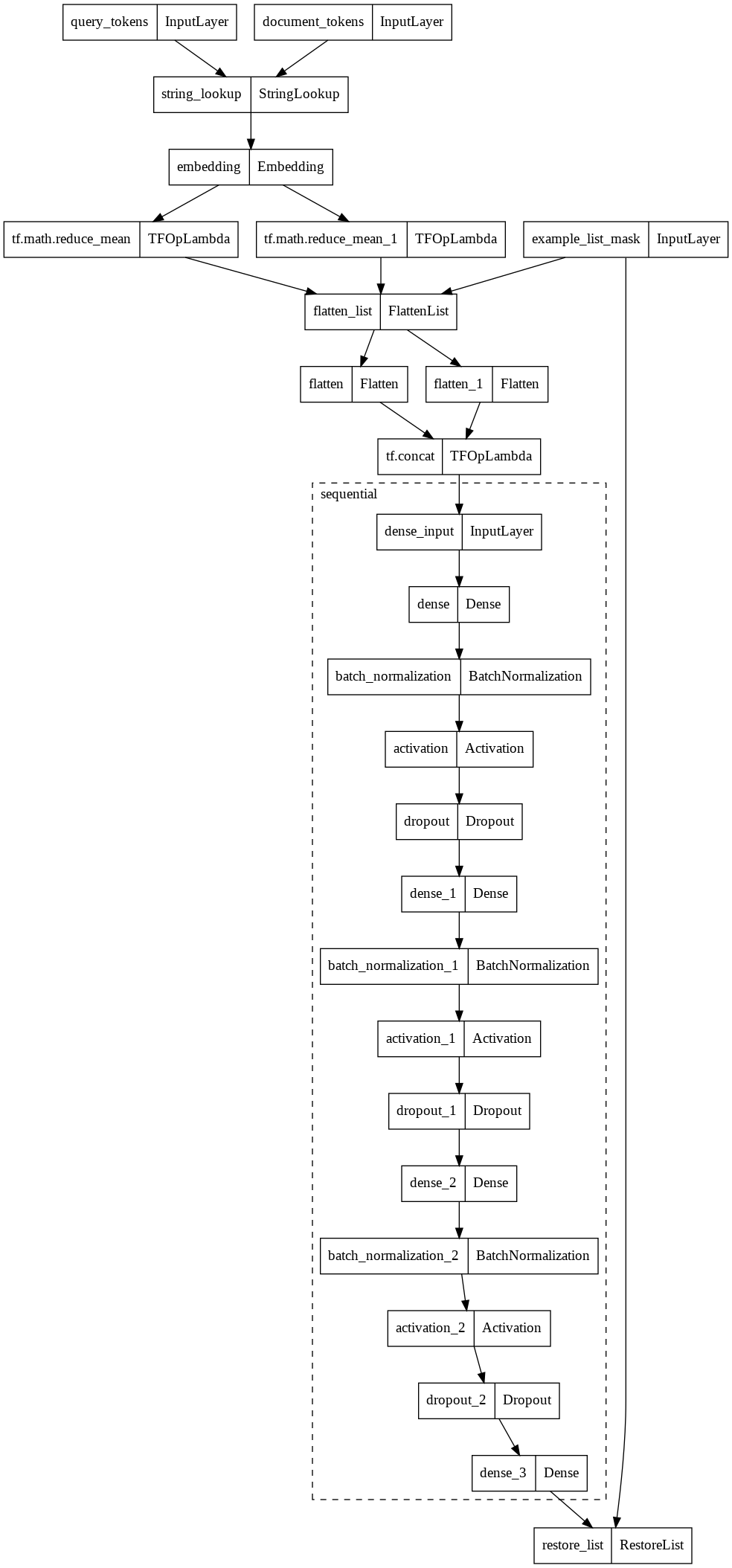
此架構使用 Keras Functional API 來建構模型,其中需要輸入 (tf.keras.Input)、前處理器 (tf.keras.layers.experimental.preprocessing) 和評分器 (tf.keras.Sequential) 來定義模型。
指定特徵
特徵規格是 TensorFlow 抽象概念,用於擷取有關每個特徵的豐富資訊。
為情境特徵、範例特徵和標籤建立特徵規格,使其與排序的輸入格式 (例如 ELWC 格式) 一致。
label_spec 特徵的 default_value 設定為 -1,以處理要遮罩的填補項目。
context_feature_spec = {
"query_tokens": tf.io.RaggedFeature(dtype=tf.string),
}
example_feature_spec = {
"document_tokens":
tf.io.RaggedFeature(dtype=tf.string),
}
label_spec = (
"relevance",
tf.io.FixedLenFeature(shape=(1,), dtype=tf.int64, default_value=-1)
)
定義 input_creator
input_creator 為 context_feature_spec 和 example_feature_spec 中定義的輸入特徵建立情境和範例 tf.keras.Input 字典。
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
呼叫 input_creator 會傳回 Keras 張量的字典,這些字典在建構模型時用作輸入
input_creator()
({'query_tokens': <KerasTensor: type_spec=RaggedTensorSpec(TensorShape([None, None]), tf.string, 1, tf.int64) (created by layer 'query_tokens')>},
{'document_tokens': <KerasTensor: type_spec=RaggedTensorSpec(TensorShape([None, None, None]), tf.string, 2, tf.int64) (created by layer 'document_tokens')>})
定義 preprocessor
在 preprocessor 中,輸入符號會透過字串查詢前處理層轉換為 one-hot 向量,然後透過嵌入前處理層嵌入為嵌入向量。最後,透過符號嵌入的平均值計算完整句子的嵌入向量。
class LookUpTablePreprocessor(tfr.keras.model.Preprocessor):
def __init__(self, vocab_file, vocab_size, embedding_dim):
self._vocab_file = vocab_file
self._vocab_size = vocab_size
self._embedding_dim = embedding_dim
def __call__(self, context_inputs, example_inputs, mask):
list_size = tf.shape(mask)[1]
lookup = tf.keras.layers.StringLookup(
max_tokens=self._vocab_size,
vocabulary=self._vocab_file,
mask_token=None)
embedding = tf.keras.layers.Embedding(
input_dim=self._vocab_size,
output_dim=self._embedding_dim,
embeddings_initializer=None,
embeddings_constraint=None)
# StringLookup and Embedding are shared over context and example features.
context_features = {
key: tf.reduce_mean(embedding(lookup(value)), axis=-2)
for key, value in context_inputs.items()
}
example_features = {
key: tf.reduce_mean(embedding(lookup(value)), axis=-2)
for key, value in example_inputs.items()
}
return context_features, example_features
_VOCAB_FILE = '/tmp/vocab.txt'
_VOCAB_SIZE = len(pathlib.Path(_VOCAB_FILE).read_text().split())
preprocessor = LookUpTablePreprocessor(_VOCAB_FILE, _VOCAB_SIZE, 20)
請注意,詞彙表使用與 BERT 相同的符號化工具。您也可以使用 BertTokenizer 來符號化原始句子。
tokenizer = tf_text.BertTokenizer(_VOCAB_FILE)
example_tokens = tokenizer.tokenize("Hello TensorFlow!".lower())
print(example_tokens)
print(tokenizer.detokenize(example_tokens))
<tf.RaggedTensor [[[7592], [23435, 12314], [999]]]> <tf.RaggedTensor [[[b'hello'], [b'tensorflow'], [b'!']]]>
定義 scorer
此範例使用 TensorFlow Ranking 中預先定義的深度神經網路 (DNN) 單變數評分器。
scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[64, 32, 16],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True)
建立 model_builder
除了 input_creator、preprocessor 和 scorer 之外,請指定遮罩特徵名稱以取得資料集中產生的遮罩特徵。
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=scorer,
mask_feature_name="example_list_mask",
name="antique_model",
)
檢查模型架構,
model = model_builder.build()
tf.keras.utils.plot_model(model, expand_nested=True)
建立資料集建構工具
dataset_builder 旨在建立用於訓練和驗證的資料集,並定義用於將訓練模型匯出為 tf.function 的簽名。
指定資料超參數
透過建立 dataset_hparams 物件,定義用於在 dataset_builder 中建構資料集的超參數。
使用 tf.data.TFRecordDataset 讀取器在 /tmp/train.tfrecords 載入訓練資料集。在每個批次中,每個特徵張量的形狀為 (batch_size, list_size, feature_sizes),其中 batch_size 等於 32,list_size 等於 50。使用相同 batch_size 和 list_size 在 /tmp/test.tfrecords 驗證測試資料。
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern="/tmp/train.tfrecords",
valid_input_pattern="/tmp/test.tfrecords",
train_batch_size=32,
valid_batch_size=32,
list_size=50,
dataset_reader=tf.data.TFRecordDataset)
建立 dataset_builder
TensorFlow Ranking 提供預先定義的 SimpleDatasetBuilder,以使用 feature_spec 從 ELWC 產生資料集。由於遮罩特徵用於判斷每個填補清單中的有效範例,因此必須指定與 model_builder 中使用的 mask_feature_name 一致的 mask_feature_name。
dataset_builder = tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec,
example_feature_spec,
mask_feature_name="example_list_mask",
label_spec=label_spec,
hparams=dataset_hparams)
ds_train = dataset_builder.build_train_dataset()
ds_train.element_spec
({'document_tokens': RaggedTensorSpec(TensorShape([None, 50, None]), tf.string, 2, tf.int32),
'example_list_mask': TensorSpec(shape=(32, 50), dtype=tf.bool, name=None),
'query_tokens': RaggedTensorSpec(TensorShape([32, None]), tf.string, 1, tf.int32)},
TensorSpec(shape=(32, 50), dtype=tf.float32, name=None))
建立排序管線
ranking_pipeline 是最佳化的排序模型訓練套件,可實作分散式訓練、將模型匯出為 tf.function,並整合有用的回呼 (包括 TensorBoard) 和失敗時的還原。
指定管線超參數
透過建立 pipeline_hparams 物件,指定用於在 ranking_pipeline 中執行管線的超參數。
以學習率 0.05 訓練模型,使用 approx_ndcg_loss 進行 5 個 epoch,每個 epoch 中有 1000 個步驟,並使用 MirroredStrategy。在每個 epoch 之後,在驗證資料集上評估模型 100 個步驟。將訓練模型儲存在 /tmp/ranking_model_dir 下。
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir="/tmp/ranking_model_dir",
num_epochs=5,
steps_per_epoch=1000,
validation_steps=100,
learning_rate=0.05,
loss="approx_ndcg_loss",
strategy="MirroredStrategy")
定義 ranking_pipeline
TensorFlow Ranking 提供預先定義的 SimplePipeline,以支援使用分散式策略的模型訓練。
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams)
WARNING:tensorflow:There are non-GPU devices in `tf.distribute.Strategy`, not using nccl allreduce.
WARNING:tensorflow:There are non-GPU devices in `tf.distribute.Strategy`, not using nccl allreduce.
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:CPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:CPU:0',)
訓練和評估模型
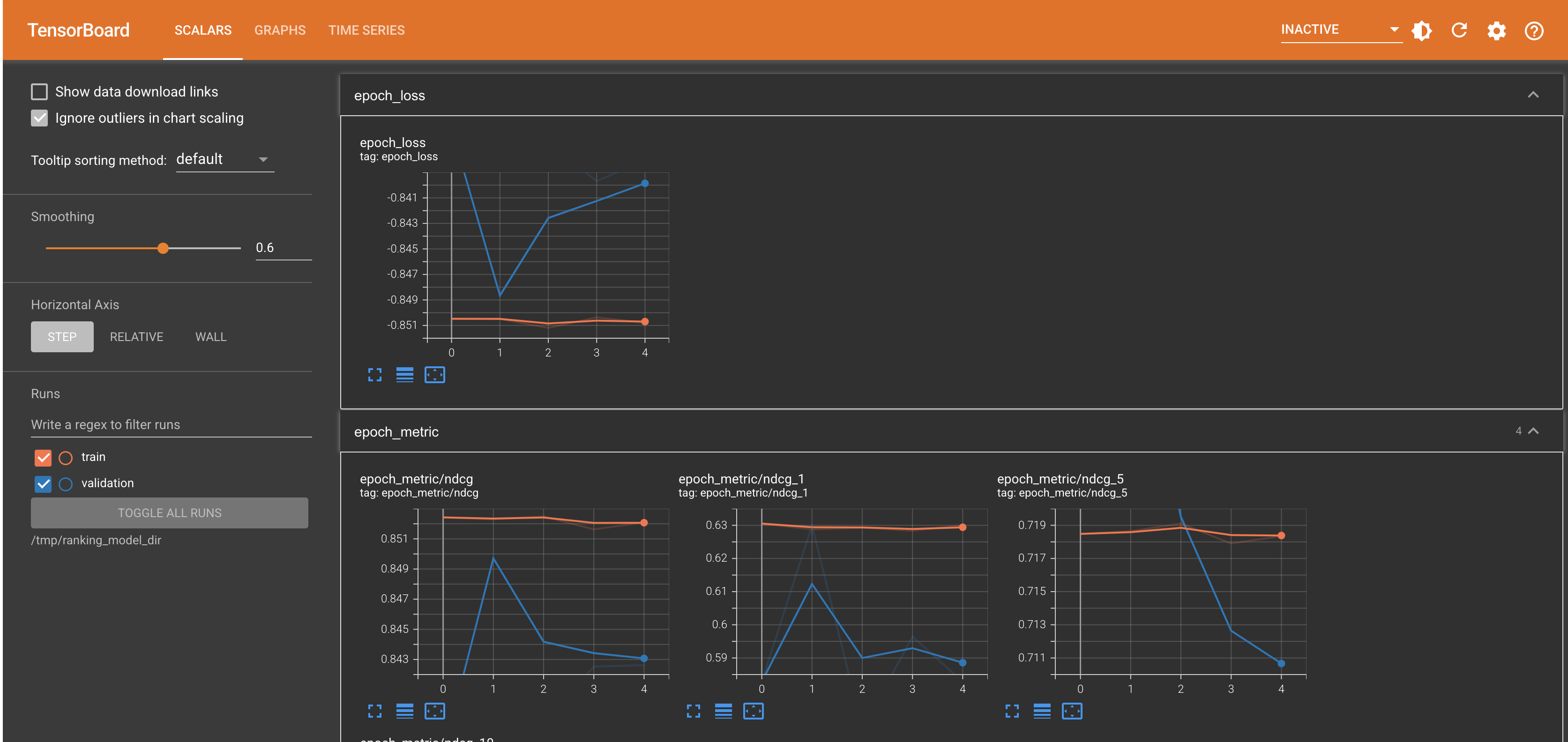
train_and_validate 函式會在每個 epoch 之後,在驗證資料集上評估訓練模型。
ranking_pipeline.train_and_validate(verbose=1)
Epoch 1/5
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/indexed_slices.py:450: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape_1:0", shape=(1600,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0), values=Tensor("gradient_tape/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape:0", shape=(1600, 20), dtype=float32, device=/job:localhost/replica:0/task:0/device:CPU:0), dense_shape=Tensor("gradient_tape/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Cast:0", shape=(2,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/indexed_slices.py:450: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/while/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape_1:0", shape=(1600,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0), values=Tensor("gradient_tape/while/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape:0", shape=(1600, 20), dtype=float32, device=/job:localhost/replica:0/task:0/device:CPU:0), dense_shape=Tensor("gradient_tape/while/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Cast:0", shape=(2,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1000/1000 [==============================] - 121s 121ms/step - loss: -0.8845 - metric/ndcg_1: 0.7122 - metric/ndcg_5: 0.7813 - metric/ndcg_10: 0.8413 - metric/ndcg: 0.8856 - val_loss: -0.8672 - val_metric/ndcg_1: 0.6557 - val_metric/ndcg_5: 0.7689 - val_metric/ndcg_10: 0.8243 - val_metric/ndcg: 0.8678
Epoch 2/5
1000/1000 [==============================] - 88s 88ms/step - loss: -0.8957 - metric/ndcg_1: 0.7428 - metric/ndcg_5: 0.8005 - metric/ndcg_10: 0.8551 - metric/ndcg: 0.8959 - val_loss: -0.8731 - val_metric/ndcg_1: 0.6614 - val_metric/ndcg_5: 0.7812 - val_metric/ndcg_10: 0.8348 - val_metric/ndcg: 0.8733
Epoch 3/5
1000/1000 [==============================] - 50s 50ms/step - loss: -0.8955 - metric/ndcg_1: 0.7422 - metric/ndcg_5: 0.7991 - metric/ndcg_10: 0.8545 - metric/ndcg: 0.8957 - val_loss: -0.8695 - val_metric/ndcg_1: 0.6414 - val_metric/ndcg_5: 0.7759 - val_metric/ndcg_10: 0.8315 - val_metric/ndcg: 0.8699
Epoch 4/5
1000/1000 [==============================] - 53s 53ms/step - loss: -0.9009 - metric/ndcg_1: 0.7563 - metric/ndcg_5: 0.8094 - metric/ndcg_10: 0.8620 - metric/ndcg: 0.9011 - val_loss: -0.8624 - val_metric/ndcg_1: 0.6179 - val_metric/ndcg_5: 0.7627 - val_metric/ndcg_10: 0.8253 - val_metric/ndcg: 0.8626
Epoch 5/5
1000/1000 [==============================] - 52s 52ms/step - loss: -0.9042 - metric/ndcg_1: 0.7646 - metric/ndcg_5: 0.8152 - metric/ndcg_10: 0.8662 - metric/ndcg: 0.9044 - val_loss: -0.8733 - val_metric/ndcg_1: 0.6579 - val_metric/ndcg_5: 0.7741 - val_metric/ndcg_10: 0.8362 - val_metric/ndcg: 0.8741
INFO:tensorflow:Assets written to: /tmp/ranking_model_dir/export/latest_model/assets
INFO:tensorflow:Assets written to: /tmp/ranking_model_dir/export/latest_model/assets
啟動 TensorBoard
%load_ext tensorboard
%tensorboard --logdir="/tmp/ranking_model_dir" --port 12345
產生預測並評估
取得測試資料。
ds_test = dataset_builder.build_valid_dataset()
# Get input features from the first batch of the test data
for x, y in ds_test.take(1):
break
載入已儲存的模型並執行預測。
loaded_model = tf.keras.models.load_model("/tmp/ranking_model_dir/export/latest_model")
# Predict ranking scores
scores = loaded_model.predict(x)
min_score = tf.reduce_min(scores)
scores = tf.where(tf.greater_equal(y, 0.), scores, min_score - 1e-5)
# Sort the answers by scores
sorted_answers = tfr.utils.sort_by_scores(
scores,
[tf.strings.reduce_join(x['document_tokens'], -1, separator=' ')])[0]
檢查問題編號 4 的前 5 個答案。
question = tf.strings.reduce_join(
x['query_tokens'][4, :], -1, separator=' ').numpy()
top_answers = sorted_answers[4, :5].numpy()
print(
f'Q: {question.decode()}\n' +
'\n'.join([f'A{i+1}: {ans.decode()}' for i, ans in enumerate(top_answers)]))
Q: why do people ask questions they know ? A1: because it re ##as ##ures them that they were right in the first place . A2: people like to that be ##cao ##use they want to be recognise that they are the one knows the answer and the questions int ##he first place . A3: to rev ##ali ##date their knowledge and perhaps they choose answers that are mostly with their side simply because they are being subjective . . . . A4: so they can weasel out the judge mental and super ##ci ##lio ##us know all cr ##aa ##p like yourself . . . don ##t judge others , what gives you the right ? . . how do you know what others know . ? . . by asking this question you are putting yourself in the same league as the others you want ot condemn . . face it you already know what your shallow , self absorbed answer is . . . get a reality check pill ##ock , . . . and if you want to go gr ##iz ##z ##ling to the yahoo policeman bring it on . . it will only reinforce my answer and the pathetic ##iness of your q ##est ##ion . . . the only thing you could do that would be even more pathetic is give me the top answer award . . . then you would suck beyond all measure A5: human nature i guess . i have noticed that too . maybe it is just for re ##ass ##urance or approval .