
可擴充、神經網路式排序學習 (LTR) 模型
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_ranking as tfr
# Prep data
ds = tfds.load("mslr_web/10k_fold1", split="train")
ds = ds.map(lambda feature_map: {
"_mask": tf.ones_like(feature_map["label"], dtype=tf.bool),
**feature_map
})
ds = ds.shuffle(buffer_size=1000).padded_batch(batch_size=32)
ds = ds.map(lambda feature_map: (
feature_map, tf.where(feature_map["_mask"], feature_map.pop("label"), -1.)))
# Create a model
inputs = {
"float_features": tf.keras.Input(shape=(None, 136), dtype=tf.float32)
}
norm_inputs = [tf.keras.layers.BatchNormalization()(x) for x in inputs.values()]
x = tf.concat(norm_inputs, axis=-1)
for layer_width in [128, 64, 32]:
x = tf.keras.layers.Dense(units=layer_width)(x)
x = tf.keras.layers.Activation(activation=tf.nn.relu)(x)
scores = tf.squeeze(tf.keras.layers.Dense(units=1)(x), axis=-1)
# Compile and train
model = tf.keras.Model(inputs=inputs, outputs=scores)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss=tfr.keras.losses.SoftmaxLoss(),
metrics=tfr.keras.metrics.get("ndcg", topn=5, name="NDCG@5"))
model.fit(ds, epochs=3)
在 Notebook 中執行
TensorFlow Ranking 是一個開放原始碼函式庫,用於開發可擴充、神經網路式排序學習 (LTR) 模型。排序模型通常用於搜尋和推薦系統,但也已成功應用於各種領域,包括機器翻譯、對話系統 電子商務、SAT 解題器、智慧城市規劃,甚至計算生物學。
排序模型會接收項目清單 (網頁、文件、產品、電影等),並產生最佳化順序的清單,例如最相關的項目在頂端,最不相關的項目在底部,通常是為了回應使用者查詢
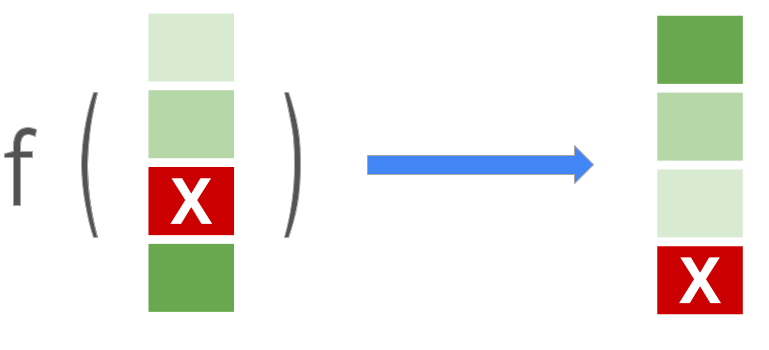
這個函式庫支援 LTR 模型的標準逐點、成對和列表式損失函數。它也支援各種排序指標,包括平均倒數排名 (MRR) 和標準化折扣累積增益 (NDCG),讓您可以評估和比較這些方法在排序任務中的成效。Ranking 函式庫也提供由 Google 的機器學習工程師研究、測試和建構的強化排序方法函式。
請查看教學課程,開始使用 TensorFlow Ranking 函式庫。請閱讀「總覽」,進一步瞭解此函式庫的功能。請查看 GitHub 上的 TensorFlow Ranking 原始碼。