
重點提要:透過 TensorFlow Ranking Pipelines 減少建構、訓練及服務 TensorFlow Ranking 模型的重複程式碼;針對大型 Ranking 應用程式,根據使用情境和資源採用合適的分散式策略。
簡介
TensorFlow Ranking Pipeline 包含一連串的資料處理、模型建構、訓練和服務流程,讓您能以最少的力氣,從資料記錄建構、訓練及服務可擴充的神經網路 Ranking 模型。當系統擴大規模時,這個管線的效率最高。一般而言,如果您的模型在單一機器上需要 10 分鐘或更久才能執行,請考慮使用這個管線架構來分散負載並加速處理。
TensorFlow Ranking Pipeline 已在大型實驗和生產環境中持續穩定地運行,處理大數據 (TB 級以上) 和大型模型 (1 億以上 FLOP) 於分散式系統 (1 千以上 CPU 和 1 百以上 GPU 和 TPU)。一旦 TensorFlow 模型透過小部分資料上的 model.fit 驗證後,建議在超參數掃描、持續訓練和其他大規模情境中使用此管線。
Ranking 管線
在 TensorFlow 中,建構、訓練和服務 Ranking 模型的典型管線包含以下典型步驟。
- 定義模型結構
- 建立輸入;
- 建立預先處理層;
- 建立神經網路架構;
- 訓練模型
- 服務模型
- 判斷服務時的資料格式;
- 選擇並載入已訓練的模型;
- 使用載入的模型進行處理。
TensorFlow Ranking 管線的主要目標之一是減少步驟中的重複程式碼,例如資料集載入和預先處理、listwise 資料和 pointwise 評分函數的相容性,以及模型匯出。另一個重要的目標是強制執行許多固有相關流程的一致設計,例如,模型輸入必須與訓練資料集和服務時的資料格式相容。
使用指南
透過以上所有設計,啟動 TF-ranking 模型會遵循以下步驟,如圖 1 所示。
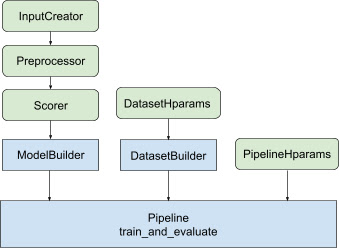
使用分散式神經網路的範例
在此範例中,您將運用內建的 tfr.keras.model.FeatureSpecInputCreator、tfr.keras.pipeline.SimpleDatasetBuilder 和 tfr.keras.pipeline.SimplePipeline,這些類別會接收 feature_spec,以便在模型輸入和資料集伺服器中一致地定義輸入特徵。包含逐步導覽的 Notebook 版本可在分散式 Ranking 教學課程中找到。
首先,為情境和範例特徵定義 feature_spec。
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
按照圖 1 中說明的步驟操作
從 feature_spec 定義 input_creator。
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
然後,為同一組輸入特徵定義預先處理特徵轉換。
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
使用內建的前饋 DNN 模型定義評分器。
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
使用 input_creator、preprocessor 和 scorer 建立 model_builder。
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
現在設定 dataset_builder 的超參數。
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
建立 dataset_builder。
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
也設定管線的超參數。
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
建立 ranking_pipeline 並進行訓練。
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
TensorFlow Ranking Pipeline 的設計
TensorFlow Ranking Pipeline 有助於透過重複程式碼節省工程時間,同時透過覆寫和子類別化提供自訂彈性。為了達成這個目標,管線引入了可自訂的類別 tfr.keras.model.AbstractModelBuilder、tfr.keras.pipeline.AbstractDatasetBuilder 和 tfr.keras.pipeline.AbstractPipeline,以設定 TensorFlow Ranking 管線。

ModelBuilder
與建構 Keras 模型相關的重複程式碼整合在 AbstractModelBuilder 中,此類別會傳遞至 AbstractPipeline,並在管線內呼叫,以在策略範圍下建構模型。如圖 1 所示。類別方法定義在抽象基礎類別中。
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
您可以直接子類別化 AbstractModelBuilder,並使用具體方法覆寫以進行自訂,例如
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
同時,您應該使用 ModelBuilder,並將輸入特徵、預先處理轉換和評分函數指定為類別初始設定中的函數輸入 input_creator、preprocessor 和 scorer,而非子類別化。
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
為了減少建立這些輸入的重複程式碼,提供了函數類別 tfr.keras.model.InputCreator (適用於 input_creator)、tfr.keras.model.Preprocessor (適用於 preprocessor) 和 tfr.keras.model.Scorer (適用於 scorer),以及具體的子類別 tfr.keras.model.FeatureSpecInputCreator、tfr.keras.model.TypeSpecInputCreator、tfr.keras.model.PreprocessorWithSpec、tfr.keras.model.UnivariateScorer、tfr.keras.model.DNNScorer 和 tfr.keras.model.GAMScorer。這些應該涵蓋大多數常見的使用情境。
請注意,這些函數類別是 Keras 類別,因此不需要序列化。子類別化是自訂這些類別的建議方式。
DatasetBuilder
DatasetBuilder 類別收集與資料集相關的重複程式碼。資料會傳遞至 Pipeline,並呼叫以服務訓練和驗證資料集,以及定義已儲存模型的服務簽名。如圖 1 所示,DatasetBuilder 方法定義在 tfr.keras.pipeline.AbstractDatasetBuilder 基礎類別中,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
在具體的 DatasetBuilder 類別中,您必須實作 build_train_datasets、build_valid_datasets 和 build_signatures。
也提供一個從 feature_spec 建立資料集的具體類別
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
在 DatasetBuilder 中使用的 hparams 在 tfr.keras.pipeline.DatasetHparams 資料類別中指定。
Pipeline
Ranking Pipeline 是基於 tfr.keras.pipeline.AbstractPipeline 類別
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
也提供一個具體的管線類別,可使用與 model.fit 相容的不同 tf.distribute.strategy 訓練模型
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
在 tfr.keras.pipeline.ModelFitPipeline 中使用的 hparams 在 tfr.keras.pipeline.PipelineHparams 資料類別中指定。這個 ModelFitPipeline 類別足以應付大多數 TF Ranking 使用情境。客戶可以輕鬆地針對特定目的對其進行子類別化。
分散式策略支援
如需 TensorFlow 支援的分散式策略的詳細介紹,請參閱分散式訓練。目前,TensorFlow Ranking 管線支援 tf.distribute.MirroredStrategy (預設)、tf.distribute.TPUStrategy、tf.distribute.MultiWorkerMirroredStrategy 和 tf.distribute.ParameterServerStrategy。MirroredStrategy 與大多數具有 CPU 和 GPU 選項的單一機器系統相容。如果沒有分散式策略,請將 strategy 設定為 None。
一般而言,MirroredStrategy 適用於大多數具有 CPU 和 GPU 選項的裝置上的相對小型模型。MultiWorkerMirroredStrategy 適用於不適合單一工作站的大型模型。ParameterServerStrategy 執行非同步訓練,且需要多個可用的工作站。TPUStrategy 非常適合大型模型和巨量資料,但就其可處理的張量形狀而言,彈性較小。
常見問題
使用
RankingPipeline的最少元件集
請參閱上方的範例程式碼。如果我有自己的 Keras
model該怎麼辦
若要使用tf.distribute策略進行訓練,則需要使用策略範圍下定義的所有可訓練變數來建構model。因此,請將您的模型包裝在ModelBuilder中,如下所示:
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
然後將此 model_builder 饋送至管線以進行進一步訓練。