
TensorFlow Ranking 程式庫可協助您運用完善的方法和近期研究的技術,建構可擴充的學習排序機器學習模型。排序模型會接收類似項目清單 (例如網頁),並產生這些項目的最佳化清單,例如從最相關到最不相關的網頁。學習排序模型可用於搜尋、問答、推薦系統和對話系統。您可以使用這個程式庫,透過 Keras API 加速為您的應用程式建構排序模型。Ranking 程式庫也提供工作流程公用程式,讓您更輕鬆地擴充模型實作,以便使用分散式處理策略有效地處理大型資料集。
本總覽簡要概述如何使用這個程式庫開發學習排序模型,介紹程式庫支援的一些進階技術,並討論為支援排序應用程式的分散式處理而提供的工作流程公用程式。
開發學習排序模型
使用 TensorFlow Ranking 程式庫建構模型遵循下列一般步驟
- 使用 Keras 層 (
tf.keras.layers) 指定評分函式 - 定義您要用於評估的指標,例如
tfr.keras.metrics.NDCGMetric - 指定損失函式,例如
tfr.keras.losses.SoftmaxLoss - 使用
tf.keras.Model.compile()編譯模型,並使用您的資料訓練模型
「推薦電影教學課程」會逐步引導您瞭解使用這個程式庫建構學習排序模型的基本知識。請查看「分散式排序支援」章節,以取得建構大規模排序模型的更多資訊。
進階排序技術
TensorFlow Ranking 程式庫提供支援,可套用 Google 研究人員和工程師研究及實作的進階排序技術。以下章節概述其中一些技術,以及如何在您的應用程式中開始使用這些技術。
BERT 清單輸入排序
Ranking 程式庫提供 TFR-BERT 的實作,這是一種評分架構,將 BERT 與 LTR 模型結合,以最佳化清單輸入的排序。以這個方法的範例應用程式為例,假設您有一個查詢和一份包含 n 個文件的清單,您想要根據這個查詢對文件進行排序。LTR 模型不是學習跨 <query, document> 配對獨立評分的 BERT 表示法,而是套用排序損失,以聯合學習 BERT 表示法,從而針對基本事實標籤,最大化整個排序清單的效用。下圖說明了這項技術
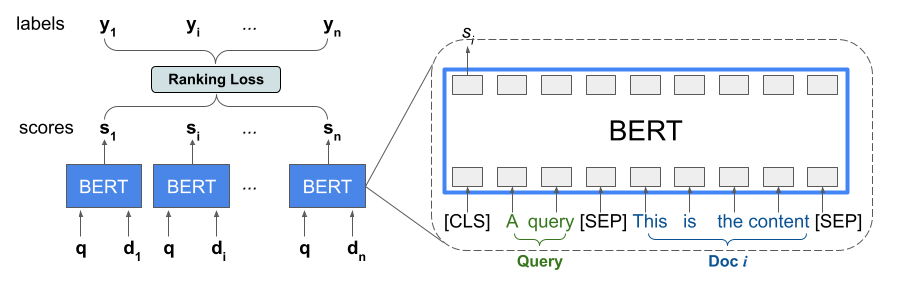
這個方法會將文件清單 (為回應查詢而排序) 攤平為 <query, document> 元組清單。然後,這些元組會饋送至 BERT 預先訓練語言模型。接著,整個文件清單的集區 BERT 輸出會與 TensorFlow Ranking 中提供的其中一種特殊排序損失聯合微調。
這種架構可以顯著提升預先訓練語言模型的效能,在若干熱門排序工作方面產生最先進的效能,尤其是在結合多個預先訓練語言模型時。如需這個技術的更多資訊,請參閱相關研究。您可以透過 TensorFlow Ranking 範例程式碼中的簡單實作開始使用。
神經排序廣義加法模型 (GAM)
對於某些排序系統 (例如貸款資格評估、廣告指定或醫療處置指南),透明度和可解釋性是關鍵考量因素。套用具有充分理解的加權因子的廣義加法模型 (GAM) 有助於提高排序模型的可解釋性和可理解性。
GAM 已針對迴歸和分類工作進行廣泛研究,但如何將其應用於排序應用程式仍不太清楚。例如,雖然可以簡單地將 GAM 應用於模型化清單中的每個個別項目,但模型化項目互動和這些項目的排序環境是更具挑戰性的問題。TensorFlow Ranking 提供 神經排序 GAM 的實作,這是專為排序問題設計的廣義加法模型擴充功能。TensorFlow Ranking GAM 實作可讓您將特定權重新增至模型的特徵。
以下飯店排序系統的圖例使用關聯性、價格和距離作為主要排序特徵。這個模型套用 GAM 技術,根據使用者的裝置環境,以不同方式權衡這些維度。例如,如果查詢來自手機,則距離的權重會更高,因為假設使用者正在尋找附近的飯店。
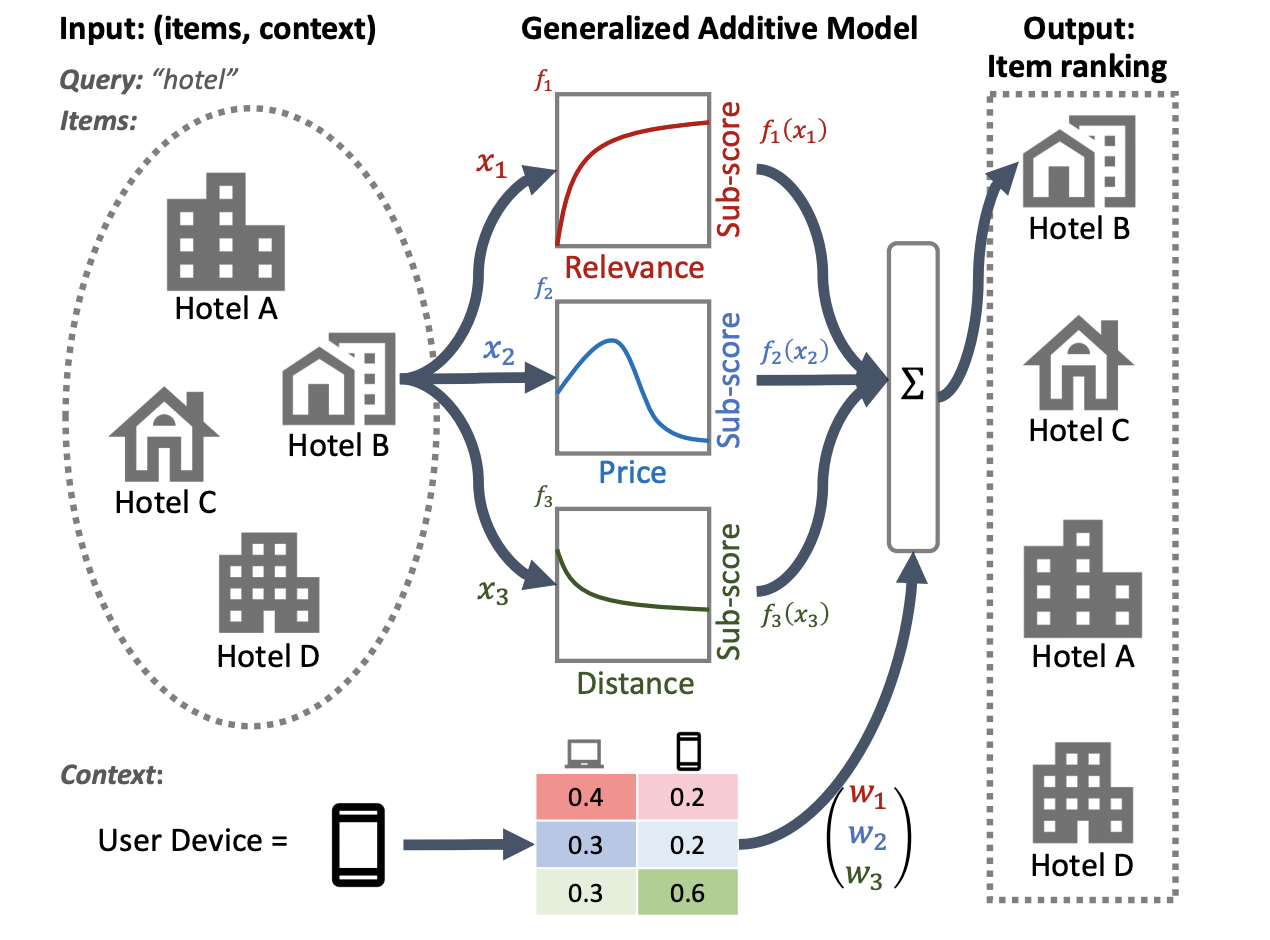
如需將 GAM 用於排序模型的更多資訊,請參閱相關研究。您可以透過 TensorFlow Ranking 範例程式碼中的這個技術範例實作開始使用。
分散式排序支援
TensorFlow Ranking 旨在建構端對端的大規模排序系統:包括資料處理、模型建構、評估和生產環境部署。它可以處理異質密集和稀疏特徵、擴充到數百萬個資料點,並且旨在支援大規模排序應用程式的分散式訓練。
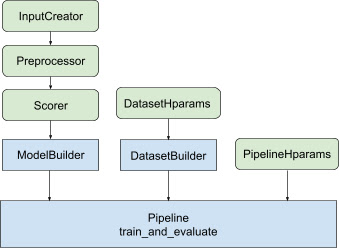
這個程式庫提供最佳化的排序管線架構,以避免重複的樣板程式碼,並建立可從訓練排序模型到提供模型服務的分散式解決方案。排序管線支援大多數 TensorFlow 的分散式策略,包括 MirroredStrategy、TPUStrategy、MultiWorkerMirroredStrategy 和 ParameterServerStrategy。排序管線可以使用 tf.saved_model 格式匯出經過訓練的排序模型,這個格式支援多種輸入簽名。此外,Ranking 管線還提供實用的回呼,包括支援 TensorBoard 資料視覺化和 BackupAndRestore,以協助從長時間執行的訓練作業中的失敗中復原。
Ranking 程式庫透過提供一組 tfr.keras.pipeline 類別來協助建構分散式訓練實作,這些類別採用模型建構器、資料建構器和超參數作為輸入。以 Keras 為基礎的 tfr.keras.ModelBuilder 類別可讓您建立用於分散式處理的模型,並與可擴充的 InputCreator、Preprocessor 和 Scorer 類別搭配使用
TensorFlow Ranking 管線類別也與 DatasetBuilder 搭配使用,以設定訓練資料,其中可以納入 超參數。最後,管線本身可以將一組超參數作為 PipelineHparams 物件納入。
開始使用分散式排序教學課程建構分散式排序模型。