
|
|
|
簡介
大型語言模型 (LLM) 是一類機器學習模型,經過訓練可根據大型資料集產生文字。它們可用於自然語言處理 (NLP) 任務,包括文字產生、問答和機器翻譯。它們以 Transformer 架構為基礎,並在大量的文字資料上進行訓練,通常涉及數十億個字詞。即使是規模較小的 LLM (例如 GPT-2) 也能展現令人印象深刻的效能。將 TensorFlow 模型轉換為更輕巧、更快速且低功耗的模型,讓我們能夠在本機端執行生成式 AI 模型,並享有更佳使用者安全性的優點,因為資料永遠不會離開您的裝置。
本執行手冊說明如何使用 TensorFlow Lite 建構 Android 應用程式以執行 Keras LLM,並提供使用量化技術最佳化模型的建議,否則將需要更大的記憶體和更強大的運算能力才能執行。
我們已開放原始碼 Android 應用程式架構,任何相容的 TFLite LLM 都可以外掛程式。以下是兩個示範
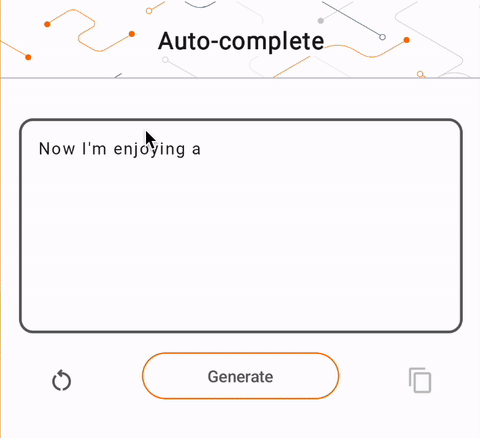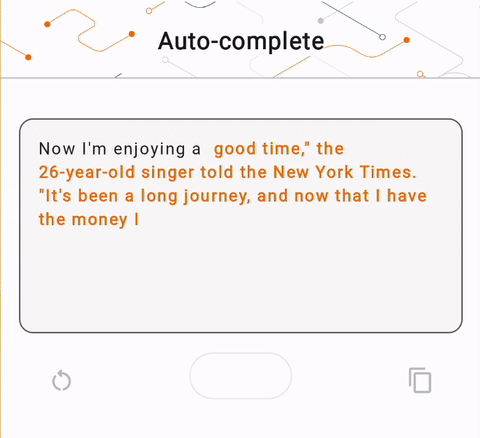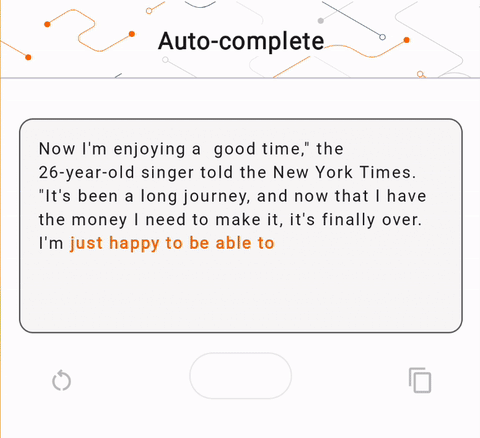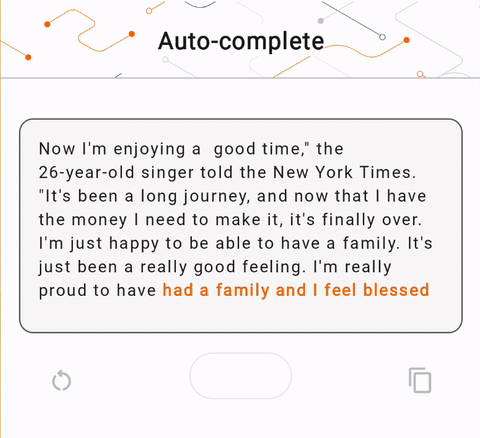
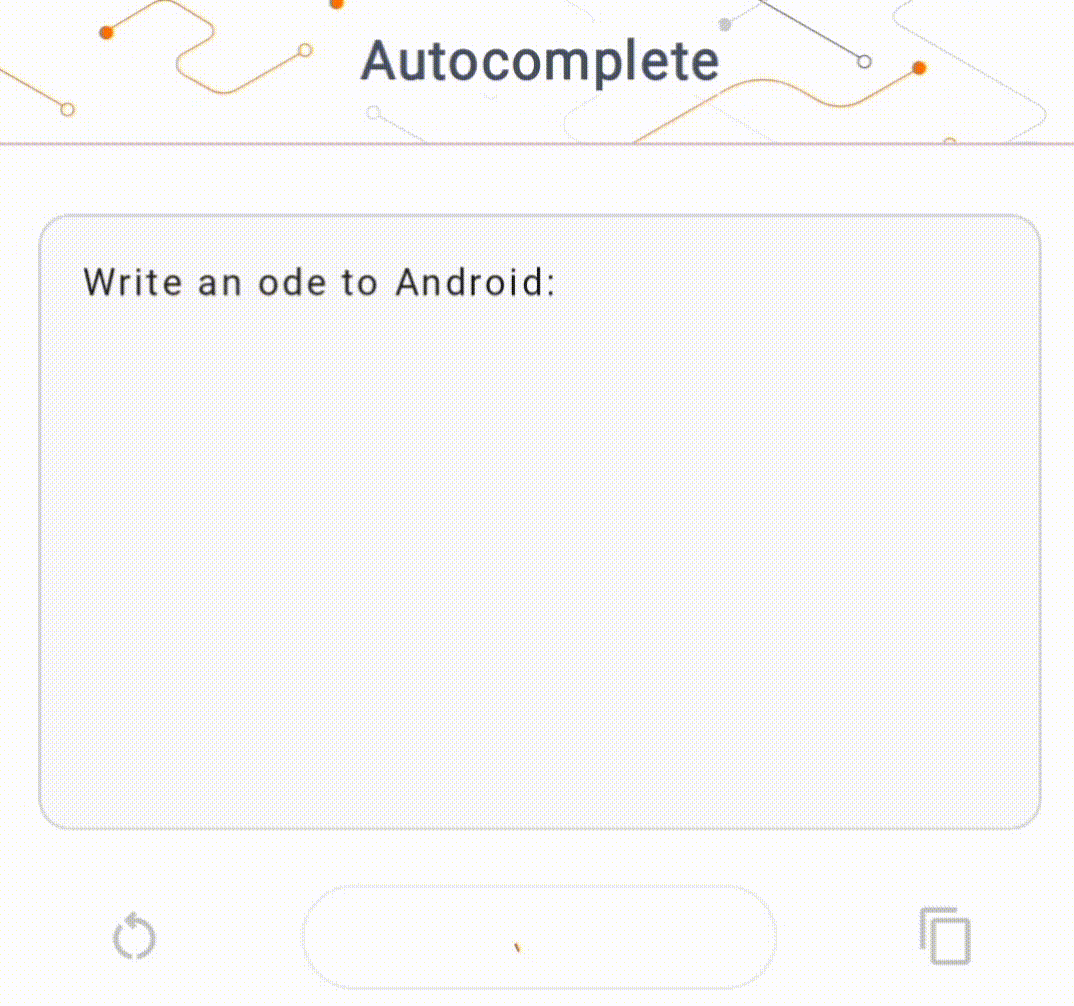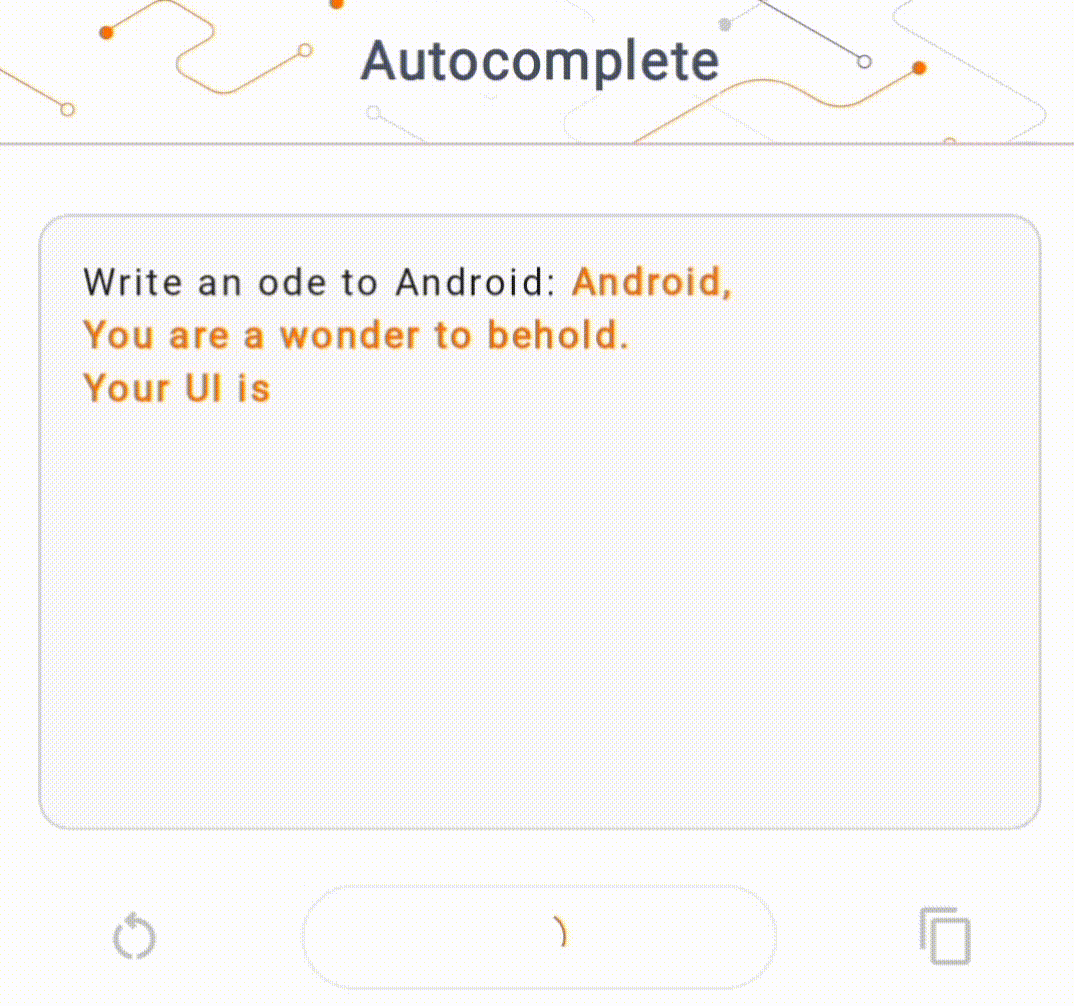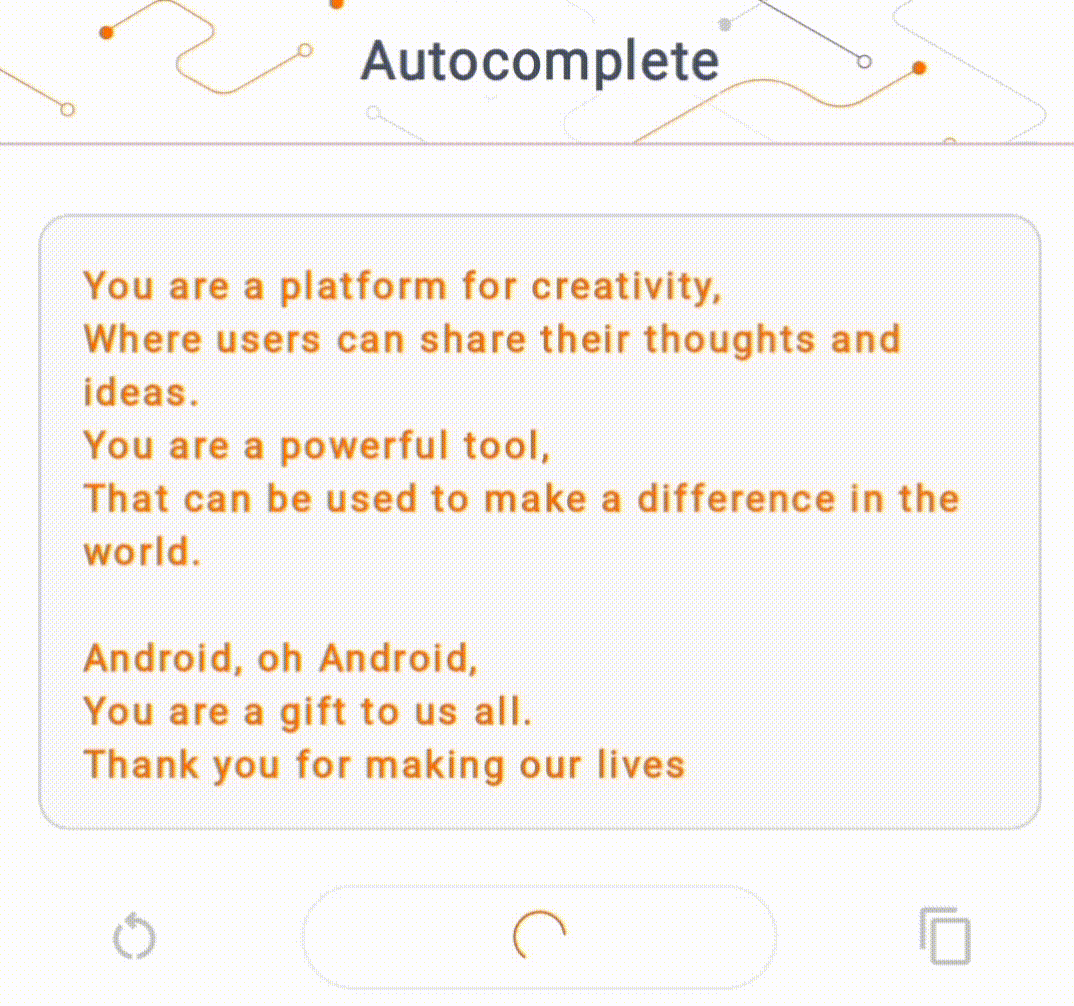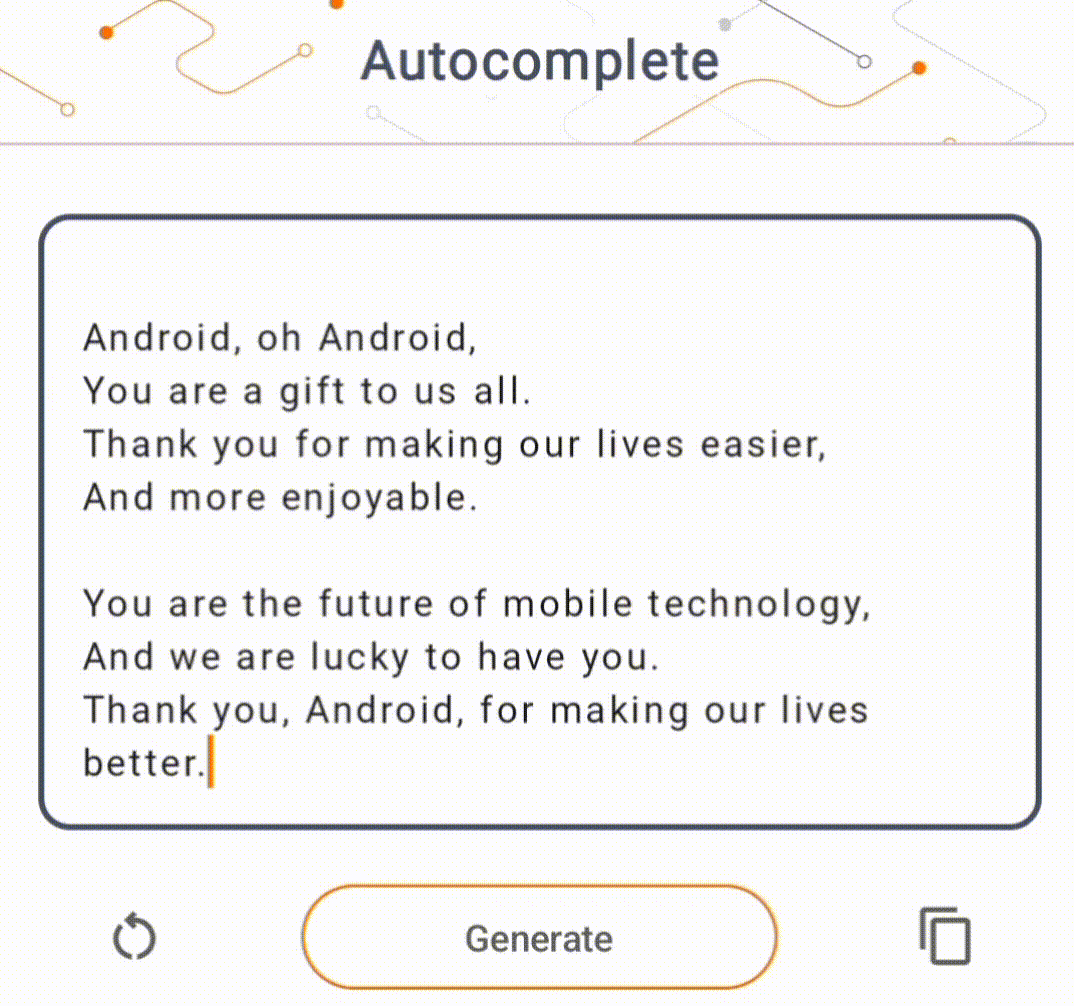
- 在圖 1 中,我們使用 Keras GPT-2 模型在本機端執行文字完成任務。
- 在圖 2 中,我們將 instruction-tuned PaLM 模型 (15 億個參數) 的版本轉換為 TFLite,並透過 TFLite 執行階段執行。
指南
模型撰寫
在本示範中,我們將使用 KerasNLP 來取得 GPT-2 模型。KerasNLP 是一個程式庫,其中包含用於自然語言處理任務的最先進預先訓練模型,並且可以在使用者的整個開發週期中提供支援。您可以在 KerasNLP 儲存庫中查看可用模型的清單。這些工作流程由模組化元件建構而成,這些元件在開箱即用時具有最先進的預設權重和架構,並且在需要更多控制時可以輕鬆自訂。建立 GPT-2 模型可以透過以下步驟完成
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
這三行程式碼之間的一個共通點是 from_preset() 方法,它會從預設架構和/或權重具現化 Keras API 的一部分,因此會載入預先訓練的模型。從這段程式碼片段中,您也會注意到三個模組化元件
Tokenizer:將原始字串輸入轉換為適合 Keras Embedding 層的整數符記 ID。GPT-2 特別使用位元組配對編碼 (BPE) 符記器。
Preprocessor:用於符記化和封裝輸入的層,以便饋送到 Keras 模型。在此,前處理器會在符記化後將符記 ID 張量填補到指定的長度 (256)。
Backbone:遵循 SoTA transformer 主幹架構並具有預設權重的 Keras 模型。
此外,您可以查看 GitHub 上的完整 GPT-2 模型實作。
模型轉換
TensorFlow Lite 是一個行動程式庫,用於在行動裝置、微控制器和其他邊緣裝置上部署方法。第一步是使用 TensorFlow Lite 轉換器將 Keras 模型轉換為更精簡的 TensorFlow Lite 格式,然後使用 TensorFlow Lite 解譯器 (針對行動裝置高度最佳化) 來執行轉換後的模型。
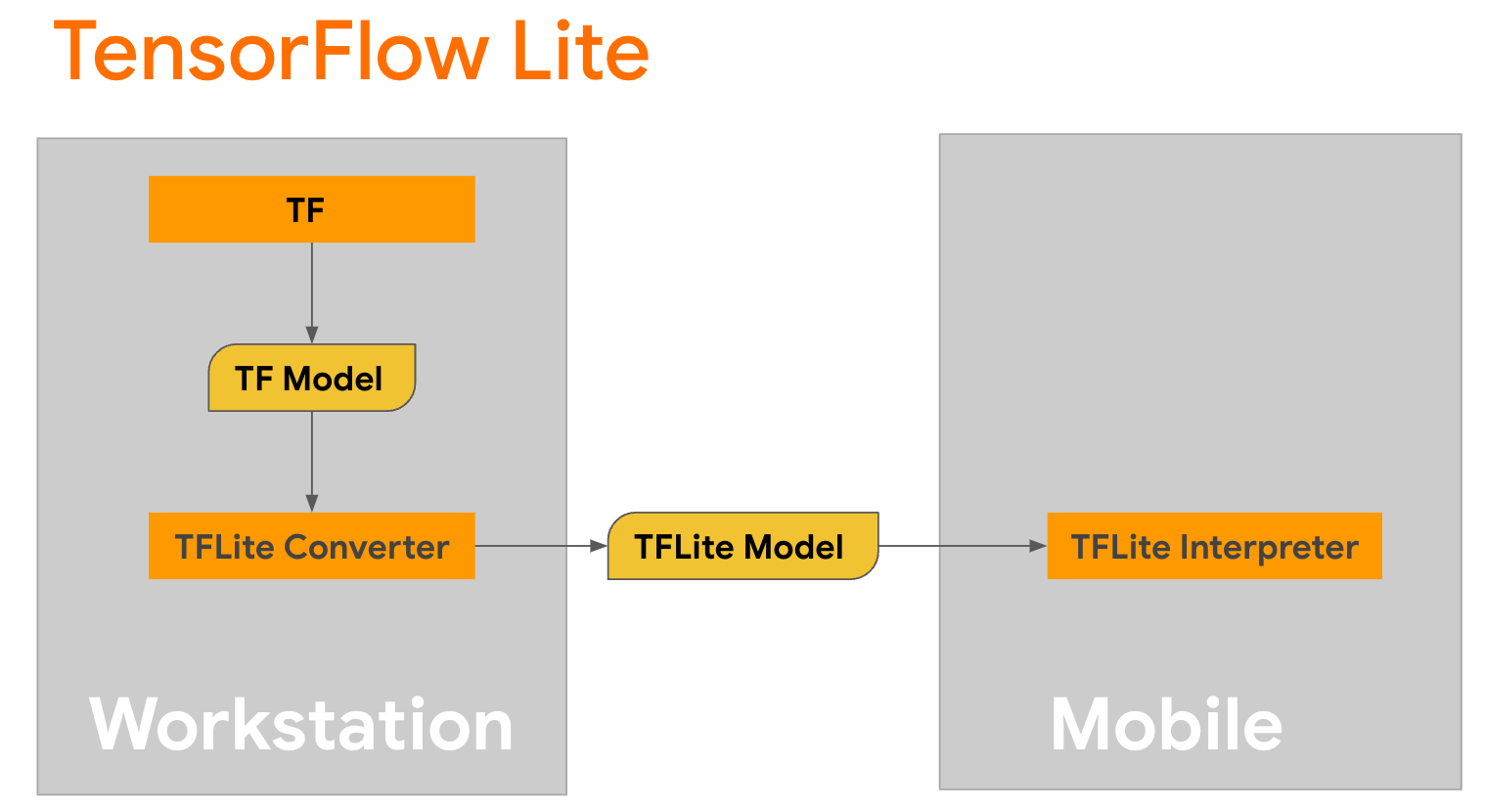 從
從 GPT2CausalLM 中的 generate() 函式開始,它會執行轉換。包裝 generate() 函式以建立具體的 TensorFlow 函式
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
請注意,您也可以使用 TFLiteConverter 中的 from_keras_model() 來執行轉換。
現在定義一個輔助函式,它將使用輸入和 TFLite 模型執行推論。TensorFlow 文字運算不是 TFLite 執行階段中的內建運算,因此您需要新增這些自訂運算,解譯器才能對此模型進行推論。此輔助函式接受輸入和執行轉換的函式,即上述定義的 generator() 函式。
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
您現在可以轉換模型
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
量化
TensorFlow Lite 實作了一種稱為量化的最佳化技術,可以縮減模型大小並加速推論。透過量化過程,32 位元浮點數會對應到較小的 8 位元整數,因此模型大小會縮減 4 倍,以便在現代硬體上更有效率地執行。在 TensorFlow 中有多種量化方法。您可以造訪 TFLite 模型最佳化和 TensorFlow 模型最佳化工具組頁面以取得更多資訊。以下簡要說明量化的類型。
在這裡,您將在 GPT-2 模型上使用後訓練動態範圍量化,方法是將轉換器最佳化標記設定為 tf.lite.Optimize.DEFAULT,其餘轉換過程與之前詳述的相同。我們測試過,使用這種量化技術,在 Pixel 7 上將最大輸出長度設定為 100 時,延遲時間約為 6.7 秒。
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
動態範圍
動態範圍量化是最佳化裝置端模型的建議起點。它可以將模型大小縮減約 4 倍,並且是建議的起點,因為它可以減少記憶體用量並加快運算速度,而您無需提供代表性資料集進行校正。此類量化會在轉換時靜態量化權重 (從浮點數到 8 位元整數)。
FP16
浮點模型也可以透過將權重量化為 float16 類型來最佳化。 float16 量化的優點包括將模型大小縮減一半 (因為所有權重都變成原來的一半大小)、導致準確度損失極小,以及支援可以直接在 float16 資料上運作的 GPU 委派 (這會比在 float32 資料上運算更快)。轉換為 float16 權重的模型仍然可以在 CPU 上執行,無需額外修改。float16 權重會在第一次推論之前升採樣為 float32,這允許以模型大小縮減換取對延遲時間和準確度的最小影響。
完整整數量化
完整整數量化會將 32 位元浮點數 (包括權重和啟動) 轉換為最接近的 8 位元整數。此類量化會產生較小的模型,並提高推論速度,這在使用微控制器時非常有價值。當啟動對量化敏感時,建議使用此模式。
Android 應用程式整合
您可以依照此 Android 範例,將您的 TFLite 模型整合到 Android 應用程式中。
先決條件
如果您尚未安裝 Android Studio,請依照網站上的指示進行安裝。
- Android Studio 2022.2.1 或以上版本。
- 具有 4G 以上記憶體的 Android 裝置或 Android 模擬器
使用 Android Studio 建置和執行
- 開啟 Android Studio,然後從歡迎畫面中,選取「開啟現有的 Android Studio 專案」。
- 從出現的「開啟檔案或專案」視窗中,導覽至並選取您複製 TensorFlow Lite 範例 GitHub 存放區的
lite/examples/generative_ai/android目錄。 - 您可能也需要根據錯誤訊息安裝各種平台和工具。
- 將轉換後的 .tflite 模型重新命名為
autocomplete.tflite,並將其複製到app/src/main/assets/資料夾中。 - 選取選單「Build -> Make Project」以建置應用程式。(Ctrl+F9,取決於您的版本)。
- 按一下選單「Run -> Run 'app'」。(Shift+F10,取決於您的版本)
或者,您也可以使用 gradle wrapper 在命令列中建置它。如需更多資訊,請參閱 Gradle 文件。
(選用) 建置 .aar 檔案
依預設,應用程式會自動下載所需的 .aar 檔案。但如果您想要建置自己的檔案,請切換到 app/libs/build_aar/ 資料夾,執行 ./build_aar.sh。此指令碼將從 TensorFlow Text 中提取必要的運算,並為 Select TF 運算子建置 aar。
編譯後,會產生一個新的檔案 tftext_tflite_flex.aar。取代 app/libs/ 資料夾中的 .aar 檔案,然後重新建置應用程式。
請注意,您仍然需要在 gradle 檔案中包含標準 tensorflow-lite aar。
內容視窗大小
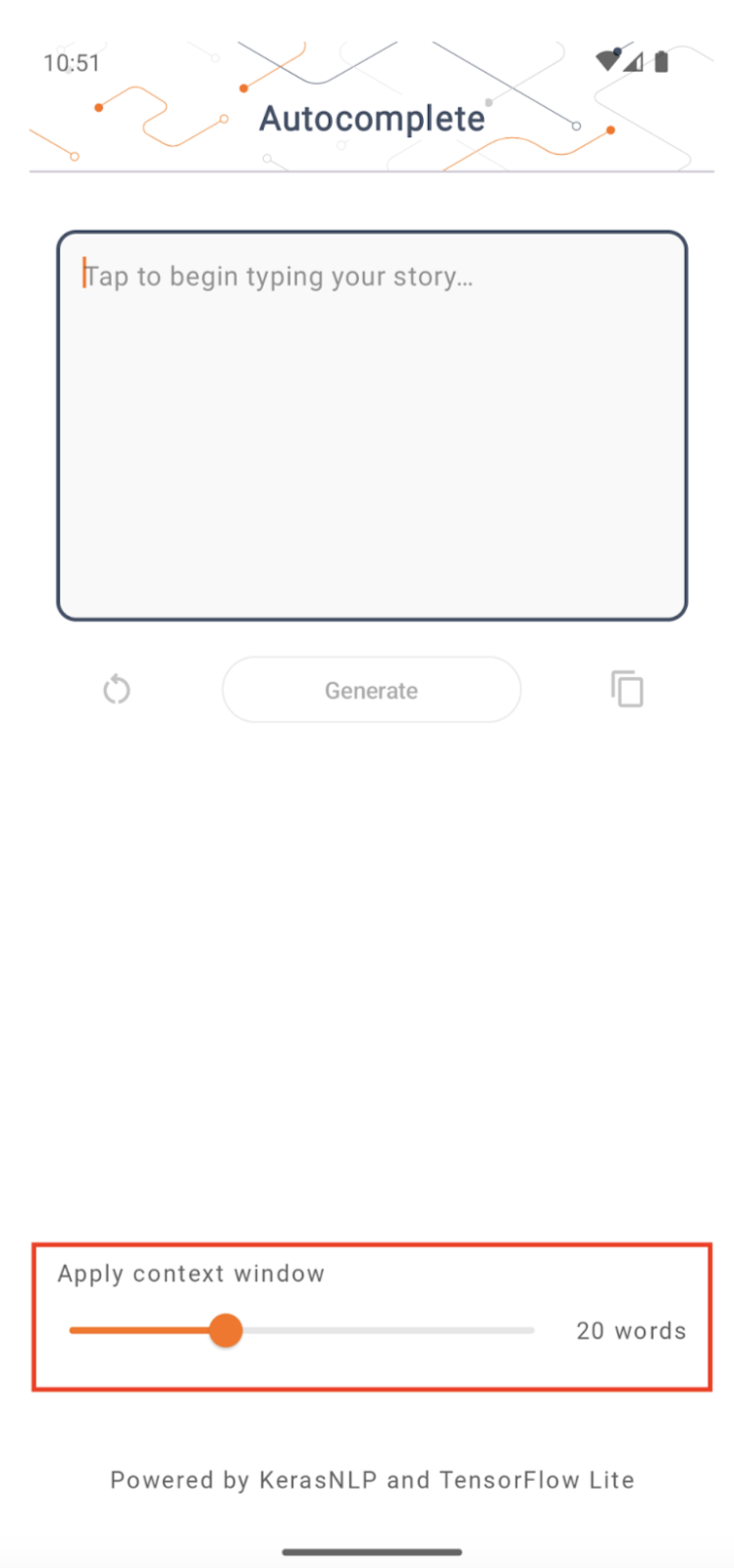
應用程式有一個可變更的參數「內容視窗大小」,這是必要的,因為現今的 LLM 通常具有固定的內容大小,這限制了可以饋送到模型作為「提示」的字詞/符記數量 (請注意,在這種情況下,「字詞」不一定等同於「符記」,因為符記化方法不同)。這個數字很重要,因為
- 設定得太小,模型將沒有足夠的內容來產生有意義的輸出
- 設定得太大,模型將沒有足夠的空間可供使用 (因為輸出序列包含提示)
您可以自行實驗,但將其設定為約輸出序列長度的 50% 是一個好的開始。
安全性和負責任的 AI
如原始 OpenAI GPT-2 公告中所述,GPT-2 模型存在 顯著的注意事項和限制。事實上,現今的 LLM 通常存在一些眾所周知的挑戰,例如幻覺、公平性和偏見;這是因為這些模型是在真實世界的資料上訓練的,這使得它們反映了真實世界的問題。
建立本程式碼研究室僅是為了示範如何使用 TensorFlow 工具組建立由 LLM 驅動的應用程式。本程式碼研究室中產生的模型僅供教育用途,不適用於生產環境。
LLM 生產環境使用需要周全地選擇訓練資料集和全面的安全性降低措施。此 Android 應用程式中提供的一項功能是褻瀆性用語篩選器,它可以拒絕不良的使用者輸入或模型輸出。如果偵測到任何不當語言,應用程式將會傳回拒絕該動作。若要深入瞭解 LLM 背景下的負責任的 AI,請務必觀看 Google I/O 2023 的「生成式語言模型的安全和負責任的開發」技術講座,並查看 負責任的 AI 工具組。