
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
個人化推薦廣泛用於行動裝置上的各種使用案例,例如媒體內容檢索、購物產品建議和後續應用程式推薦。如果您有興趣在尊重使用者隱私的情況下在應用程式中提供個人化推薦,我們建議您探索以下範例和工具組。
開始使用
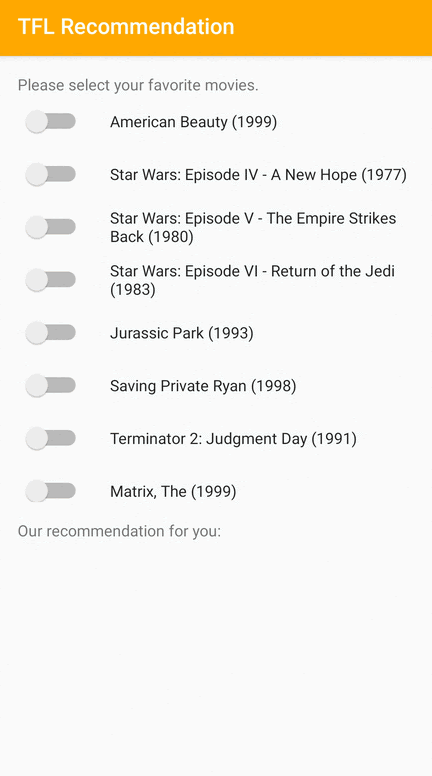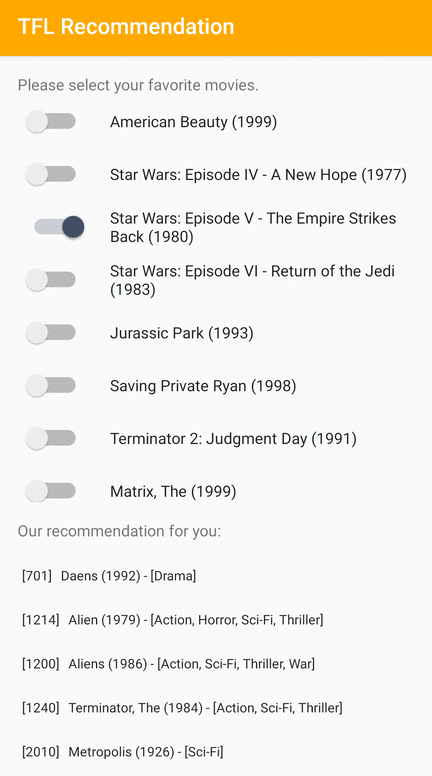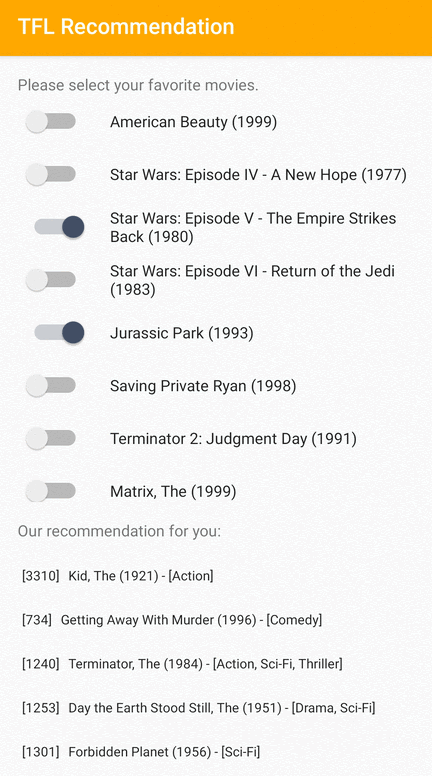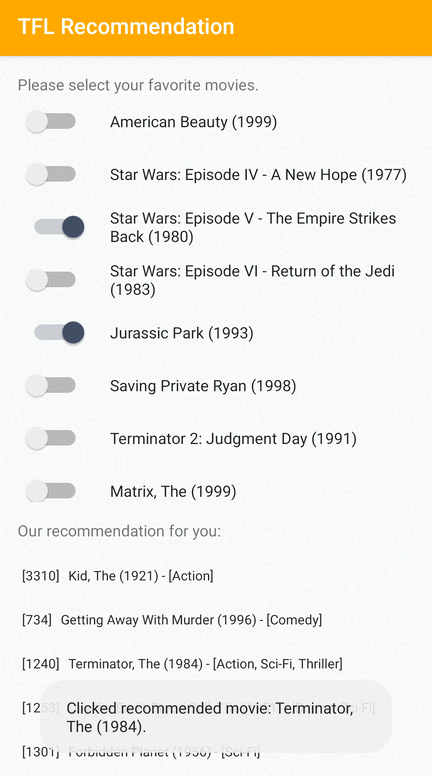
我們提供 TensorFlow Lite 範例應用程式,示範如何在 Android 上向使用者推薦相關項目。
如果您使用的平台不是 Android,或者您已熟悉 TensorFlow Lite API,則可以下載我們的入門推薦模型。
我們也在 Github 中提供訓練腳本,以便您以可配置的方式訓練自己的模型。
瞭解模型架構
我們採用雙編碼器模型架構,其中內容編碼器用於編碼循序使用者歷史記錄,而標籤編碼器用於編碼預測的推薦候選項目。內容和標籤編碼之間的相似性用於表示預測的候選項目滿足使用者需求的可能性。
此程式碼庫提供三種不同的循序使用者歷史記錄編碼技術
- 詞袋編碼器 (BOW):平均使用者活動的嵌入,而不考慮內容順序。
- 卷積神經網路編碼器 (CNN):應用多層卷積神經網路來產生內容編碼。
- 遞迴神經網路編碼器 (RNN):應用遞迴神經網路來編碼內容序列。
為了對每個使用者活動進行建模,我們可以使用活動項目的 ID (基於 ID),或項目的多個特徵 (基於特徵),或兩者的組合。基於特徵的模型利用多個特徵來共同編碼使用者的行為。使用此程式碼庫,您可以透過可配置的方式建立基於 ID 或基於特徵的模型。
訓練後,將匯出 TensorFlow Lite 模型,該模型可以直接在推薦候選項目中提供前 K 個預測。
使用您的訓練資料
除了訓練好的模型外,我們還在 GitHub 中提供開放原始碼 工具組,以便使用您自己的資料訓練模型。您可以按照本教學課程學習如何使用該工具組,並在您自己的行動應用程式中部署訓練好的模型。
請按照本教學課程應用此處使用的相同技術,以使用您自己的資料集訓練推薦模型。
範例
舉例來說,我們使用基於 ID 和基於特徵的方法訓練了推薦模型。基於 ID 的模型僅將電影 ID 作為輸入,而基於特徵的模型則將電影 ID 和電影類型 ID 作為輸入。請參閱以下輸入和輸出範例。
輸入
內容電影 ID
- 獅子王 (ID: 362)
- 玩具總動員 (ID: 1)
- (以及更多)
內容電影類型 ID
- 動畫 (ID: 15)
- 兒童 (ID: 9)
- 音樂劇 (ID: 13)
- 動畫 (ID: 15)
- 兒童 (ID: 9)
- 喜劇 (ID: 2)
- (以及更多)
輸出
- 推薦電影 ID
- 玩具總動員 2 (ID: 3114)
- (以及更多)
效能基準
效能基準數字是使用此處描述的工具產生的。
| 模型名稱 | 模型大小 | 裝置 | CPU |
|---|---|---|---|
| 推薦 (電影 ID 作為輸入) | 0.52 Mb | Pixel 3 | 0.09 毫秒* |
| Pixel 4 | 0.05 毫秒* | ||
| 推薦 (電影 ID 和電影類型作為輸入) | 1.3 Mb | Pixel 3 | 0.13 毫秒* |
| Pixel 4 | 0.06 毫秒* |
* 使用 4 個執行緒。
使用您的訓練資料
除了訓練好的模型外,我們還在 GitHub 中提供開放原始碼 工具組,以便使用您自己的資料訓練模型。您可以按照本教學課程學習如何使用該工具組,並在您自己的行動應用程式中部署訓練好的模型。
請按照本教學課程應用此處使用的相同技術,以使用您自己的資料集訓練推薦模型。
使用您的資料自訂模型的秘訣
本示範應用程式中整合的預先訓練模型是使用 MovieLens 資料集訓練的,您可能需要根據自己的資料修改模型組態,例如詞彙大小、嵌入維度和輸入內容長度。以下是一些秘訣
輸入內容長度:最佳輸入內容長度因資料集而異。我們建議根據標籤事件與長期興趣與短期內容的相關程度來選擇輸入內容長度。
編碼器類型選擇:我們建議根據輸入內容長度選擇編碼器類型。詞袋編碼器適用於短輸入內容長度 (例如 <10),CNN 和 RNN 編碼器為長輸入內容長度帶來更強的摘要能力。
使用底層特徵來表示項目或使用者活動可以提高模型效能、更好地適應新項目、可能縮小嵌入空間,從而減少記憶體消耗,並更易於在裝置上使用。