
邊緣裝置通常記憶體或運算能力有限。可以對模型應用各種最佳化,使其能在這些限制下執行。此外,某些最佳化允許使用專用硬體來加速推論。
TensorFlow Lite 和 TensorFlow 模型最佳化工具組提供各種工具,可盡量減少最佳化推論的複雜性。
建議您在應用程式開發過程中考慮模型最佳化。本文件概述將 TensorFlow 模型部署至邊緣硬體的最佳化實務做法。
為何應最佳化模型
模型最佳化可透過幾種主要方式協助應用程式開發。
縮減大小
某些形式的最佳化可用於縮減模型大小。較小的模型具有下列優點
- 更小的儲存空間:較小的模型在使用者裝置上佔用的儲存空間更少。例如,使用較小模型的 Android 應用程式在使用者行動裝置上佔用的儲存空間會更少。
- 更小的下載大小:較小的模型下載到使用者裝置所需的時間和頻寬更少。
- 更少的記憶體用量:較小的模型在執行時使用的 RAM 更少,這會釋放記憶體供應用程式的其他部分使用,並可轉化為更好的效能和穩定性。
在所有這些情況下,量化都可以縮減模型的大小,但可能會犧牲一些準確性。剪枝和叢集處理可以透過讓模型更容易壓縮來縮減模型下載大小。
延遲時間縮短
「延遲時間」是指使用指定模型執行單次推論所需的時間。某些形式的最佳化可以減少使用模型執行推論所需的運算量,從而縮短延遲時間。延遲時間也可能對功耗產生影響。
目前,量化可用於透過簡化推論期間發生的計算來縮短延遲時間,但可能會犧牲一些準確性。
加速器相容性
某些硬體加速器,例如 Edge TPU,可以使用已正確最佳化的模型極快速地執行推論。
一般而言,這些類型的裝置需要以特定方式量化模型。請參閱每個硬體加速器的文件,以深入瞭解其需求。
取捨
最佳化可能會導致模型準確性發生變化,這必須在應用程式開發過程中加以考慮。
準確性變化取決於要最佳化的個別模型,且難以預先預測。一般而言,針對大小或延遲時間最佳化的模型會損失少量準確性。根據您的應用程式,這可能會或可能不會影響使用者的體驗。在極少數情況下,某些模型可能會因最佳化過程而獲得一些準確性。
最佳化類型
TensorFlow Lite 目前支援透過量化、剪枝和叢集處理進行最佳化。
這些是 TensorFlow 模型最佳化工具組的一部分,該工具組提供與 TensorFlow Lite 相容的模型最佳化技術資源。
量化
量化的運作方式是降低用於表示模型參數的數字精確度,預設情況下這些參數是 32 位元浮點數。這會縮減模型大小並加快運算速度。
下列類型的量化可在 TensorFlow Lite 中使用
| 技術 | 資料需求 | 縮減大小 | 準確性 | 支援的硬體 |
|---|---|---|---|---|
| 後訓練 float16 量化 | 無資料 | 高達 50% | 微不足道的準確性損失 | CPU、GPU |
| 後訓練動態範圍量化 | 無資料 | 高達 75% | 最小的準確性損失 | CPU、GPU (Android) |
| 後訓練整數量化 | 未標記的代表性範例 | 高達 75% | 少量準確性損失 | CPU、GPU (Android)、EdgeTPU、Hexagon DSP |
| 量化感知訓練 | 已標記的訓練資料 | 高達 75% | 最小的準確性損失 | CPU、GPU (Android)、EdgeTPU、Hexagon DSP |
下列決策樹可協助您根據預期的模型大小和準確性,選取可能想要用於模型的量化方案。
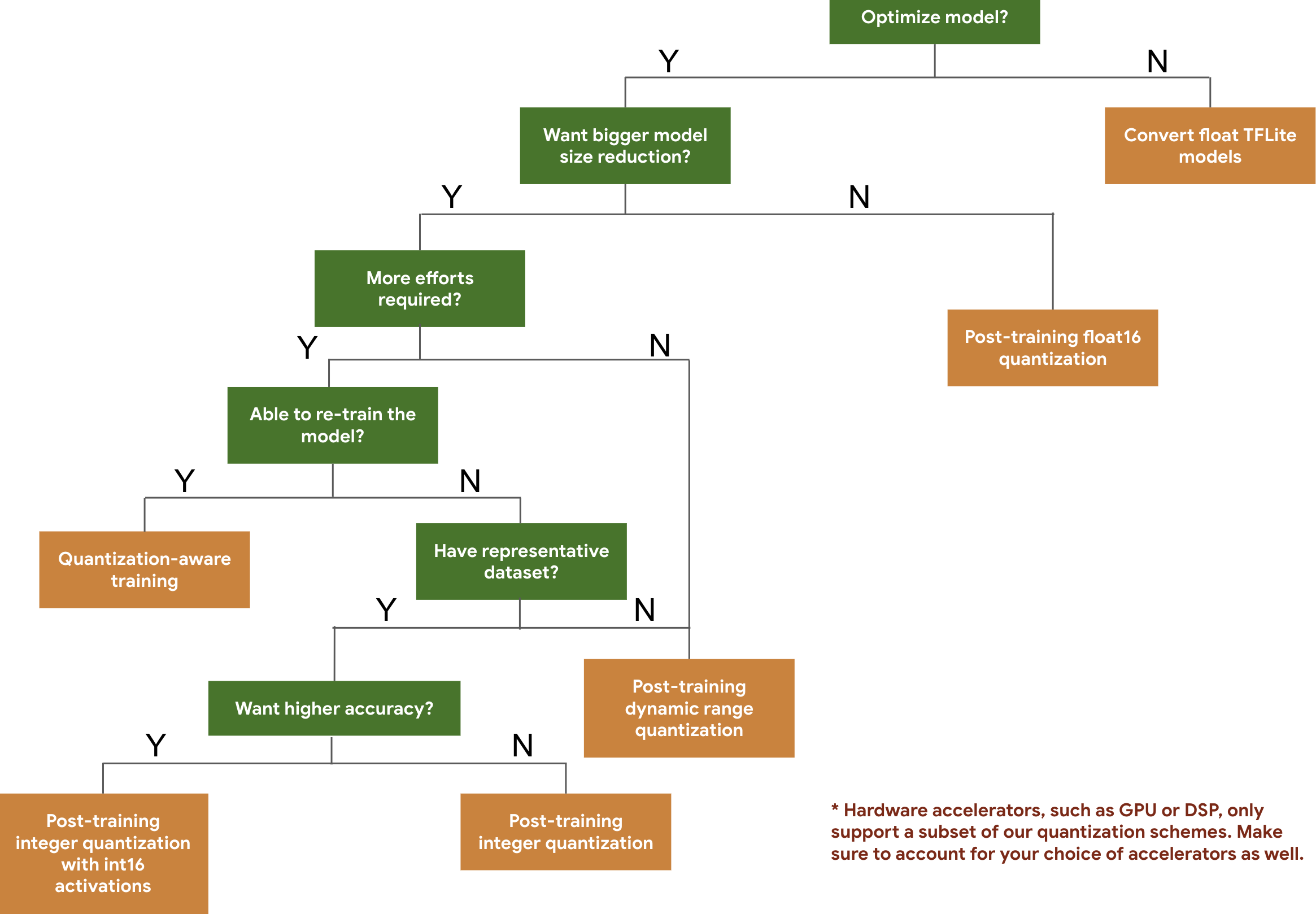
以下是一些模型後訓練量化和量化感知訓練的延遲時間和準確性結果。所有延遲時間數字都是在 Pixel 2 裝置上使用單一大核心 CPU 測量的。隨著工具組的改進,此處的數字也會隨之改進
| 模型 | Top-1 準確性 (原始) | Top-1 準確性 (後訓練量化) | Top-1 準確性 (量化感知訓練) | 延遲時間 (原始) (毫秒) | 延遲時間 (後訓練量化) (毫秒) | 延遲時間 (量化感知訓練) (毫秒) | 大小 (原始) (MB) | 大小 (最佳化) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | 不適用 | 3973 | 2868 | 不適用 | 178.3 | 44.9 |
完整整數量化與 int16 啟動和 int8 權重
使用 int16 啟動進行量化是一種完整的整數量化方案,啟動使用 int16,權重使用 int8。與啟動和權重均使用 int8 的完整整數量化方案相比,此模式可以在保持相似模型大小的情況下,提高量化模型的準確性。當啟動對量化敏感時,建議使用此模式。
注意:目前 TFLite 中僅提供此量化方案的非最佳化參考核心實作,因此預設情況下,與 int8 核心相比,效能會較慢。目前可以透過專用硬體或自訂軟體存取此模式的完整優勢。
以下是一些受益於此模式的模型的準確性結果。
| 模型 | 準確性指標類型 | 準確性 (float32 啟動) | 準確性 (int8 啟動) | 準確性 (int16 啟動) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (unrolled) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | Top-1 準確性 | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | Top-1 準確性 | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(完全符合) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
剪枝
剪枝的運作方式是移除模型中對其預測只有輕微影響的參數。剪枝模型的磁碟大小相同,且執行階段延遲時間相同,但可以更有效地壓縮。這使得剪枝成為縮減模型下載大小的實用技術。
未來,TensorFlow Lite 將為剪枝模型提供延遲時間縮短功能。
叢集處理
叢集處理的運作方式是將模型中每一層的權重分組為預定義數量的叢集,然後共用屬於每個個別叢集的權重之質心值。這減少了模型中唯一權重值的數量,從而降低了其複雜性。
因此,叢集處理模型可以更有效地壓縮,從而提供類似於剪枝的部署優點。
開發工作流程
作為起點,請檢查託管模型中的模型是否適用於您的應用程式。如果沒有,我們建議使用者從後訓練量化工具開始,因為此工具適用範圍廣泛且不需要訓練資料。
對於未達到準確性和延遲時間目標的情況,或硬體加速器支援很重要時,量化感知訓練是更好的選擇。請參閱 TensorFlow 模型最佳化工具組下的其他最佳化技術。