
Copyright 2023 The TF-Agents Authors.
開始使用
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
本教學課程逐步說明如何將 TF-Agents 程式庫用於情境式老虎機問題,其中動作 (手臂) 具有自己的特徵,例如以特徵 (類型、發行年份等) 表示的電影清單。
先決條件
假設讀者已大致熟悉 TF-Agents 的 Bandit 程式庫,尤其是已研讀過TF-Agents 中 Bandit 的教學課程,再閱讀本教學課程。
具備手臂特徵的多臂老虎機
在「經典」情境式多臂老虎機設定中,代理程式在每個時間步收到情境向量 (又稱觀察),且必須從一組有限的編號動作 (手臂) 中選擇,以最大化其累積獎勵。
現在考慮一種情境,其中代理程式向使用者推薦要觀看的下一部電影。每次必須做出決策時,代理程式都會收到關於使用者的情境資訊 (觀看記錄、類型偏好等),以及要從中選擇的電影清單。
我們可以嘗試透過將使用者資訊作為情境來制定此問題,而手臂會是 movie_1, movie_2, ..., movie_K,但此方法有多個缺點
- 動作的數量必須是系統中的所有電影,而且新增電影很麻煩。
- 代理程式必須為每部電影學習模型。
- 未考量電影之間的相似性。
除了為電影編號之外,我們可以做一些更直覺的事情:我們可以使用一組特徵 (包括類型、長度、演員、評分、年份等) 來表示電影。此方法的優點有很多
- 跨電影的類化。
- 代理程式僅學習一個獎勵函數,該函數會使用使用者和電影特徵來建立獎勵模型。
- 輕鬆從系統中移除或新增電影。
在此新設定中,動作的數量甚至不必在每個時間步都相同。
TF-Agents 中的 Per-Arm Bandits
TF-Agents Bandit 套件的開發目的,是讓人們也可以將其用於 per-arm 案例。有 per-arm 環境,而且大多數政策和代理程式也可以在 per-arm 模式下運作。
在我們深入研究編碼範例之前,我們需要必要的匯入。
安裝
pip install tf-agentspip install tf-keras
import os
# Keep using keras-2 (tf-keras) rather than keras-3 (keras).
os.environ['TF_USE_LEGACY_KERAS'] = '1'
匯入
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
參數 - 隨意試驗
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
簡單的 Per-Arm 環境
在另一個教學課程中說明的靜態隨機環境具有 per-arm 對應項。
若要初始化 per-arm 環境,必須定義產生下列項目的函數
- 全域和 per-arm 特徵:這些函數沒有輸入參數,且在呼叫時會產生單一 (全域或 per-arm) 特徵向量。
- 獎勵:此函數將全域和 per-arm 特徵向量的串連作為參數,並產生獎勵。基本上,這是代理程式必須「猜測」的函數。在此值得注意的是,在 per-arm 案例中,每個手臂的獎勵函數都相同。這與經典老虎機案例有根本上的差異,在經典老虎機案例中,代理程式必須獨立估計每個手臂的獎勵函數。
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
現在我們已準備好初始化我們的環境。
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
以下我們可以檢查此環境產生什麼。
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -4., 8., -5., 7., -3., -7., -1., 8., 4., 2., -8.,
5., 9., 7., 4., -6., -1., 1., -10., 1., 3., 1.,
3., 8., -4., 1., 5., -8., 1., -10., 7., 7., -5.,
8., -4., 7., 4., -3., -5., 9.],
[ 9., 2., 3., 1., -2., 7., 6., 2., -9., -3., -2.,
8., 5., -1., 6., -4., 2., -2., -5., 6., -2., -10.,
-3., 3., -7., 5., -3., 4., -2., 0., 2., -4., -6.,
2., 1., -4., 9., -1., 8., -3.],
[ 3., 9., -3., 8., -1., 0., 9., 9., 6., 8., 2.,
1., -5., -3., -4., 7., -7., -4., 2., 3., 4., -4.,
6., -3., -3., 7., 2., 1., -3., -8., 7., -2., 2.,
5., -5., 4., 6., 7., 9., 2.],
[ -2., 7., 8., -3., 8., -10., -9., -5., 7., 9., 0.,
-3., -1., -10., 2., 8., -8., 4., -2., 6., 3., -4.,
-8., -10., 9., -2., -8., -7., -4., 0., 6., -3., 9.,
-4., 1., -5., 4., 2., -2., 0.],
[ -6., 5., -8., 3., 2., 2., -8., 4., -6., 6., 0.,
3., 4., -4., 2., -10., -7., 3., 6., 9., -9., -2.,
6., 0., -4., 8., 0., -4., 0., 3., -3., 9., 0.,
-5., 0., 5., -7., -2., 0., 3.],
[ 4., 9., -2., -6., -3., -10., -2., 8., 8., 3., 0.,
3., -1., -9., 1., -6., 8., -5., 1., 2., 3., -3.,
4., 7., 8., -8., 0., -3., 1., 0., -4., -7., -2.,
-5., -6., 4., -2., 3., 1., -4.],
[ -3., -2., 7., -5., -7., -3., 0., -1., 8., -6., 1.,
9., -9., -6., 3., 2., -6., 6., -10., 6., -6., 6.,
-5., 3., -7., -4., 6., 4., -7., -4., -5., 1., -10.,
5., -6., -9., -3., -2., -10., -4.],
[ 7., 9., 2., 4., -4., -7., 4., -6., 2., 9., 7.,
8., -10., 7., 6., 7., -4., -1., -4., 8., -4., -9.,
-6., -1., 7., -8., -5., -6., -3., 2., -5., 9., -6.,
-6., 8., -2., -1., -2., -5., -6.],
[ 5., 7., 7., -8., -3., 9., 6., 7., 1., -3., -2.,
7., -5., 5., 0., -7., 2., -1., -1., 6., -8., -2.,
-10., 6., 2., 8., 0., 3., 1., -7., 5., 3., 4.,
8., -2., -2., -8., 8., 5., 0.],
[ 1., 0., -2., -6., 7., 8., -5., -8., -7., -8., -4.,
-9., 3., -9., 8., -4., -1., -10., 2., -1., 1., -4.,
6., -1., 4., 1., -7., -4., -8., -6., 7., 4., -8.,
-3., -7., 5., -1., -4., -10., -4.],
[ -7., 4., 0., -9., -8., -6., -7., 8., 3., 7., -7.,
-1., 7., -3., 5., 6., 1., -5., 3., -10., -7., 0.,
-4., -4., -7., 2., -5., 3., 2., -3., 3., -7., -1.,
-10., 9., 1., -2., 3., 4., -8.],
[ 8., -5., -10., 7., 7., -7., 2., 7., -1., -10., 6.,
-4., -5., -3., -8., -2., -2., 3., 1., 2., 1., -6.,
8., -7., 7., 8., -8., -10., 2., -7., 1., -2., -3.,
-6., 9., 4., 2., -1., -7., -1.],
[ 2., 5., -2., -10., -2., 2., 2., -9., -9., -8., -1.,
-7., -9., -4., -2., -3., -9., -3., 5., 5., -1., 0.,
8., -8., 9., -3., 8., 9., 7., -8., 4., -7., 0.,
1., -1., 1., 0., 8., -1., -10.],
[ -6., -1., 9., 4., -8., -5., 8., 0., -10., -10., -10.,
-3., 8., -7., -2., -2., -10., 2., -3., -9., 0., 7.,
0., 2., -7., -6., -6., 3., 2., 6., 8., 9., -10.,
7., -4., -9., 7., -9., 3., -5.],
[ -2., 4., 1., 7., -5., -7., -1., -8., -9., -1., -7.,
4., -7., -7., 7., -2., -5., 3., -10., 9., 9., -5.,
1., 4., 5., 0., -1., 5., 9., 1., 8., -9., -9.,
6., -6., -9., 6., 7., 5., 9.],
[-10., -3., -5., 7., -9., -4., 7., -9., -2., 3., -1.,
-5., -9., -7., -6., 6., -4., -7., 2., 0., 1., -10.,
-3., -10., -7., -4., -9., 0., 3., -8., -7., 7., -2.,
3., 1., 3., -9., -2., -9., -3.],
[ 8., 3., -4., -2., -7., -9., -10., -1., 1., -5., 0.,
6., 0., 5., 9., -3., -10., 5., 9., 0., -8., -2.,
4., 8., 3., 5., 0., -6., -5., -2., -1., 3., -2.,
-3., -1., 8., -1., 1., -1., 5.],
[ -8., 3., -6., 4., -8., 8., -8., 4., 2., 1., 4.,
-8., -9., 8., -8., 3., 2., 0., -10., -5., 5., -3.,
-7., -3., 1., 1., -7., 9., 1., -3., 8., 8., 1.,
7., -2., -9., -3., -6., -1., -10.],
[-10., -5., 4., 4., -9., -5., -8., 6., 5., -9., -8.,
4., -7., 2., 7., 2., 6., -1., 0., 8., -6., 3.,
2., 7., -2., -7., -7., -3., 5., 1., 9., 8., 2.,
-1., 3., -5., 6., -1., -9., -8.],
[ -6., -8., -7., -2., -10., 7., 3., -2., -8., 7., -8.,
-10., 7., 8., -2., 6., 3., 6., -1., 0., -6., -7.,
7., 2., -4., 7., -9., -5., 2., 1., -1., -9., 7.,
9., -5., -10., 6., 9., 6., -2.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 0., 5., 3., ..., -2., 0., -4.],
[-5., 5., -5., ..., 3., 3., 4.],
[ 1., -6., 2., ..., 0., -4., -1.],
...,
[ 1., -3., -5., ..., -5., 4., 3.],
[ 3., -4., 0., ..., -5., -4., 2.],
[-3., -4., -6., ..., -1., -5., -2.]],
[[ 3., -3., -6., ..., -2., -4., -1.],
[-5., 5., -4., ..., -1., 3., -1.],
[-4., 4., 5., ..., 3., -3., -3.],
...,
[-4., -4., 5., ..., -2., 0., -4.],
[ 5., -6., 1., ..., -1., -5., -5.],
[ 5., -4., 5., ..., 4., -4., -4.]],
[[-3., 4., 0., ..., 1., 0., 0.],
[ 1., -1., -5., ..., -4., 5., -4.],
[ 2., 4., 1., ..., -6., -4., -4.],
...,
[ 0., 3., 4., ..., -6., -4., 1.],
[ 3., 5., -5., ..., 5., -2., 4.],
[ 3., -5., 4., ..., 2., -3., -5.]],
...,
[[ 1., -5., -3., ..., -1., -1., 1.],
[-5., 2., -4., ..., -3., 4., -6.],
[-3., -3., 1., ..., 0., -3., -1.],
...,
[-1., 2., -2., ..., -4., 3., 1.],
[-4., 1., -3., ..., 2., -5., -5.],
[-4., -4., -2., ..., 4., -6., -4.]],
[[ 3., 4., 5., ..., -5., -2., -1.],
[-6., 4., -4., ..., 3., -5., -3.],
[ 2., -3., 5., ..., -2., 2., 1.],
...,
[ 4., 2., -1., ..., -5., 5., 1.],
[ 1., -6., 2., ..., 3., 3., 0.],
[ 0., 4., -6., ..., 4., 4., -6.]],
[[ 0., 5., -4., ..., 4., 1., -6.],
[ 3., -1., 4., ..., 1., -1., -2.],
[ 0., -4., -1., ..., 5., 0., 3.],
...,
[ 0., 1., -3., ..., 0., 5., 4.],
[-1., 4., -6., ..., 2., -4., -1.],
[ 4., -2., -6., ..., -5., -5., 5.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-496.27966 94.56397 47.344288 326.10242 82.47867
-287.3221 -148.02356 184.77959 330.40982 -78.458405
436.3813 -13.64361 251.81743 375.51117 6.9300766
414.30618 434.41226 373.14758 374.16064 229.50754 ], shape=(20,), dtype=float32)
我們看到觀察規格是一個具有兩個元素的字典
- 一個具有索引鍵
'global':這是全域情境部分,其形狀符合參數GLOBAL_DIM。 - 一個具有索引鍵
'per_arm':這是 per-arm 情境,其形狀為[NUM_ACTIONS, PER_ARM_DIM]。此部分是每個時間步中每個手臂的手臂特徵的預留位置。
LinUCB 代理程式
LinUCB 代理程式實作同名的 Bandit 演算法,該演算法會估計線性獎勵函數的參數,同時也維護估計值周圍的信賴橢球。代理程式會選擇具有最高估計預期獎勵的手臂,並假設參數位於信賴橢球內。
建立代理程式需要觀察和動作規格的知識。定義代理程式時,我們會將布林參數 accepts_per_arm_features 設定為 True。
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
訓練資料流程
本節簡要介紹 per-arm 特徵如何從政策流向訓練的機制。如果您有興趣,可以隨時跳到下一節 (定義遺憾指標),稍後再回到這裡。
首先,讓我們看一下代理程式中的資料規格。代理程式的 training_data_spec 屬性會指定訓練資料應具有哪些元素和結構。
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32))})
如果我們仔細查看規格的 observation 部分,我們會看到它不包含 per-arm 特徵!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
per-arm 特徵發生了什麼事?若要回答這個問題,首先我們注意到,當 LinUCB 代理程式訓練時,它不需要所有手臂的 per-arm 特徵,只需要所選手臂的特徵。因此,捨棄形狀為 [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] 的張量是有道理的,因為這非常浪費,尤其是在動作數量很大時。
但是,所選手臂的 per-arm 特徵仍然必須存在於某處!為此,我們確保 LinUCB 政策將所選手臂的特徵儲存在訓練資料的 policy_info 欄位中
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
我們從形狀中看到,chosen_arm_features 欄位僅具有一個手臂的特徵向量,而這將是所選的手臂。請注意,policy_info 以及 chosen_arm_features 是訓練資料的一部分,正如我們從檢查訓練資料規格中看到的那樣,因此它在訓練時可用。
定義遺憾指標
在開始訓練迴圈之前,我們先定義一些公用程式函數,以協助計算代理程式的遺憾。這些函數有助於判斷在給定一組動作 (由其手臂特徵給定) 和代理程式隱藏的線性參數的情況下,最佳預期獎勵。
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
現在我們已準備好開始我們的老虎機訓練迴圈。下方的驅動程式負責使用政策選擇動作、將所選動作的獎勵儲存在重播緩衝區中、計算預先定義的遺憾指標,以及執行代理程式的訓練步驟。
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_24657/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
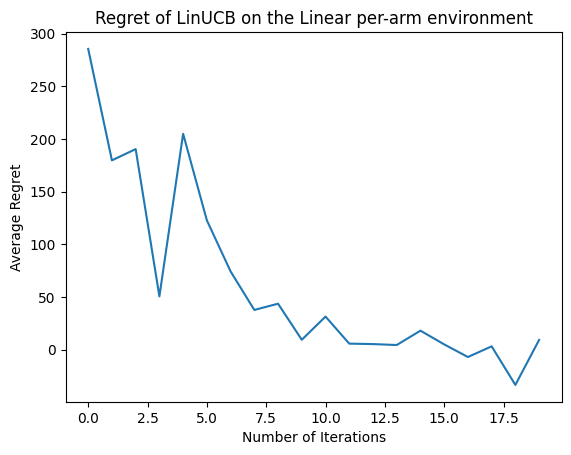
現在讓我們看看結果。如果我們做的一切都正確,代理程式就能夠良好地估計線性獎勵函數,因此政策可以選擇預期獎勵接近最佳獎勵的動作。這由我們上述定義的遺憾指標表示,該指標會下降並接近於零。
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
下一步?
上述範例已在我們的程式碼庫中實作,您也可以從中選擇其他代理程式,包括 Neural epsilon-Greedy 代理程式。