
版權 2023 TF-Agents 作者群。
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
簡介
此範例示範如何在 Minitaur 環境中訓練 軟性演員評論家 代理程式。
如果您已完成 DQN Colab,這應該會讓您感到非常熟悉。值得注意的變更包括
- 將代理程式從 DQN 變更為 SAC。
- 在 Minitaur 上進行訓練,Minitaur 是一個比 CartPole 更複雜的環境。Minitaur 環境旨在訓練四足機器人向前移動。
- 使用 TF-Agents Actor-Learner API 進行分散式強化學習。
此 API 支援使用經驗回放緩衝區和變數容器 (參數伺服器) 的分散式資料收集,以及跨多個裝置的分散式訓練。此 API 的設計宗旨是盡可能簡單且模組化。我們使用 Reverb 作為回放緩衝區和變數容器,並使用 TF DistributionStrategy API 在 GPU 和 TPU 上進行分散式訓練。
如果您尚未安裝以下相依性,請執行
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybulletpip install tf-keras
import os
# Keep using keras-2 (tf-keras) rather than keras-3 (keras).
os.environ['TF_USE_LEGACY_KERAS'] = '1'
設定
首先,我們將匯入我們需要的不同工具。
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
2023-12-22 12:28:38.504926: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-12-22 12:28:38.504976: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-12-22 12:28:38.506679: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
超參數
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
環境
強化學習中的環境代表我們嘗試解決的任務或問題。標準環境可以使用 TF-Agents 中的 suites 輕鬆建立。我們有不同的 suites,可從 OpenAI Gym、Atari、DM Control 等來源載入環境,並提供字串環境名稱。
現在讓我們從 Pybullet 套件載入 Minitaur 環境。
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Nov 28 2023 23:52:03
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/gym/spaces/box.py:84: UserWarning: WARN: Box bound precision lowered by casting to float32
logger.warn(f"Box bound precision lowered by casting to {self.dtype}")
current_dir=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data

在此環境中,目標是讓代理程式訓練一個策略,以控制 Minitaur 機器人並使其盡可能快速地向前移動。單集持續 1000 步,回報將是整個單集的獎勵總和。
讓我們看看環境作為 observation 提供的資訊,策略將使用這些資訊來產生 actions。
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
觀察相當複雜。我們收到 28 個值,代表所有馬達的角度、速度和扭矩。作為回報,環境預期動作有 8 個值,介於 [-1, 1] 之間。這些是所需的馬達角度。
通常我們會建立兩個環境:一個用於在訓練期間收集資料,另一個用於評估。環境以純 Python 撰寫,並使用 NumPy 陣列,Actor Learner API 直接使用這些陣列。
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data
分散式策略
我們使用 DistributionStrategy API 來啟用跨多個裝置 (例如多個 GPU 或 TPU) 執行訓練步驟計算,並使用資料平行處理。訓練步驟
- 接收一批訓練資料
- 將其分散到各個裝置
- 計算前向步驟
- 彙總並計算損失的平均值
- 計算反向步驟並執行梯度變數更新
透過 TF-Agents Learner API 和 DistributionStrategy API,可以輕鬆地在 GPU (使用 MirroredStrategy) 和 TPU (使用 TPUStrategy) 上執行訓練步驟之間切換,而無需變更以下任何訓練邏輯。
啟用 GPU
如果您想嘗試在 GPU 上執行,您首先需要為筆記本啟用 GPU
- 導覽至「編輯」→「筆記本設定」
- 從「硬體加速器」下拉式選單中選取「GPU」
選擇策略
使用 strategy_utils 來產生策略。在底層,傳遞參數
use_gpu = False會傳回tf.distribute.get_strategy(),它使用 CPUuse_gpu = True會傳回tf.distribute.MirroredStrategy(),它使用 TensorFlow 在單一機器上可見的所有 GPU
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
所有變數和 Agents 都需要在 strategy.scope() 下建立,如下所示。
代理程式
若要建立 SAC 代理程式,我們首先需要建立它將訓練的網路。SAC 是一個演員評論家代理程式,因此我們需要兩個網路。
評論家將為我們提供 Q(s,a) 的值估計。也就是說,它會接收觀察和動作作為輸入,並為我們提供該動作對於給定狀態有多好的估計。
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
我們將使用此評論家來訓練演員網路,這將使我們能夠根據觀察產生動作。
ActorNetwork 將預測 tanh 壓縮的 MultivariateNormalDiag 分佈的參數。然後,每當我們需要產生動作時,將會對此分佈進行取樣,並以目前的觀察為條件。
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
有了這些網路,我們現在可以實例化代理程式。
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
回放緩衝區
為了追蹤從環境收集的資料,我們將使用 Reverb,這是 Deepmind 提供的一個有效率、可擴展且易於使用的回放系統。它儲存參與者收集並由學習者在訓練期間使用的經驗資料。
在本教學課程中,這不如 max_size 重要,但在具有非同步收集和訓練的分散式設定中,您可能需要實驗 rate_limiters.SampleToInsertRatio,使用 samples_per_insert 介於 2 到 1000 之間的值。例如
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:162] Initializing TFRecordCheckpointer in /tmpfs/tmp/tmp277hgu8l. [reverb/cc/platform/tfrecord_checkpointer.cc:565] Loading latest checkpoint from /tmpfs/tmp/tmp277hgu8l [reverb/cc/platform/default/server.cc:71] Started replay server on port 43327
回放緩衝區是使用描述要儲存的張量的規格建構的,這些規格可以從代理程式使用 tf_agent.collect_data_spec 取得。
由於 SAC 代理程式需要目前和下一個觀察才能計算損失,因此我們設定 sequence_length=2。
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
現在我們從 Reverb 回放緩衝區產生 TensorFlow 資料集。我們會將其傳遞給學習者,以取樣經驗進行訓練。
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
策略
在 TF-Agents 中,策略代表強化學習中策略的標準概念:給定一個 time_step,產生一個動作或動作分佈。主要方法是 policy_step = policy.step(time_step),其中 policy_step 是一個具名元組 PolicyStep(action, state, info)。policy_step.action 是要應用於環境的 action,state 代表有狀態 (RNN) 策略的狀態,而 info 可能包含輔助資訊,例如動作的對數機率。
代理程式包含兩個策略:
agent.policy— 主要策略,用於評估和部署。agent.collect_policy— 第二個策略,用於資料收集。
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
策略可以獨立於代理程式建立。例如,使用 tf_agents.policies.random_py_policy 建立一個策略,該策略將為每個 time_step 隨機選取一個動作。
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
參與者
參與者管理策略與環境之間的互動。
- 參與者元件包含環境的實例 (作為
py_environment) 和策略變數的副本。 - 每個參與者工作者都會根據策略變數的本機值執行一系列資料收集步驟。
- 變數更新是透過在呼叫
actor.run()之前,在訓練腳本中使用變數容器用戶端實例明確完成的。 - 觀察到的經驗會寫入每個資料收集步驟中的回放緩衝區。
當參與者執行資料收集步驟時,它們會將 (狀態、動作、獎勵) 的軌跡傳遞給觀察者,觀察者會快取這些軌跡並將其寫入 Reverb 回放系統。
我們儲存影格 [(t0,t1) (t1,t2) (t2,t3), ...] 的軌跡,因為 stride_length=1。
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
我們使用隨機策略建立一個參與者,並收集經驗來為回放緩衝區播種。
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
實例化具有收集策略的參與者,以在訓練期間收集更多經驗。
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
建立一個參與者,該參與者將用於在訓練期間評估策略。我們傳入 actor.eval_metrics(num_eval_episodes) 以稍後記錄指標。
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
學習者
學習者元件包含代理程式,並使用回放緩衝區中的經驗資料對策略變數執行梯度步驟更新。在執行一個或多個訓練步驟後,學習者可以將一組新的變數值推送至變數容器。
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:absl:`0/step_type` is not a valid tf.function parameter name. Sanitizing to `arg_0_step_type`.
WARNING:absl:`0/reward` is not a valid tf.function parameter name. Sanitizing to `arg_0_reward`.
WARNING:absl:`0/discount` is not a valid tf.function parameter name. Sanitizing to `arg_0_discount`.
WARNING:absl:`0/observation` is not a valid tf.function parameter name. Sanitizing to `arg_0_observation`.
WARNING:absl:`0/step_type` is not a valid tf.function parameter name. Sanitizing to `arg_0_step_type`.
argv[0]=
argv[0]=
argv[0]=
argv[0]=
argv[0]=
argv[0]=
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tf_agents.distributions.utils.SquashToSpecNormal_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.MultivariateNormalDiag_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/policy/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/collect_policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tf_agents.distributions.utils.SquashToSpecNormal_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.MultivariateNormalDiag_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/collect_policy/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/greedy_policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.Deterministic_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/greedy_policy/assets
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
指標與評估
我們在上方實例化了具有 actor.eval_metrics 的評估參與者,這會在策略評估期間建立最常用的指標
- 平均回報。回報是在環境中執行策略一個單集所獲得的獎勵總和,我們通常會將其在幾個單集上取平均值。
- 平均單集長度。
我們執行參與者以產生這些指標。
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.796275, AverageEpisodeLength = 131.550003
查看 metrics 模組 以取得不同指標的其他標準實作。
訓練代理程式
訓練迴圈涉及從環境收集資料和最佳化代理程式的網路。過程中,我們偶爾會評估代理程式的策略,以了解我們的進度。
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
2023-12-22 12:31:02.824292: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:933] Skipping loop optimization for Merge node with control input: while/body/_121/while/replica_1/Losses/alpha_loss/write_summary/summary_cond/branch_executed/_1946
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
step = 5000: loss = -54.42484664916992
step = 10000: AverageReturn = -0.739843, AverageEpisodeLength = 292.600006
step = 10000: loss = -54.64984130859375
step = 15000: loss = -35.02790451049805
step = 20000: AverageReturn = -1.259167, AverageEpisodeLength = 441.850006
step = 20000: loss = -26.131771087646484
step = 25000: loss = -19.544872283935547
step = 30000: AverageReturn = -0.818176, AverageEpisodeLength = 466.200012
step = 30000: loss = -13.54043197631836
step = 35000: loss = -10.158345222473145
step = 40000: AverageReturn = -1.347950, AverageEpisodeLength = 601.700012
step = 40000: loss = -6.913794040679932
step = 45000: loss = -5.61244010925293
step = 50000: AverageReturn = -1.182192, AverageEpisodeLength = 483.950012
step = 50000: loss = -4.762404441833496
step = 55000: loss = -3.82161545753479
step = 60000: AverageReturn = -1.674075, AverageEpisodeLength = 623.400024
step = 60000: loss = -4.256121635437012
step = 65000: loss = -3.6529903411865234
step = 70000: AverageReturn = -1.215892, AverageEpisodeLength = 728.500000
step = 70000: loss = -4.215447902679443
step = 75000: loss = -4.645144462585449
step = 80000: AverageReturn = -1.224958, AverageEpisodeLength = 615.099976
step = 80000: loss = -4.062835693359375
step = 85000: loss = -2.9989473819732666
step = 90000: AverageReturn = -0.896713, AverageEpisodeLength = 508.149994
step = 90000: loss = -3.086637020111084
step = 95000: loss = -3.242603302001953
step = 100000: AverageReturn = -0.280301, AverageEpisodeLength = 354.649994
step = 100000: loss = -3.288505792617798
[reverb/cc/platform/default/server.cc:84] Shutting down replay server
可視化
圖表
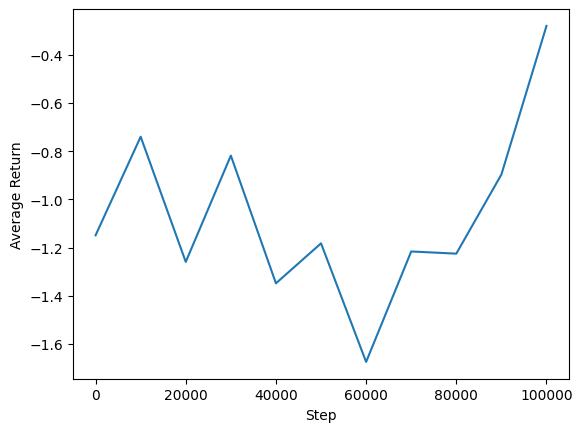
我們可以繪製平均回報與全域步驟的關係圖,以查看代理程式的效能。在 Minitaur 中,獎勵函數基於 minitaur 在 1000 步內行走的距離,並懲罰能量消耗。
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.743763194978237, -0.210612578690052)
影片
透過在每個步驟中呈現環境來可視化代理程式的效能很有幫助。在此之前,讓我們先建立一個函數,將影片嵌入到此 Colab 中。
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
以下程式碼可視化代理程式在幾個單集中的策略
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)