
Copyright 2023 The TF-Agents Authors.
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
簡介
強化學習 (RL) 是一種通用架構,代理程式可在環境中學習執行動作,以最大化獎勵。主要有兩個組成部分:環境 (代表要解決的問題) 和代理程式 (代表學習演算法)。
代理程式和環境會持續互動。在每個時間步,代理程式會根據其政策 \(\pi(a_t|s_t)\) 對環境採取動作,其中 \(s_t\) 是來自環境的目前觀察,並從環境接收獎勵 \(r_{t+1}\) 和下一個觀察 \(s_{t+1}\)。目標是改進政策,以最大化獎勵總和 (回報)。
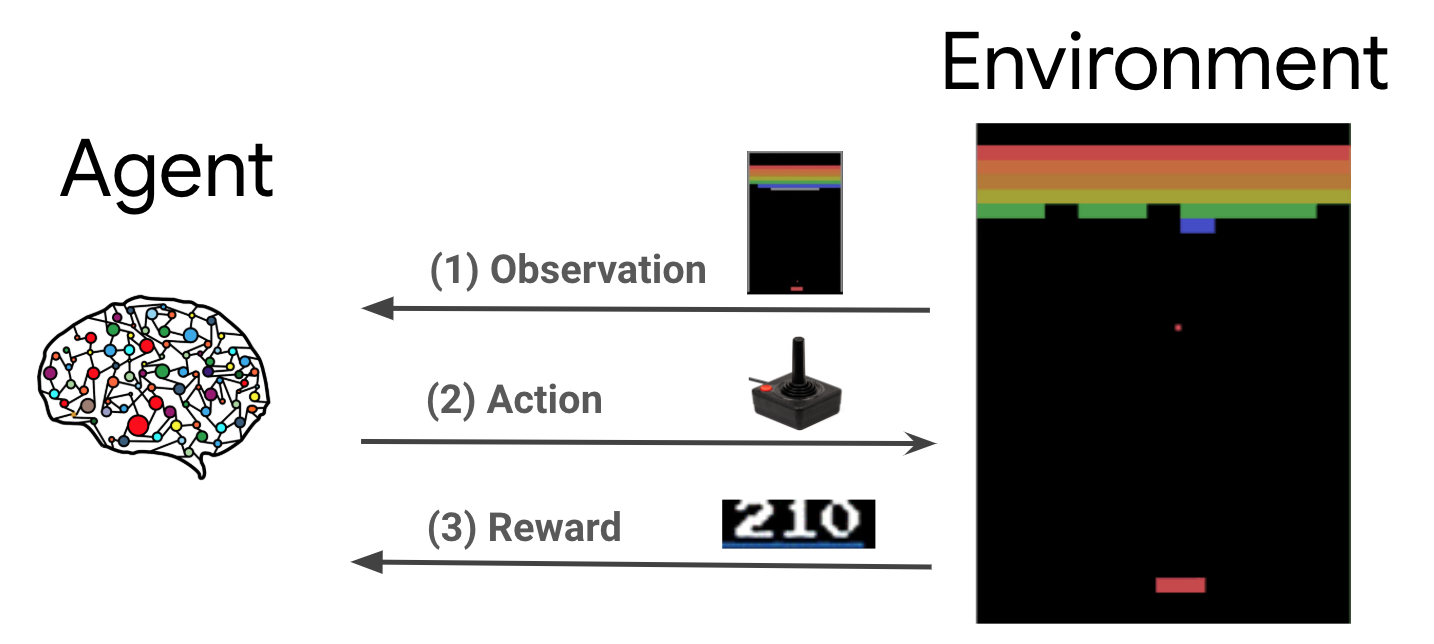
這是一種非常通用的架構,可以為各種循序決策問題建模,例如遊戲、機器人技術等。
Cartpole 環境
Cartpole 環境是最著名的經典強化學習問題之一 (RL 的「Hello, World!」)。桿子連接到可在無摩擦軌道上移動的推車。桿子一開始是直立的,目標是透過控制推車來防止桿子倒下。
- 來自環境的觀察 \(s_t\) 是一個 4D 向量,代表推車的位置和速度,以及桿子的角度和角速度。
- 代理程式可以透過採取 2 個動作 \(a_t\) 之一來控制系統:向右推動推車 (+1) 或向左推動推車 (-1)。
- 對於桿子保持直立的每個時間步,都會提供獎勵 \(r_{t+1} = 1\)。當符合下列其中一項時,情節結束
- 桿子傾倒超過某個角度限制
- 推車移出世界邊緣
- 經過 200 個時間步。
代理程式的目標是學習政策 \(\pi(a_t|s_t)\),以最大化情節中的獎勵總和 \(\sum_{t=0}^{T} \gamma^t r_t\)。此處的 \(\gamma\) 是 \([0, 1]\) 中的折扣因子,用於相對於立即獎勵折扣未來獎勵。此參數可協助我們集中政策,使其更關心快速獲得獎勵。
DQN 代理程式
DQN (深度 Q 網路) 演算法 由 DeepMind 於 2015 年開發。它能夠透過大規模結合強化學習和深度神經網路來解決各種 Atari 遊戲 (某些達到超人水準)。該演算法是透過使用深度神經網路和稱為經驗重播的技術來增強稱為 Q-Learning 的經典強化學習演算法而開發的。
Q-Learning
Q-Learning 基於 Q 函數的概念。政策 \(\pi\) 的 Q 函數 (又稱狀態-動作值函數) \(Q^{\pi}(s, a)\) 衡量從狀態 \(s\) 開始,先採取動作 \(a\) 然後遵循政策 \(\pi\) 所獲得的預期回報或折扣獎勵總和。我們將最佳 Q 函數 \(Q^*(s, a)\) 定義為從觀察 \(s\) 開始,採取動作 \(a\) 並在之後遵循最佳政策可獲得的最大回報。最佳 Q 函數遵循以下 Bellman 最適性方程式
\(\begin{equation}Q^\ast(s, a) = \mathbb{E}[ r + \gamma \max_{a'} Q^\ast(s', a') ]\end{equation}\)
這表示從狀態 \(s\) 和動作 \(a\) 獲得的最大回報是立即獎勵 \(r\) 與回報 (以 \(\gamma\) 折扣) 的總和,該回報是透過在之後遵循最佳政策直到情節結束 (即,來自下一個狀態 \(s'\) 的最大獎勵) 而獲得的。期望值是根據立即獎勵 \(r\) 和可能的下一個狀態 \(s'\) 的分佈計算得出的。
Q-Learning 背後的基本概念是使用 Bellman 最適性方程式作為迭代更新 \(Q_{i+1}(s, a) \leftarrow \mathbb{E}\left[ r + \gamma \max_{a'} Q_{i}(s', a')\right]\),並且可以證明這會收斂到最佳 \(Q\) 函數,即當 \(i \rightarrow \infty\) 時 \(Q_i \rightarrow Q^*\) (請參閱 DQN 論文)。
深度 Q-Learning
對於大多數問題,將 \(Q\) 函數表示為包含 \(s\) 和 \(a\) 的每個組合的值的表格是不切實際的。相反,我們訓練函數逼近器 (例如具有參數 \(\theta\) 的神經網路) 來估計 Q 值,即 \(Q(s, a; \theta) \approx Q^*(s, a)\)。這可以透過在每個步驟 \(i\) 最小化以下損失來完成
\(\begin{equation}L_i(\theta_i) = \mathbb{E}_{s, a, r, s'\sim \rho(.)} \left[ (y_i - Q(s, a; \theta_i))^2 \right]\end{equation}\) 其中 \(y_i = r + \gamma \max_{a'} Q(s', a'; \theta_{i-1})\)
在這裡,\(y_i\) 稱為 TD (時間差分) 目標,\(y_i - Q\) 稱為 TD 誤差。\(\rho\) 代表行為分佈,即從環境收集的轉換 \(\{s, a, r, s'\}\) 的分佈。
請注意,先前迭代 \(\theta_{i-1}\) 的參數是固定的,不會更新。在實務上,我們使用幾次迭代之前的網路參數快照,而不是上次迭代。此副本稱為目標網路。
Q-Learning 是一種離策略演算法,可在環境中執行動作/收集資料時,學習貪婪政策 \(a = \max_{a} Q(s, a; \theta)\)。此行為政策通常是 \(\epsilon\)-貪婪政策,該政策以 \(1-\epsilon\) 的機率選擇貪婪動作,並以 \(\epsilon\) 的機率選擇隨機動作,以確保狀態-動作空間的良好覆蓋率。
經驗重播
為了避免計算 DQN 損失中的完整期望值,我們可以使用隨機梯度下降法將其最小化。如果損失僅使用上次轉換 \(\{s, a, r, s'\}\) 計算,則這會簡化為標準 Q-Learning。
Atari DQN 工作引入了一種稱為經驗重播的技術,以使網路更新更穩定。在資料收集的每個時間步,轉換都會新增至稱為重播緩衝區的循環緩衝區。然後在訓練期間,我們不是僅使用最新的轉換來計算損失及其梯度,而是使用從重播緩衝區取樣的轉換迷你批次來計算它們。這有兩個優點:透過在許多更新中重複使用每個轉換來提高資料效率,以及透過在批次中使用不相關的轉換來提高穩定性。
TF-Agents 中 Cartpole 上的 DQN
TF-Agents 提供訓練 DQN 代理程式所需的所有元件,例如代理程式本身、環境、政策、網路、重播緩衝區、資料收集迴圈和指標。這些元件實作為 Python 函數或 TensorFlow 圖形運算,我們也有用於在它們之間轉換的包裝函式。此外,TF-Agents 支援 TensorFlow 2.0 模式,這使我們能夠在命令式模式下使用 TF。