
TensorFlow Extended 主要元件範例
 在 GitHub 上檢視原始碼
在 GitHub 上檢視原始碼這個 Colab 筆記本範例說明如何使用 TensorFlow Data Validation (TFDV) 來調查和視覺化您的資料集。這包括查看描述性統計資料、推論結構定義、檢查和修正異常狀況,以及檢查資料集中的偏移和偏斜。務必瞭解資料集的特性,包括資料集在生產管道中可能隨時間變化的方式。找出資料中的異常狀況,並比較訓練、評估和服務資料集,以確保這些資料集一致,這一點也很重要。
我們將使用芝加哥市發布的 計程車行程資料集 中的資料。
深入瞭解 Google BigQuery 中的資料集。在 BigQuery UI 中探索完整資料集。
資料集中的欄是
| pickup_community_area | 車資 | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_census_tract |
| dropoff_census_tract | payment_type | 公司 |
| trip_seconds | dropoff_community_area | 小費 |
安裝並匯入套件
安裝 TensorFlow Data Validation 的套件。
升級 Pip
為了避免在本機執行時在系統中升級 Pip,請檢查以確保我們是在 Colab 中執行。本機系統當然可以個別升級。
try:
import colab
!pip install --upgrade pip
except:
pass
安裝 Data Validation 套件
安裝 TensorFlow Data Validation 套件和依附元件,這需要幾分鐘時間。您可能會看到關於不相容依附元件版本的警告和錯誤,您將在下一個章節中解決這些問題。
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
匯入 TensorFlow 並重新載入更新的套件
先前的步驟更新了 Gooogle Colab 環境中的預設套件,因此您必須重新載入套件資源才能解決新的依附元件問題。
import pkg_resources
import importlib
importlib.reload(pkg_resources)
/tmpfs/tmp/ipykernel_183404/3239164719.py:1: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html import pkg_resources <module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pkg_resources/__init__.py'>
在繼續之前,請檢查 TensorFlow 和 Data Validation 的版本。
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
2024-04-30 10:45:22.158704: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-04-30 10:45:22.158751: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-04-30 10:45:22.160265: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered TF version: 2.15.1 TFDV version: 1.15.1
載入資料集
我們將從 Google Cloud Storage 下載資料集。
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmpfs/tmp/tmp7em4lo4u/data: eval serving train /tmpfs/tmp/tmp7em4lo4u/data/eval: data.csv /tmpfs/tmp/tmp7em4lo4u/data/serving: data.csv /tmpfs/tmp/tmp7em4lo4u/data/train: data.csv
計算並視覺化統計資料
首先,我們將使用 tfdv.generate_statistics_from_csv 來計算訓練資料的統計資料。(忽略 snappy 警告)
TFDV 可以計算描述性統計資料,這些資料可快速總覽資料,包括存在的特徵及其值分佈的形狀。
在內部,TFDV 使用 Apache Beam 的資料平行處理架構,以擴展大型資料集統計資料的計算。對於希望更深入整合 TFDV 的應用程式 (例如,在資料產生管道的結尾附加統計資料產生),API 也公開了用於統計資料產生的 Beam PTransform。
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_data_validation/utils/artifacts_io_impl.py:93: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_data_validation/utils/artifacts_io_impl.py:93: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
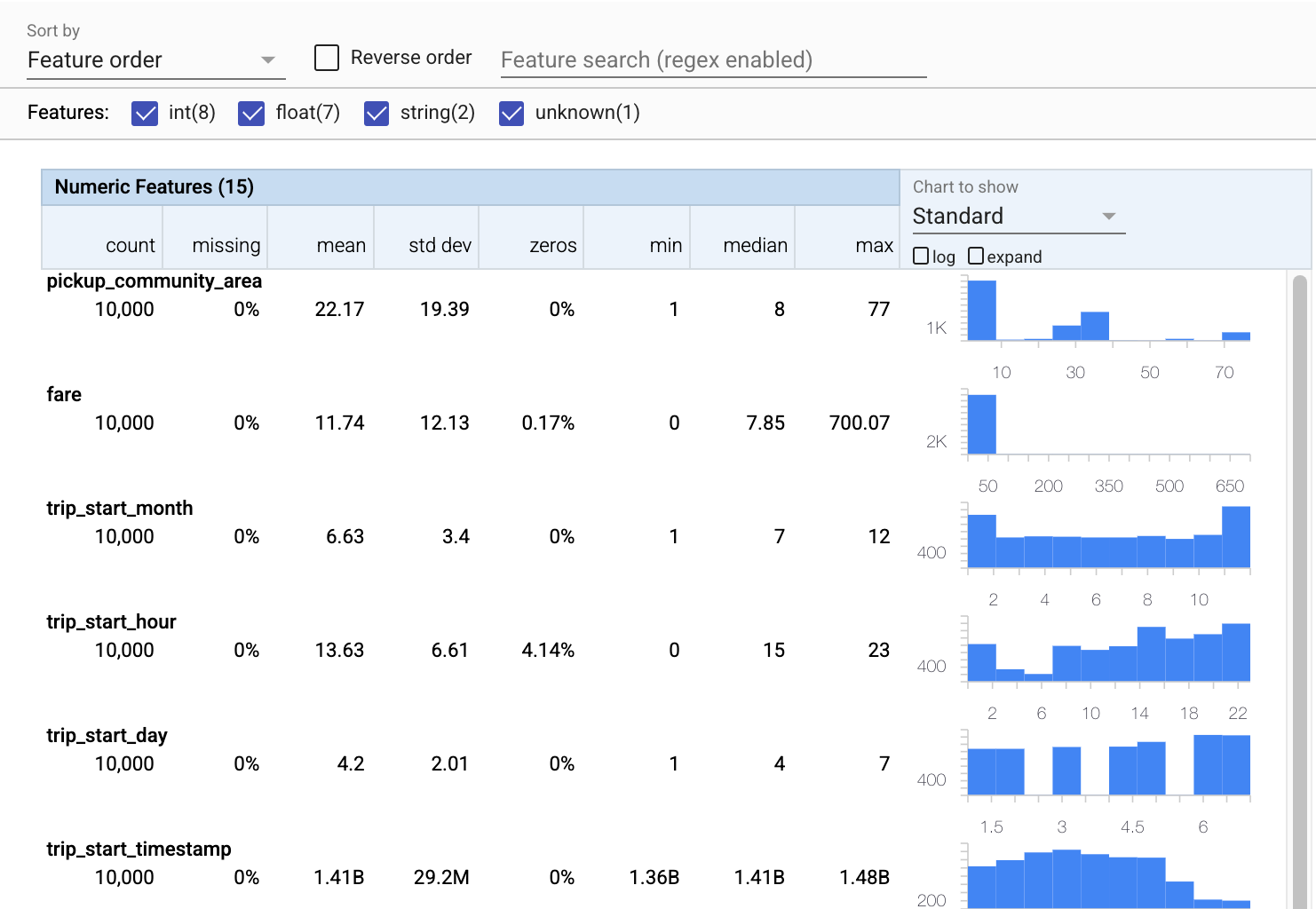
現在讓我們使用 tfdv.visualize_statistics,它使用 Facets 來建立訓練資料的簡潔視覺化
- 請注意,數值特徵和類別特徵會分開視覺化,並顯示圖表來顯示每個特徵的分佈。
- 請注意,具有遺漏值或零值的特徵會以紅色顯示百分比,以視覺化指標指出這些特徵的範例可能存在問題。百分比是特徵具有遺漏值或零值的範例百分比。
- 請注意,
pickup_census_tract的值沒有任何範例。這是維度縮減的機會! - 試著按一下圖表上方的「展開」來變更顯示方式
- 試著將滑鼠游標停留在圖表中的長條上方,以顯示值組距和計數
- 試著在對數和線性刻度之間切換,並注意對數刻度如何揭露更多關於
payment_type類別特徵的詳細資訊 - 試著從「要顯示的圖表」選單中選取「分位數」,並將滑鼠游標停留在標記上方以顯示分位數百分比
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
推論結構定義
現在讓我們使用 tfdv.infer_schema 來建立資料的結構定義。結構定義定義了與 ML 相關的資料限制。範例限制包括每個特徵的資料類型、數值或類別,或其在資料中出現的頻率。對於類別特徵,結構定義也會定義網域 (可接受值的清單)。由於編寫結構定義可能是一項繁瑣的工作,特別是對於具有許多特徵的資料集,因此 TFDV 提供了一種方法,可根據描述性統計資料產生結構定義的初始版本。
正確取得結構定義非常重要,因為我們生產管道的其餘部分將依賴 TFDV 產生的結構定義是否正確。結構定義也提供資料的文件,因此對於不同的開發人員處理相同的資料時很有用。讓我們使用 tfdv.display_schema 來顯示推論的結構定義,以便我們可以檢閱。
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
檢查評估資料是否有錯誤
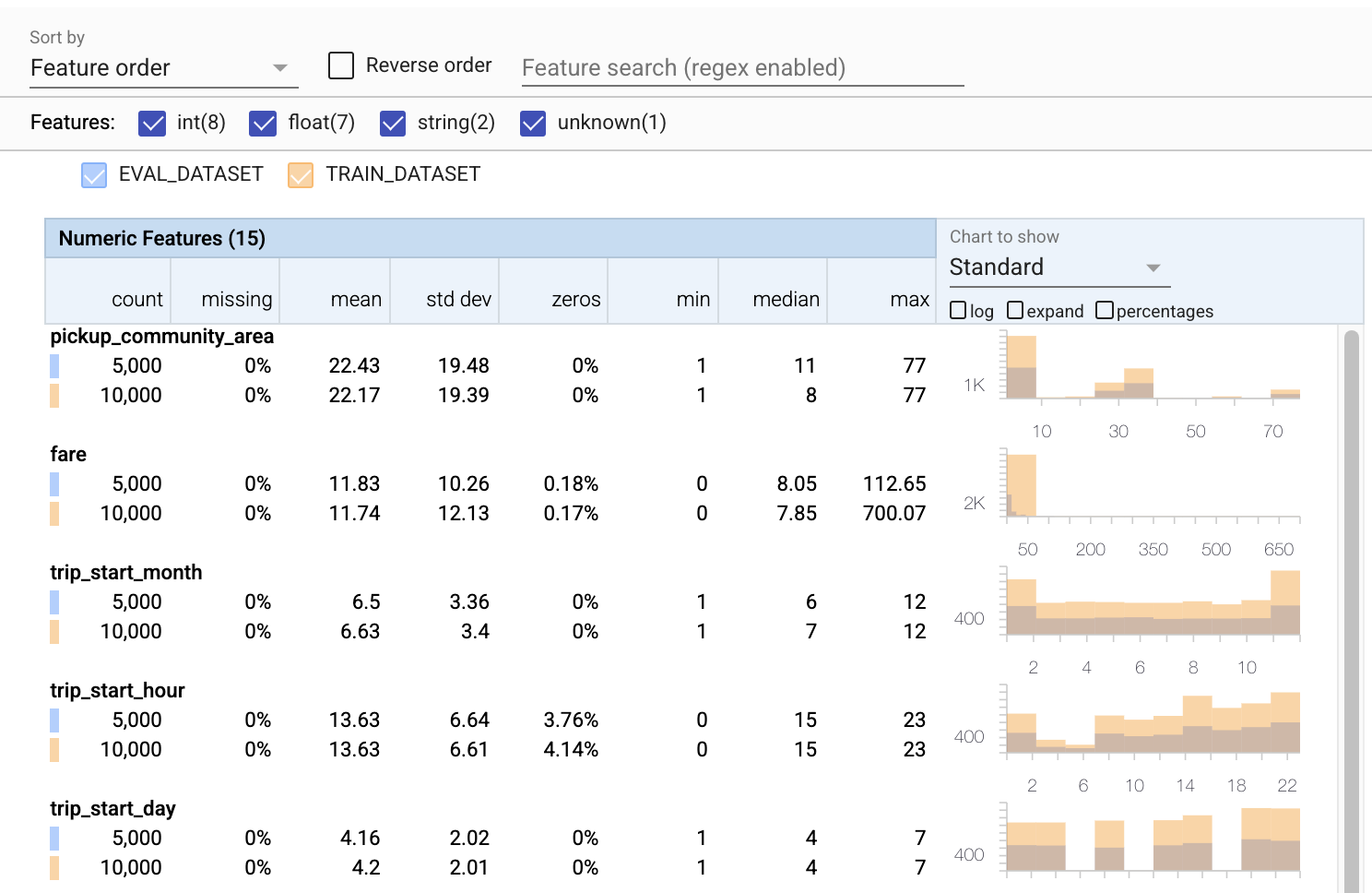
到目前為止,我們只查看了訓練資料。重要的是,我們的評估資料必須與我們的訓練資料一致,包括它使用相同的結構定義。同樣重要的是,評估資料包括數值特徵的值範圍與我們的訓練資料大致相同的範例,以便我們在評估期間對損失表面的涵蓋範圍與訓練期間大致相同。類別特徵也是如此。否則,我們可能會遇到在評估期間未識別出的訓練問題,因為我們沒有評估部分損失表面。
- 請注意,每個特徵現在都包含訓練和評估資料集的統計資料。
- 請注意,圖表現在同時疊加了訓練和評估資料集,方便比較。
- 請注意,圖表現在包含百分比檢視,可以與對數或預設線性刻度結合使用。
- 請注意,
trip_miles的平均值和中位數對於訓練和評估資料集而言有所不同。這會造成問題嗎? - 哇,
tips的最大值對於訓練和評估資料集而言差異很大。這會造成問題嗎? - 按一下「數值特徵」圖表上的展開,然後選取對數刻度。檢閱
trip_seconds特徵,並注意最大值的差異。評估會遺漏部分損失表面嗎?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
檢查評估異常狀況
我們的評估資料集是否符合訓練資料集的結構定義?這對於類別特徵尤其重要,因為我們想要識別可接受值的範圍。
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
修正結構定義中的評估異常狀況
糟糕!看來我們的評估資料中有些 company 的新值,而我們的訓練資料中沒有這些值。我們也有 payment_type 的新值。這些應該被視為異常狀況,但我們決定如何處理它們取決於我們對資料的網域知識。如果異常狀況確實指出資料錯誤,則應修正基礎資料。否則,我們可以簡單地更新結構定義,以包含評估資料集中的值。
除非我們變更評估資料集,否則我們無法修正所有問題,但我們可以修正結構定義中我們覺得可以接受的問題。這包括放寬我們對於特定特徵的異常狀況的看法,以及更新我們的結構定義以包含類別特徵的遺漏值。TFDV 讓我們能夠發現我們需要修正的問題。
現在讓我們進行這些修正,然後再次檢閱。
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
嘿,看看那個!我們驗證了訓練和評估資料現在一致了!感謝 TFDV ;)
結構定義環境
我們也為這個範例分割出「服務」資料集,因此我們也應該檢查該資料集。根據預設,管道中的所有資料集都應該使用相同的結構定義,但通常會有例外情況。例如,在監督式學習中,我們需要在資料集中包含標籤,但當我們為推論提供模型服務時,將不會包含標籤。在某些情況下,有必要引入輕微的結構定義變更。
環境可用於表達這類需求。特別是,結構定義中的特徵可以使用 default_environment、in_environment 和 not_in_environment 與一組環境建立關聯。
例如,在這個資料集中,tips 特徵包含作為訓練的標籤,但在服務資料中遺失了。如果未指定環境,它將顯示為異常狀況。
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
我們將在下方處理 tips 特徵。我們的 trip seconds 中也有一個 INT 值,而我們的結構定義預期是 FLOAT。透過讓我們注意到這種差異,TFDV 有助於揭露訓練和服務資料產生方式的不一致之處。很容易在模型效能受到影響之前 (有時是災難性地受到影響) 沒有注意到這類問題。這可能不是一個重大問題,但在任何情況下,這都應該是進一步調查的原因。
在這種情況下,我們可以安全地將 INT 值轉換為 FLOAT,因此我們想要告訴 TFDV 使用我們的結構定義來推論類型。現在就來執行。
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
現在我們只有 tips 特徵 (這是我們的標籤) 顯示為異常狀況 («已捨棄欄»)。當然,我們不希望在服務資料中包含標籤,因此讓我們告訴 TFDV 忽略它。
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
檢查偏移和偏斜
除了檢查資料集是否符合結構定義中設定的預期之外,TFDV 也提供偵測偏移和偏斜的功能。TFDV 透過比較結構定義中指定的偏移/偏斜比較器的不同資料集統計資料來執行此檢查。
偏移
偏移偵測支援類別特徵,以及資料的連續跨度之間 (即跨度 N 和跨度 N+1 之間),例如不同日期的訓練資料之間。我們使用 L-infinity 距離來表示偏移,您可以設定閾值距離,以便在偏移高於可接受範圍時收到警告。設定正確的距離通常是一個反覆的過程,需要網域知識和實驗。
偏斜
TFDV 可以偵測資料中的三種不同類型的偏斜:結構定義偏斜、特徵偏斜和分佈偏斜。
結構定義偏斜
當訓練和服務資料不符合相同的結構定義時,就會發生結構定義偏斜。訓練和服務資料都應該遵守相同的結構定義。兩者之間的任何預期偏差 (例如標籤特徵僅存在於訓練資料中,而不存在於服務資料中) 都應透過結構定義中的環境欄位指定。
特徵偏斜
當模型訓練所用的特徵值與它在服務時間看到的特徵值不同時,就會發生特徵偏斜。例如,當發生下列情況時,可能會發生這種情況
- 提供某些特徵值的資料來源在訓練和服務時間之間已修改
- 訓練和服務之間產生特徵的邏輯不同。例如,如果您僅在兩個程式碼路徑之一中套用某些轉換。
分佈偏斜
當訓練資料集的分佈與服務資料集的分佈顯著不同時,就會發生分佈偏斜。分佈偏斜的主要原因之一是使用不同的程式碼或不同的資料來源來產生訓練資料集。另一個原因是取樣機制有缺陷,選擇了服務資料的非代表性子樣本進行訓練。
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
在這個範例中,我們確實看到一些偏移,但遠低於我們設定的閾值。
凍結結構定義
現在結構定義已檢閱和策劃,我們將其儲存在檔案中,以反映其「凍結」狀態。
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
何時使用 TFDV
很容易認為 TFDV 僅適用於訓練管道的開始,就像我們在這裡所做的那樣,但實際上它有很多用途。以下是一些其他用途
- 驗證新的推論資料,以確保我們沒有突然開始收到不良特徵
- 驗證新的推論資料,以確保我們的模型已在決策表面的該部分上進行訓練
- 在我們轉換資料並完成特徵工程 (可能使用 TensorFlow Transform) 後驗證我們的資料,以確保我們沒有做錯事