
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
量子電腦已證實能在特定問題領域提供運算優勢。量子強化學習 (QRL) 領域旨在藉由設計仰賴量子運算模型的強化學習代理程式,來運用此優勢。
在本教學課程中,您將實作兩種以參數化/變分量子電路 (PQC 或 VQC) 為基礎的強化學習演算法,分別是策略梯度和深度 Q 學習實作。這些演算法分別由 [1] Jerbi 等人 和 [2] Skolik 等人 提出。
您將在 TFQ 中實作具有資料重新上傳功能的 PQC,並將其用作
- 透過策略梯度方法訓練的強化學習策略,
- 透過深度 Q 學習訓練的 Q 函數近似器,
各自解決來自 OpenAI Gym 的基準測試任務 CartPole-v1。請注意,如 [1] 和 [2] 中所示,這些代理程式也可用於解決來自 OpenAI Gym 的其他任務環境,例如 FrozenLake-v0、MountainCar-v0 或 Acrobot-v1。
此實作的功能
- 您將學習如何使用
tfq.layers.ControlledPQC實作具有資料重新上傳功能的 PQC,這在 QML 的許多應用中都會出現。此實作也自然允許在 PQC 的輸入端使用可訓練的縮放參數,以提高其表現力, - 您將學習如何在 PQC 的輸出端實作具有可訓練權重的可觀測值,以允許彈性的輸出值範圍,
- 您將學習如何使用
tf.keras.Model訓練非顯著 ML 損失函數,亦即與model.compile和model.fit不相容的函數,方法是使用tf.GradientTape。
設定
安裝 TensorFlow
pip install tensorflow==2.15.0
安裝 TensorFlow Quantum
pip install tensorflow-quantum==0.7.3
安裝 Gym
pip install gym==0.18.0
現在匯入 TensorFlow 和模組依附元件
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
import tensorflow as tf
import tensorflow_quantum as tfq
import gym, cirq, sympy
import numpy as np
from functools import reduce
from collections import deque, defaultdict
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
tf.get_logger().setLevel('ERROR')
1. 建構具有資料重新上傳功能的 PQC
您要實作的兩種強化學習演算法的核心,是將環境中代理程式的狀態 \(s\) (即 numpy 陣列) 作為輸入,並輸出期望值向量的 PQC。然後,這些期望值會經過後處理,以產生代理程式的策略 \(\pi(a|s)\) 或近似 Q 值 \(Q(s,a)\)。如此一來,PQC 便在現代深度強化學習演算法中扮演著與深度神經網路類似的角色。
將輸入向量編碼到 PQC 中的一種常見方法是使用單量子位元旋轉,其中旋轉角度由輸入向量的分量控制。為了獲得 高表現力模型,這些單量子位元編碼並非僅在 PQC 中執行一次,而是在多個「重新上傳」中執行,並與變分閘交錯。此類 PQC 的佈局如下所示
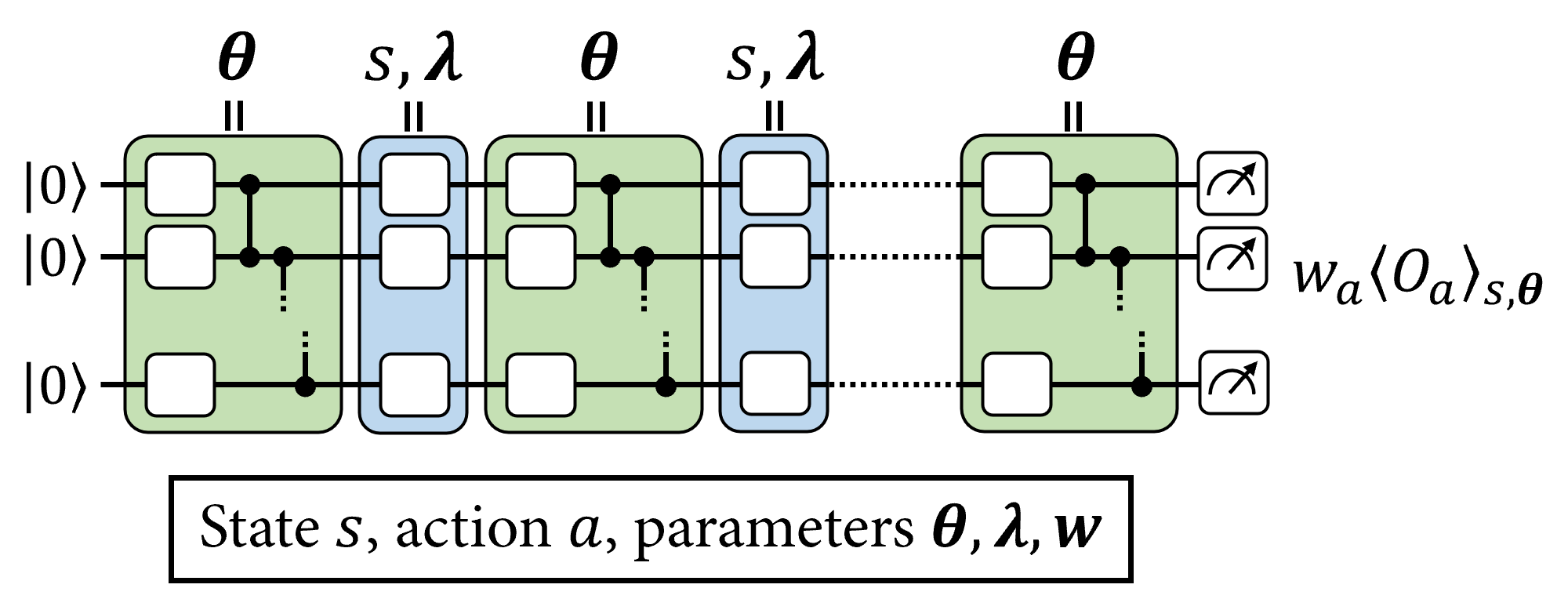
如 [1] 和 [2] 中所述,進一步增強資料重新上傳 PQC 的表現力和可訓練性的一種方法,是為 PQC 的每個編碼閘使用可訓練的輸入縮放參數 \(\boldsymbol{\lambda}\),並在其輸出端使用可訓練的可觀測權重 \(\boldsymbol{w}\)。
1.1 用於 ControlledPQC 的 Cirq 電路
第一步是在 Cirq 中實作將用作 PQC 的量子電路。為此,首先定義將在電路中應用的基本單元,即任意單量子位元旋轉和 CZ 閘的糾纏層
def one_qubit_rotation(qubit, symbols):
"""
Returns Cirq gates that apply a rotation of the bloch sphere about the X,
Y and Z axis, specified by the values in `symbols`.
"""
return [cirq.rx(symbols[0])(qubit),
cirq.ry(symbols[1])(qubit),
cirq.rz(symbols[2])(qubit)]
def entangling_layer(qubits):
"""
Returns a layer of CZ entangling gates on `qubits` (arranged in a circular topology).
"""
cz_ops = [cirq.CZ(q0, q1) for q0, q1 in zip(qubits, qubits[1:])]
cz_ops += ([cirq.CZ(qubits[0], qubits[-1])] if len(qubits) != 2 else [])
return cz_ops
現在,使用這些函數產生 Cirq 電路
def generate_circuit(qubits, n_layers):
"""Prepares a data re-uploading circuit on `qubits` with `n_layers` layers."""
# Number of qubits
n_qubits = len(qubits)
# Sympy symbols for variational angles
params = sympy.symbols(f'theta(0:{3*(n_layers+1)*n_qubits})')
params = np.asarray(params).reshape((n_layers + 1, n_qubits, 3))
# Sympy symbols for encoding angles
inputs = sympy.symbols(f'x(0:{n_layers})'+f'_(0:{n_qubits})')
inputs = np.asarray(inputs).reshape((n_layers, n_qubits))
# Define circuit
circuit = cirq.Circuit()
for l in range(n_layers):
# Variational layer
circuit += cirq.Circuit(one_qubit_rotation(q, params[l, i]) for i, q in enumerate(qubits))
circuit += entangling_layer(qubits)
# Encoding layer
circuit += cirq.Circuit(cirq.rx(inputs[l, i])(q) for i, q in enumerate(qubits))
# Last varitional layer
circuit += cirq.Circuit(one_qubit_rotation(q, params[n_layers, i]) for i,q in enumerate(qubits))
return circuit, list(params.flat), list(inputs.flat)
檢查這是否產生在變分層和編碼層之間交替的電路。
n_qubits, n_layers = 3, 1
qubits = cirq.GridQubit.rect(1, n_qubits)
circuit, _, _ = generate_circuit(qubits, n_layers)
SVGCircuit(circuit)
findfont: Font family ['Arial'] not found. Falling back to DejaVu Sans.

1.2 使用 ControlledPQC 的 ReUploadingPQC 層
若要從上圖建構重新上傳 PQC,您可以建立自訂 Keras 層。此層將管理可訓練參數 (變分角 \(\boldsymbol{\theta}\) 和輸入縮放參數 \(\boldsymbol{\lambda}\)),並將輸入值 (輸入狀態 \(s\)) 解析為電路中的適當符號。
class ReUploadingPQC(tf.keras.layers.Layer):
"""
Performs the transformation (s_1, ..., s_d) -> (theta_1, ..., theta_N, lmbd[1][1]s_1, ..., lmbd[1][M]s_1,
......., lmbd[d][1]s_d, ..., lmbd[d][M]s_d) for d=input_dim, N=theta_dim and M=n_layers.
An activation function from tf.keras.activations, specified by `activation` ('linear' by default) is
then applied to all lmbd[i][j]s_i.
All angles are finally permuted to follow the alphabetical order of their symbol names, as processed
by the ControlledPQC.
"""
def __init__(self, qubits, n_layers, observables, activation="linear", name="re-uploading_PQC"):
super(ReUploadingPQC, self).__init__(name=name)
self.n_layers = n_layers
self.n_qubits = len(qubits)
circuit, theta_symbols, input_symbols = generate_circuit(qubits, n_layers)
theta_init = tf.random_uniform_initializer(minval=0.0, maxval=np.pi)
self.theta = tf.Variable(
initial_value=theta_init(shape=(1, len(theta_symbols)), dtype="float32"),
trainable=True, name="thetas"
)
lmbd_init = tf.ones(shape=(self.n_qubits * self.n_layers,))
self.lmbd = tf.Variable(
initial_value=lmbd_init, dtype="float32", trainable=True, name="lambdas"
)
# Define explicit symbol order.
symbols = [str(symb) for symb in theta_symbols + input_symbols]
self.indices = tf.constant([symbols.index(a) for a in sorted(symbols)])
self.activation = activation
self.empty_circuit = tfq.convert_to_tensor([cirq.Circuit()])
self.computation_layer = tfq.layers.ControlledPQC(circuit, observables)
def call(self, inputs):
# inputs[0] = encoding data for the state.
batch_dim = tf.gather(tf.shape(inputs[0]), 0)
tiled_up_circuits = tf.repeat(self.empty_circuit, repeats=batch_dim)
tiled_up_thetas = tf.tile(self.theta, multiples=[batch_dim, 1])
tiled_up_inputs = tf.tile(inputs[0], multiples=[1, self.n_layers])
scaled_inputs = tf.einsum("i,ji->ji", self.lmbd, tiled_up_inputs)
squashed_inputs = tf.keras.layers.Activation(self.activation)(scaled_inputs)
joined_vars = tf.concat([tiled_up_thetas, squashed_inputs], axis=1)
joined_vars = tf.gather(joined_vars, self.indices, axis=1)
return self.computation_layer([tiled_up_circuits, joined_vars])
2. 具有 PQC 策略的策略梯度強化學習
在本節中,您將實作 [1] 中提出的策略梯度演算法。為此,您將從剛定義的 PQC 開始,建構 softmax-VQC 策略 (其中 VQC 代表變分量子電路)
\[ \pi_\theta(a|s) = \frac{e^{\beta \langle O_a \rangle_{s,\theta} } }{\sum_{a'} e^{\beta \langle O_{a'} \rangle_{s,\theta} } } \]
其中 \(\langle O_a \rangle_{s,\theta}\) 是在 PQC 輸出端測量的可觀測值 \(O_a\) (每個動作一個) 的期望值,而 \(\beta\) 是可調整的反向溫度參數。
您可以採用 [1] 中用於 CartPole 的相同可觀測值,即作用於所有量子位元的全域 \(Z_0Z_1Z_2Z_3\) Pauli 乘積,每個動作都以動作特定的權重加權。若要實作 Pauli 乘積的加權,您可以使用額外的 tf.keras.layers.Layer,其會儲存動作特定的權重,並將其乘法應用於期望值 \(\langle Z_0Z_1Z_2Z_3 \rangle_{s,\theta}\)。
class Alternating(tf.keras.layers.Layer):
def __init__(self, output_dim):
super(Alternating, self).__init__()
self.w = tf.Variable(
initial_value=tf.constant([[(-1.)**i for i in range(output_dim)]]), dtype="float32",
trainable=True, name="obs-weights")
def call(self, inputs):
return tf.matmul(inputs, self.w)
準備 PQC 的定義
n_qubits = 4 # Dimension of the state vectors in CartPole
n_layers = 5 # Number of layers in the PQC
n_actions = 2 # Number of actions in CartPole
qubits = cirq.GridQubit.rect(1, n_qubits)
及其可觀測值
ops = [cirq.Z(q) for q in qubits]
observables = [reduce((lambda x, y: x * y), ops)] # Z_0*Z_1*Z_2*Z_3
有了這個,定義一個 tf.keras.Model,它會依序應用先前定義的 ReUploadingPQC 層,然後是一個後處理層,該層使用 Alternating 計算加權可觀測值,然後將其饋送到 tf.keras.layers.Softmax 層,該層輸出代理程式的 softmax-VQC 策略。
def generate_model_policy(qubits, n_layers, n_actions, beta, observables):
"""Generates a Keras model for a data re-uploading PQC policy."""
input_tensor = tf.keras.Input(shape=(len(qubits), ), dtype=tf.dtypes.float32, name='input')
re_uploading_pqc = ReUploadingPQC(qubits, n_layers, observables)([input_tensor])
process = tf.keras.Sequential([
Alternating(n_actions),
tf.keras.layers.Lambda(lambda x: x * beta),
tf.keras.layers.Softmax()
], name="observables-policy")
policy = process(re_uploading_pqc)
model = tf.keras.Model(inputs=[input_tensor], outputs=policy)
return model
model = generate_model_policy(qubits, n_layers, n_actions, 1.0, observables)
tf.keras.utils.plot_model(model, show_shapes=True, dpi=70)
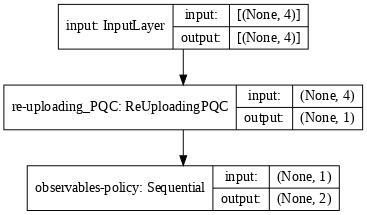
您現在可以使用基本 REINFORCE 演算法 (請參閱 [1] 中的演算法 1),在 CartPole-v1 上訓練 PQC 策略。請注意以下幾點
- 由於縮放參數、變分角和可觀測權重是以不同的學習率訓練的,因此方便定義 3 個具有各自學習率的獨立最佳化工具,每個最佳化工具更新其中一組參數。
策略梯度強化學習中的損失函數為
\[ \mathcal{L}(\theta) = -\frac{1}{|\mathcal{B}|}\sum_{s_0,a_0,r_1,s_1,a_1, \ldots \in \mathcal{B} } \left(\sum_{t=0}^{H-1} \log(\pi_\theta(a_t|s_t)) \sum_{t'=1}^{H-t} \gamma^{t'} r_{t+t'} \right)\]
對於在環境中遵循策略 \(\pi_\theta\) 的互動劇集 \((s_0,a_0,r_1,s_1,a_1, \ldots)\) 的批次 \(\mathcal{B}\)。這與模型應擬合的具有固定目標值的監督式學習損失不同,這使得無法使用類似 model.fit 的簡單函數呼叫來訓練策略。相反地,使用 tf.GradientTape 可以追蹤涉及 PQC (即策略取樣) 的計算,並在互動期間儲存其對損失的貢獻。在執行一批劇集後,您可以對這些計算應用反向傳播,以獲得損失相對於 PQC 參數的梯度,並使用最佳化工具更新策略模型。
首先定義一個收集與環境互動劇集的函數
def gather_episodes(state_bounds, n_actions, model, n_episodes, env_name):
"""Interact with environment in batched fashion."""
trajectories = [defaultdict(list) for _ in range(n_episodes)]
envs = [gym.make(env_name) for _ in range(n_episodes)]
done = [False for _ in range(n_episodes)]
states = [e.reset() for e in envs]
while not all(done):
unfinished_ids = [i for i in range(n_episodes) if not done[i]]
normalized_states = [s/state_bounds for i, s in enumerate(states) if not done[i]]
for i, state in zip(unfinished_ids, normalized_states):
trajectories[i]['states'].append(state)
# Compute policy for all unfinished envs in parallel
states = tf.convert_to_tensor(normalized_states)
action_probs = model([states])
# Store action and transition all environments to the next state
states = [None for i in range(n_episodes)]
for i, policy in zip(unfinished_ids, action_probs.numpy()):
action = np.random.choice(n_actions, p=policy)
states[i], reward, done[i], _ = envs[i].step(action)
trajectories[i]['actions'].append(action)
trajectories[i]['rewards'].append(reward)
return trajectories
以及一個計算劇集中收集的回報 \(r_t\) 的折現回報 \(\sum_{t'=1}^{H-t} \gamma^{t'} r_{t+t'}\) 的函數
def compute_returns(rewards_history, gamma):
"""Compute discounted returns with discount factor `gamma`."""
returns = []
discounted_sum = 0
for r in rewards_history[::-1]:
discounted_sum = r + gamma * discounted_sum
returns.insert(0, discounted_sum)
# Normalize them for faster and more stable learning
returns = np.array(returns)
returns = (returns - np.mean(returns)) / (np.std(returns) + 1e-8)
returns = returns.tolist()
return returns
定義超參數
state_bounds = np.array([2.4, 2.5, 0.21, 2.5])
gamma = 1
batch_size = 10
n_episodes = 1000
準備最佳化工具
optimizer_in = tf.keras.optimizers.Adam(learning_rate=0.1, amsgrad=True)
optimizer_var = tf.keras.optimizers.Adam(learning_rate=0.01, amsgrad=True)
optimizer_out = tf.keras.optimizers.Adam(learning_rate=0.1, amsgrad=True)
# Assign the model parameters to each optimizer
w_in, w_var, w_out = 1, 0, 2
實作一個使用狀態、動作和回報更新策略的函數
@tf.function
def reinforce_update(states, actions, returns, model):
states = tf.convert_to_tensor(states)
actions = tf.convert_to_tensor(actions)
returns = tf.convert_to_tensor(returns)
with tf.GradientTape() as tape:
tape.watch(model.trainable_variables)
logits = model(states)
p_actions = tf.gather_nd(logits, actions)
log_probs = tf.math.log(p_actions)
loss = tf.math.reduce_sum(-log_probs * returns) / batch_size
grads = tape.gradient(loss, model.trainable_variables)
for optimizer, w in zip([optimizer_in, optimizer_var, optimizer_out], [w_in, w_var, w_out]):
optimizer.apply_gradients([(grads[w], model.trainable_variables[w])])
現在實作代理程式的主要訓練迴圈。
env_name = "CartPole-v1"
# Start training the agent
episode_reward_history = []
for batch in range(n_episodes // batch_size):
# Gather episodes
episodes = gather_episodes(state_bounds, n_actions, model, batch_size, env_name)
# Group states, actions and returns in numpy arrays
states = np.concatenate([ep['states'] for ep in episodes])
actions = np.concatenate([ep['actions'] for ep in episodes])
rewards = [ep['rewards'] for ep in episodes]
returns = np.concatenate([compute_returns(ep_rwds, gamma) for ep_rwds in rewards])
returns = np.array(returns, dtype=np.float32)
id_action_pairs = np.array([[i, a] for i, a in enumerate(actions)])
# Update model parameters.
reinforce_update(states, id_action_pairs, returns, model)
# Store collected rewards
for ep_rwds in rewards:
episode_reward_history.append(np.sum(ep_rwds))
avg_rewards = np.mean(episode_reward_history[-10:])
print('Finished episode', (batch + 1) * batch_size,
'Average rewards: ', avg_rewards)
if avg_rewards >= 500.0:
break
Finished episode 10 Average rewards: 22.3 Finished episode 20 Average rewards: 27.4 Finished episode 30 Average rewards: 24.7 Finished episode 40 Average rewards: 21.2 Finished episode 50 Average rewards: 33.9 Finished episode 60 Average rewards: 31.3 Finished episode 70 Average rewards: 37.3 Finished episode 80 Average rewards: 34.4 Finished episode 90 Average rewards: 58.4 Finished episode 100 Average rewards: 33.2 Finished episode 110 Average rewards: 67.9 Finished episode 120 Average rewards: 63.9 Finished episode 130 Average rewards: 83.5 Finished episode 140 Average rewards: 88.0 Finished episode 150 Average rewards: 142.9 Finished episode 160 Average rewards: 204.7 Finished episode 170 Average rewards: 138.1 Finished episode 180 Average rewards: 183.0 Finished episode 190 Average rewards: 196.0 Finished episode 200 Average rewards: 302.0 Finished episode 210 Average rewards: 374.4 Finished episode 220 Average rewards: 329.1 Finished episode 230 Average rewards: 307.8 Finished episode 240 Average rewards: 359.6 Finished episode 250 Average rewards: 400.7 Finished episode 260 Average rewards: 414.4 Finished episode 270 Average rewards: 394.9 Finished episode 280 Average rewards: 470.7 Finished episode 290 Average rewards: 459.7 Finished episode 300 Average rewards: 428.7 Finished episode 310 Average rewards: 500.0
繪製代理程式的學習歷程記錄
plt.figure(figsize=(10,5))
plt.plot(episode_reward_history)
plt.xlabel('Epsiode')
plt.ylabel('Collected rewards')
plt.show()
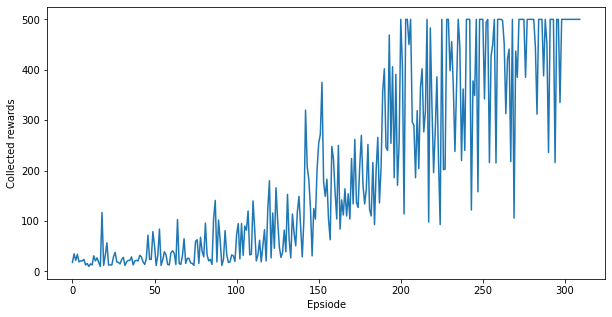
恭喜,您已在 Cartpole 上訓練了量子策略梯度模型!上圖顯示代理程式在與環境互動期間每個劇集收集的回報。您應該會看到,在數百個劇集後,代理程式的效能接近最佳,即每個劇集 500 個回報。
您現在可以使用範例劇集中的 env.render() 可視化代理程式的效能 (僅當您的筆記本可以存取顯示器時,才取消註解/執行以下儲存格)
# from PIL import Image
# env = gym.make('CartPole-v1')
# state = env.reset()
# frames = []
# for t in range(500):
# im = Image.fromarray(env.render(mode='rgb_array'))
# frames.append(im)
# policy = model([tf.convert_to_tensor([state/state_bounds])])
# action = np.random.choice(n_actions, p=policy.numpy()[0])
# state, _, done, _ = env.step(action)
# if done:
# break
# env.close()
# frames[1].save('./images/gym_CartPole.gif',
# save_all=True, append_images=frames[2:], optimize=False, duration=40, loop=0)
3. 具有 PQC Q 函數近似器的深度 Q 學習
在本節中,您將轉向實作 [2] 中提出的深度 Q 學習演算法。與策略梯度方法相反,深度 Q 學習方法使用 PQC 來近似代理程式的 Q 函數。也就是說,PQC 定義了一個函數近似器
\[ Q_\theta(s,a) = \langle O_a \rangle_{s,\theta} \]
其中 \(\langle O_a \rangle_{s,\theta}\) 是在 PQC 輸出端測量的可觀測值 \(O_a\) (每個動作一個) 的期望值。
這些 Q 值使用從 Q 學習衍生的損失函數更新
\[ \mathcal{L}(\theta) = \frac{1}{|\mathcal{B}|}\sum_{s,a,r,s' \in \mathcal{B} } \left(Q_\theta(s,a) - [r +\max_{a'} Q_{\theta'}(s',a')]\right)^2\]
對於從重播記憶體取樣的與環境的 \(1\) 步互動 \((s,a,r,s')\) 的批次 \(\mathcal{B}\),以及指定目標 PQC 的參數 \(\theta'\) (即主 PQC 的副本,其參數在整個學習過程中偶爾從主 PQC 複製)。
您可以採用 [2] 中用於 CartPole 的相同可觀測值,即動作 \(0\) 的 \(Z_0Z_1\) Pauli 乘積和動作 \(1\) 的 \(Z_2Z_3\) Pauli 乘積。這兩個可觀測值都會重新縮放,使其期望值在 \([0,1]\) 中,並以動作特定的權重加權。若要實作 Pauli 乘積的重新縮放和加權,您可以再次定義一個額外的 tf.keras.layers.Layer,其會儲存動作特定的權重,並將其乘法應用於期望值 \(\left(1+\langle Z_0Z_1 \rangle_{s,\theta}\right)/2\) 和 \(\left(1+\langle Z_2Z_3 \rangle_{s,\theta}\right)/2\)。
class Rescaling(tf.keras.layers.Layer):
def __init__(self, input_dim):
super(Rescaling, self).__init__()
self.input_dim = input_dim
self.w = tf.Variable(
initial_value=tf.ones(shape=(1,input_dim)), dtype="float32",
trainable=True, name="obs-weights")
def call(self, inputs):
return tf.math.multiply((inputs+1)/2, tf.repeat(self.w,repeats=tf.shape(inputs)[0],axis=0))
準備 PQC 及其可觀測值的定義
n_qubits = 4 # Dimension of the state vectors in CartPole
n_layers = 5 # Number of layers in the PQC
n_actions = 2 # Number of actions in CartPole
qubits = cirq.GridQubit.rect(1, n_qubits)
ops = [cirq.Z(q) for q in qubits]
observables = [ops[0]*ops[1], ops[2]*ops[3]] # Z_0*Z_1 for action 0 and Z_2*Z_3 for action 1
定義一個 tf.keras.Model,與 PQC 策略模型類似,它會建構一個 Q 函數近似器,用於產生 Q 學習代理程式的主要和目標模型。
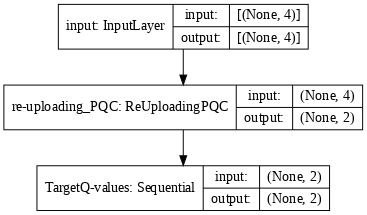
def generate_model_Qlearning(qubits, n_layers, n_actions, observables, target):
"""Generates a Keras model for a data re-uploading PQC Q-function approximator."""
input_tensor = tf.keras.Input(shape=(len(qubits), ), dtype=tf.dtypes.float32, name='input')
re_uploading_pqc = ReUploadingPQC(qubits, n_layers, observables, activation='tanh')([input_tensor])
process = tf.keras.Sequential([Rescaling(len(observables))], name=target*"Target"+"Q-values")
Q_values = process(re_uploading_pqc)
model = tf.keras.Model(inputs=[input_tensor], outputs=Q_values)
return model
model = generate_model_Qlearning(qubits, n_layers, n_actions, observables, False)
model_target = generate_model_Qlearning(qubits, n_layers, n_actions, observables, True)
model_target.set_weights(model.get_weights())
tf.keras.utils.plot_model(model, show_shapes=True, dpi=70)
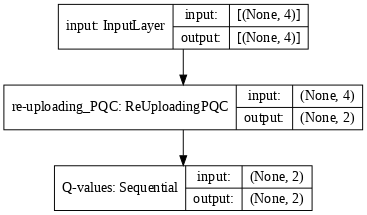
tf.keras.utils.plot_model(model_target, show_shapes=True, dpi=70)
您現在可以實作深度 Q 學習演算法,並在 CartPole-v1 環境中進行測試。對於代理程式的策略,您可以使用 \(\varepsilon\)-貪婪策略
\[ \pi(a|s) = \begin{cases} \delta_{a,\text{argmax}_{a'} Q_\theta(s,a')}\quad \text{w.p.}\quad 1 - \varepsilon\\ \frac{1}{\text{num_actions} }\quad \quad \quad \quad \text{w.p.}\quad \varepsilon \end{cases} \]
其中 \(\varepsilon\) 在每次互動劇集中以乘法方式衰減。
首先定義一個在環境中執行互動步驟的函數
def interact_env(state, model, epsilon, n_actions, env):
# Preprocess state
state_array = np.array(state)
state = tf.convert_to_tensor([state_array])
# Sample action
coin = np.random.random()
if coin > epsilon:
q_vals = model([state])
action = int(tf.argmax(q_vals[0]).numpy())
else:
action = np.random.choice(n_actions)
# Apply sampled action in the environment, receive reward and next state
next_state, reward, done, _ = env.step(action)
interaction = {'state': state_array, 'action': action, 'next_state': next_state.copy(),
'reward': reward, 'done':np.float32(done)}
return interaction
以及一個使用一批互動更新 Q 函數的函數
@tf.function
def Q_learning_update(states, actions, rewards, next_states, done, model, gamma, n_actions):
states = tf.convert_to_tensor(states)
actions = tf.convert_to_tensor(actions)
rewards = tf.convert_to_tensor(rewards)
next_states = tf.convert_to_tensor(next_states)
done = tf.convert_to_tensor(done)
# Compute their target q_values and the masks on sampled actions
future_rewards = model_target([next_states])
target_q_values = rewards + (gamma * tf.reduce_max(future_rewards, axis=1)
* (1.0 - done))
masks = tf.one_hot(actions, n_actions)
# Train the model on the states and target Q-values
with tf.GradientTape() as tape:
tape.watch(model.trainable_variables)
q_values = model([states])
q_values_masked = tf.reduce_sum(tf.multiply(q_values, masks), axis=1)
loss = tf.keras.losses.Huber()(target_q_values, q_values_masked)
# Backpropagation
grads = tape.gradient(loss, model.trainable_variables)
for optimizer, w in zip([optimizer_in, optimizer_var, optimizer_out], [w_in, w_var, w_out]):
optimizer.apply_gradients([(grads[w], model.trainable_variables[w])])
定義超參數
gamma = 0.99
n_episodes = 2000
# Define replay memory
max_memory_length = 10000 # Maximum replay length
replay_memory = deque(maxlen=max_memory_length)
epsilon = 1.0 # Epsilon greedy parameter
epsilon_min = 0.01 # Minimum epsilon greedy parameter
decay_epsilon = 0.99 # Decay rate of epsilon greedy parameter
batch_size = 16
steps_per_update = 10 # Train the model every x steps
steps_per_target_update = 30 # Update the target model every x steps
準備最佳化工具
optimizer_in = tf.keras.optimizers.Adam(learning_rate=0.001, amsgrad=True)
optimizer_var = tf.keras.optimizers.Adam(learning_rate=0.001, amsgrad=True)
optimizer_out = tf.keras.optimizers.Adam(learning_rate=0.1, amsgrad=True)
# Assign the model parameters to each optimizer
w_in, w_var, w_out = 1, 0, 2
現在實作代理程式的主要訓練迴圈。
env = gym.make("CartPole-v1")
episode_reward_history = []
step_count = 0
for episode in range(n_episodes):
episode_reward = 0
state = env.reset()
while True:
# Interact with env
interaction = interact_env(state, model, epsilon, n_actions, env)
# Store interaction in the replay memory
replay_memory.append(interaction)
state = interaction['next_state']
episode_reward += interaction['reward']
step_count += 1
# Update model
if step_count % steps_per_update == 0:
# Sample a batch of interactions and update Q_function
training_batch = np.random.choice(replay_memory, size=batch_size)
Q_learning_update(np.asarray([x['state'] for x in training_batch]),
np.asarray([x['action'] for x in training_batch]),
np.asarray([x['reward'] for x in training_batch], dtype=np.float32),
np.asarray([x['next_state'] for x in training_batch]),
np.asarray([x['done'] for x in training_batch], dtype=np.float32),
model, gamma, n_actions)
# Update target model
if step_count % steps_per_target_update == 0:
model_target.set_weights(model.get_weights())
# Check if the episode is finished
if interaction['done']:
break
# Decay epsilon
epsilon = max(epsilon * decay_epsilon, epsilon_min)
episode_reward_history.append(episode_reward)
if (episode+1)%10 == 0:
avg_rewards = np.mean(episode_reward_history[-10:])
print("Episode {}/{}, average last 10 rewards {}".format(
episode+1, n_episodes, avg_rewards))
if avg_rewards >= 500.0:
break
Episode 10/2000, average last 10 rewards 22.1 Episode 20/2000, average last 10 rewards 27.9 Episode 30/2000, average last 10 rewards 31.5 Episode 40/2000, average last 10 rewards 23.3 Episode 50/2000, average last 10 rewards 25.4 Episode 60/2000, average last 10 rewards 19.7 Episode 70/2000, average last 10 rewards 12.5 Episode 80/2000, average last 10 rewards 11.7 Episode 90/2000, average last 10 rewards 14.9 Episode 100/2000, average last 10 rewards 15.3 Episode 110/2000, average last 10 rewards 14.6 Episode 120/2000, average last 10 rewards 20.4 Episode 130/2000, average last 10 rewards 14.2 Episode 140/2000, average last 10 rewards 21.6 Episode 150/2000, average last 10 rewards 30.4 Episode 160/2000, average last 10 rewards 27.6 Episode 170/2000, average last 10 rewards 18.5 Episode 180/2000, average last 10 rewards 30.6 Episode 190/2000, average last 10 rewards 12.2 Episode 200/2000, average last 10 rewards 27.2 Episode 210/2000, average last 10 rewards 27.2 Episode 220/2000, average last 10 rewards 15.3 Episode 230/2000, average last 10 rewards 128.4 Episode 240/2000, average last 10 rewards 68.3 Episode 250/2000, average last 10 rewards 44.0 Episode 260/2000, average last 10 rewards 119.8 Episode 270/2000, average last 10 rewards 135.3 Episode 280/2000, average last 10 rewards 90.6 Episode 290/2000, average last 10 rewards 120.9 Episode 300/2000, average last 10 rewards 125.3 Episode 310/2000, average last 10 rewards 141.7 Episode 320/2000, average last 10 rewards 144.7 Episode 330/2000, average last 10 rewards 165.7 Episode 340/2000, average last 10 rewards 26.1 Episode 350/2000, average last 10 rewards 9.7 Episode 360/2000, average last 10 rewards 9.6 Episode 370/2000, average last 10 rewards 9.7 Episode 380/2000, average last 10 rewards 9.4 Episode 390/2000, average last 10 rewards 11.3 Episode 400/2000, average last 10 rewards 11.6 Episode 410/2000, average last 10 rewards 165.4 Episode 420/2000, average last 10 rewards 170.5 Episode 430/2000, average last 10 rewards 25.1 Episode 440/2000, average last 10 rewards 74.1 Episode 450/2000, average last 10 rewards 214.7 Episode 460/2000, average last 10 rewards 139.1 Episode 470/2000, average last 10 rewards 265.1 Episode 480/2000, average last 10 rewards 296.7 Episode 490/2000, average last 10 rewards 101.7 Episode 500/2000, average last 10 rewards 146.6 Episode 510/2000, average last 10 rewards 325.6 Episode 520/2000, average last 10 rewards 45.9 Episode 530/2000, average last 10 rewards 263.5 Episode 540/2000, average last 10 rewards 223.3 Episode 550/2000, average last 10 rewards 73.1 Episode 560/2000, average last 10 rewards 115.0 Episode 570/2000, average last 10 rewards 148.3 Episode 580/2000, average last 10 rewards 41.6 Episode 590/2000, average last 10 rewards 266.7 Episode 600/2000, average last 10 rewards 275.2 Episode 610/2000, average last 10 rewards 253.9 Episode 620/2000, average last 10 rewards 282.2 Episode 630/2000, average last 10 rewards 348.3 Episode 640/2000, average last 10 rewards 162.2 Episode 650/2000, average last 10 rewards 276.0 Episode 660/2000, average last 10 rewards 234.6 Episode 670/2000, average last 10 rewards 187.4 Episode 680/2000, average last 10 rewards 285.0 Episode 690/2000, average last 10 rewards 362.8 Episode 700/2000, average last 10 rewards 316.0 Episode 710/2000, average last 10 rewards 436.0 Episode 720/2000, average last 10 rewards 366.1 Episode 730/2000, average last 10 rewards 305.0 Episode 740/2000, average last 10 rewards 273.2 Episode 750/2000, average last 10 rewards 236.8 Episode 760/2000, average last 10 rewards 260.2 Episode 770/2000, average last 10 rewards 443.9 Episode 780/2000, average last 10 rewards 494.2 Episode 790/2000, average last 10 rewards 333.1 Episode 800/2000, average last 10 rewards 367.1 Episode 810/2000, average last 10 rewards 317.8 Episode 820/2000, average last 10 rewards 396.6 Episode 830/2000, average last 10 rewards 494.1 Episode 840/2000, average last 10 rewards 500.0
繪製代理程式的學習歷程記錄
plt.figure(figsize=(10,5))
plt.plot(episode_reward_history)
plt.xlabel('Epsiode')
plt.ylabel('Collected rewards')
plt.show()
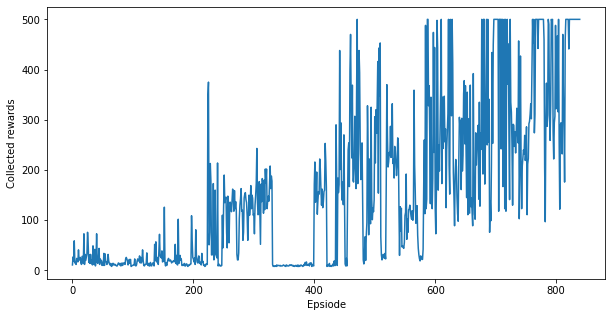
與上圖類似,您應該會看到,在大約 1000 個劇集後,代理程式的效能接近最佳,即每個劇集 500 個回報。對於 Q 學習代理程式來說,學習時間更長,因為 Q 函數是一個比策略「更豐富」的函數。
4. 練習
現在您已經訓練了兩種不同類型的模型,請嘗試使用不同的環境 (以及不同數量的量子位元和層) 進行實驗。您也可以嘗試將最後兩節的 PQC 模型組合到 演員評論家代理程式 中。