
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
以上述 MNIST 教學課程中的比較為基礎,本教學課程將探討 Huang et al. 近期的研究,該研究說明不同資料集如何影響效能比較。在該研究中,作者試圖瞭解傳統機器學習模型如何在效能上與量子模型並駕齊驅 (甚至更勝一籌) 以及何時能做到。該研究也透過精心設計的資料集,展現傳統機器學習模型和量子機器學習模型之間實證效能上的差異。您將:
- 準備縮減維度的 Fashion-MNIST 資料集。
- 使用量子電路重新標記資料集,並計算投影量子核心特徵 (PQK)。
- 在重新標記的資料集上訓練傳統神經網路,並將其效能與可存取 PQK 特徵的模型進行比較。
設定
pip install tensorflow==2.15.0 tensorflow-quantum==0.7.3
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
import cirq
import sympy
import numpy as np
import tensorflow as tf
import tensorflow_quantum as tfq
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
1. 資料準備
您將從準備 Fashion-MNIST 資料集開始,以便在量子電腦上執行。
1.1 下載 Fashion-MNIST
第一步是取得傳統的 Fashion-MNIST 資料集。這可以使用 tf.keras.datasets 模組完成。
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# Rescale the images from [0,255] to the [0.0,1.0] range.
x_train, x_test = x_train/255.0, x_test/255.0
print("Number of original training examples:", len(x_train))
print("Number of original test examples:", len(x_test))
Number of original training examples: 60000 Number of original test examples: 10000
篩選資料集,僅保留 T 恤/上衣和洋裝,移除其他類別。同時將標籤 y 轉換為布林值:True 代表 0,False 代表 3。
def filter_03(x, y):
keep = (y == 0) | (y == 3)
x, y = x[keep], y[keep]
y = y == 0
return x,y
x_train, y_train = filter_03(x_train, y_train)
x_test, y_test = filter_03(x_test, y_test)
print("Number of filtered training examples:", len(x_train))
print("Number of filtered test examples:", len(x_test))
Number of filtered training examples: 12000 Number of filtered test examples: 2000
print(y_train[0])
plt.imshow(x_train[0, :, :])
plt.colorbar()
True <matplotlib.colorbar.Colorbar at 0x7f6db42c3460>

1.2 縮小圖片尺寸
就像 MNIST 範例一樣,您需要縮小這些圖片的尺寸,使其符合當前量子電腦的邊界。不過,這次您將使用 PCA 轉換來縮減維度,而不是 tf.image.resize 運算。
def truncate_x(x_train, x_test, n_components=10):
"""Perform PCA on image dataset keeping the top `n_components` components."""
n_points_train = tf.gather(tf.shape(x_train), 0)
n_points_test = tf.gather(tf.shape(x_test), 0)
# Flatten to 1D
x_train = tf.reshape(x_train, [n_points_train, -1])
x_test = tf.reshape(x_test, [n_points_test, -1])
# Normalize.
feature_mean = tf.reduce_mean(x_train, axis=0)
x_train_normalized = x_train - feature_mean
x_test_normalized = x_test - feature_mean
# Truncate.
e_values, e_vectors = tf.linalg.eigh(
tf.einsum('ji,jk->ik', x_train_normalized, x_train_normalized))
return tf.einsum('ij,jk->ik', x_train_normalized, e_vectors[:,-n_components:]), \
tf.einsum('ij,jk->ik', x_test_normalized, e_vectors[:, -n_components:])
DATASET_DIM = 10
x_train, x_test = truncate_x(x_train, x_test, n_components=DATASET_DIM)
print(f'New datapoint dimension:', len(x_train[0]))
New datapoint dimension: 10
最後一步是將資料集的大小縮減為僅 1000 個訓練資料點和 200 個測試資料點。
N_TRAIN = 1000
N_TEST = 200
x_train, x_test = x_train[:N_TRAIN], x_test[:N_TEST]
y_train, y_test = y_train[:N_TRAIN], y_test[:N_TEST]
print("New number of training examples:", len(x_train))
print("New number of test examples:", len(x_test))
New number of training examples: 1000 New number of test examples: 200
2. 重新標記並計算 PQK 特徵
您現在將透過納入量子元件並重新標記您在上面建立的截斷 Fashion-MNIST 資料集,來準備「矯揉造作」的量子資料集。為了在量子方法和傳統方法之間獲得最大的差異,您將首先準備 PQK 特徵,然後根據其值重新標記輸出。
2.1 量子編碼與 PQK 特徵
您將建立一組新的特徵,這些特徵基於 x_train、y_train、x_test 和 y_test,定義為
\(V(x_{\text{train} } / n_{\text{trotter} }) ^ {n_{\text{trotter} } } U_{\text{1qb} } | 0 \rangle\)
所有量子位元上的 1-RDM,其中 \(U_\text{1qb}\) 是單一量子位元旋轉牆,而 \(V(\hat{\theta}) = e^{-i\sum_i \hat{\theta_i} (X_i X_{i+1} + Y_i Y_{i+1} + Z_i Z_{i+1})}\)
首先,您可以產生單一量子位元旋轉牆
def single_qubit_wall(qubits, rotations):
"""Prepare a single qubit X,Y,Z rotation wall on `qubits`."""
wall_circuit = cirq.Circuit()
for i, qubit in enumerate(qubits):
for j, gate in enumerate([cirq.X, cirq.Y, cirq.Z]):
wall_circuit.append(gate(qubit) ** rotations[i][j])
return wall_circuit
您可以快速查看電路來驗證這是否有效
SVGCircuit(single_qubit_wall(
cirq.GridQubit.rect(1,4), np.random.uniform(size=(4, 3))))

接下來,您可以在 tfq.util.exponential 的協助下準備 \(V(\hat{\theta})\),它可以將任何可交換的 cirq.PauliSum 物件指數化
def v_theta(qubits):
"""Prepares a circuit that generates V(\theta)."""
ref_paulis = [
cirq.X(q0) * cirq.X(q1) + \
cirq.Y(q0) * cirq.Y(q1) + \
cirq.Z(q0) * cirq.Z(q1) for q0, q1 in zip(qubits, qubits[1:])
]
exp_symbols = list(sympy.symbols('ref_0:'+str(len(ref_paulis))))
return tfq.util.exponential(ref_paulis, exp_symbols), exp_symbols
這個電路可能有點難以透過查看來驗證,但您仍然可以檢查雙量子位元案例,看看發生了什麼事
test_circuit, test_symbols = v_theta(cirq.GridQubit.rect(1, 2))
print(f'Symbols found in circuit:{test_symbols}')
SVGCircuit(test_circuit)
Symbols found in circuit:[ref_0]

現在您已具備將完整編碼電路組合在一起所需的所有建構區塊
def prepare_pqk_circuits(qubits, classical_source, n_trotter=10):
"""Prepare the pqk feature circuits around a dataset."""
n_qubits = len(qubits)
n_points = len(classical_source)
# Prepare random single qubit rotation wall.
random_rots = np.random.uniform(-2, 2, size=(n_qubits, 3))
initial_U = single_qubit_wall(qubits, random_rots)
# Prepare parametrized V
V_circuit, symbols = v_theta(qubits)
exp_circuit = cirq.Circuit(V_circuit for t in range(n_trotter))
# Convert to `tf.Tensor`
initial_U_tensor = tfq.convert_to_tensor([initial_U])
initial_U_splat = tf.tile(initial_U_tensor, [n_points])
full_circuits = tfq.layers.AddCircuit()(
initial_U_splat, append=exp_circuit)
# Replace placeholders in circuits with values from `classical_source`.
return tfq.resolve_parameters(
full_circuits, tf.convert_to_tensor([str(x) for x in symbols]),
tf.convert_to_tensor(classical_source*(n_qubits/3)/n_trotter))
選擇一些量子位元並準備資料編碼電路
qubits = cirq.GridQubit.rect(1, DATASET_DIM + 1)
q_x_train_circuits = prepare_pqk_circuits(qubits, x_train)
q_x_test_circuits = prepare_pqk_circuits(qubits, x_test)
接下來,根據上述資料集電路的 1-RDM 計算 PQK 特徵,並將結果儲存在 rdm 中,這是一個形狀為 [n_points, n_qubits, 3] 的 tf.Tensor。rdm[i][j][k] 中的項目 = \(\langle \psi_i | OP^k_j | \psi_i \rangle\),其中 i 索引資料點,j 索引量子位元,k 索引 \(\lbrace \hat{X}, \hat{Y}, \hat{Z} \rbrace\)。
def get_pqk_features(qubits, data_batch):
"""Get PQK features based on above construction."""
ops = [[cirq.X(q), cirq.Y(q), cirq.Z(q)] for q in qubits]
ops_tensor = tf.expand_dims(tf.reshape(tfq.convert_to_tensor(ops), -1), 0)
batch_dim = tf.gather(tf.shape(data_batch), 0)
ops_splat = tf.tile(ops_tensor, [batch_dim, 1])
exp_vals = tfq.layers.Expectation()(data_batch, operators=ops_splat)
rdm = tf.reshape(exp_vals, [batch_dim, len(qubits), -1])
return rdm
x_train_pqk = get_pqk_features(qubits, q_x_train_circuits)
x_test_pqk = get_pqk_features(qubits, q_x_test_circuits)
print('New PQK training dataset has shape:', x_train_pqk.shape)
print('New PQK testing dataset has shape:', x_test_pqk.shape)
New PQK training dataset has shape: (1000, 11, 3) New PQK testing dataset has shape: (200, 11, 3)
2.2 根據 PQK 特徵重新標記
現在您已在 x_train_pqk 和 x_test_pqk 中取得這些量子產生的特徵,現在可以重新標記資料集了。為了在量子效能和傳統效能之間實現最大差異,您可以根據 x_train_pqk 和 x_test_pqk 中找到的頻譜資訊重新標記資料集。
def compute_kernel_matrix(vecs, gamma):
"""Computes d[i][j] = e^ -gamma * (vecs[i] - vecs[j]) ** 2 """
scaled_gamma = gamma / (
tf.cast(tf.gather(tf.shape(vecs), 1), tf.float32) * tf.math.reduce_std(vecs))
return scaled_gamma * tf.einsum('ijk->ij',(vecs[:,None,:] - vecs) ** 2)
def get_spectrum(datapoints, gamma=1.0):
"""Compute the eigenvalues and eigenvectors of the kernel of datapoints."""
KC_qs = compute_kernel_matrix(datapoints, gamma)
S, V = tf.linalg.eigh(KC_qs)
S = tf.math.abs(S)
return S, V
S_pqk, V_pqk = get_spectrum(
tf.reshape(tf.concat([x_train_pqk, x_test_pqk], 0), [-1, len(qubits) * 3]))
S_original, V_original = get_spectrum(
tf.cast(tf.concat([x_train, x_test], 0), tf.float32), gamma=0.005)
print('Eigenvectors of pqk kernel matrix:', V_pqk)
print('Eigenvectors of original kernel matrix:', V_original)
Eigenvectors of pqk kernel matrix: tf.Tensor( [[-2.09569391e-02 1.05973557e-02 2.16634180e-02 ... 2.80352887e-02 1.55521873e-02 2.82677952e-02] [-2.29303762e-02 4.66355234e-02 7.91163836e-03 ... -6.14174758e-04 -7.07804322e-01 2.85902526e-02] [-1.77853629e-02 -3.00758495e-03 -2.55225878e-02 ... -2.40783971e-02 2.11018627e-03 2.69009806e-02] ... [ 6.05797209e-02 1.32483775e-02 2.69536003e-02 ... -1.38843581e-02 3.05043962e-02 3.85345481e-02] [ 6.33309558e-02 -3.04112374e-03 9.77444276e-03 ... 7.48321265e-02 3.42793856e-03 3.67484428e-02] [ 5.86028099e-02 5.84433973e-03 2.64811981e-03 ... 2.82612257e-02 -3.80136147e-02 3.29943895e-02]], shape=(1200, 1200), dtype=float32) Eigenvectors of original kernel matrix: tf.Tensor( [[ 0.03835681 0.0283473 -0.01169789 ... 0.02343717 0.0211248 0.03206972] [-0.04018159 0.00888097 -0.01388255 ... 0.00582427 0.717551 0.02881948] [-0.0166719 0.01350376 -0.03663862 ... 0.02467175 -0.00415936 0.02195409] ... [-0.03015648 -0.01671632 -0.01603392 ... 0.00100583 -0.00261221 0.02365689] [ 0.0039777 -0.04998879 -0.00528336 ... 0.01560401 -0.04330755 0.02782002] [-0.01665728 -0.00818616 -0.0432341 ... 0.00088256 0.00927396 0.01875088]], shape=(1200, 1200), dtype=float32)
現在您已具備重新標記資料集所需的一切!現在您可以參考流程圖,以更瞭解如何在重新標記資料集時最大化效能差異
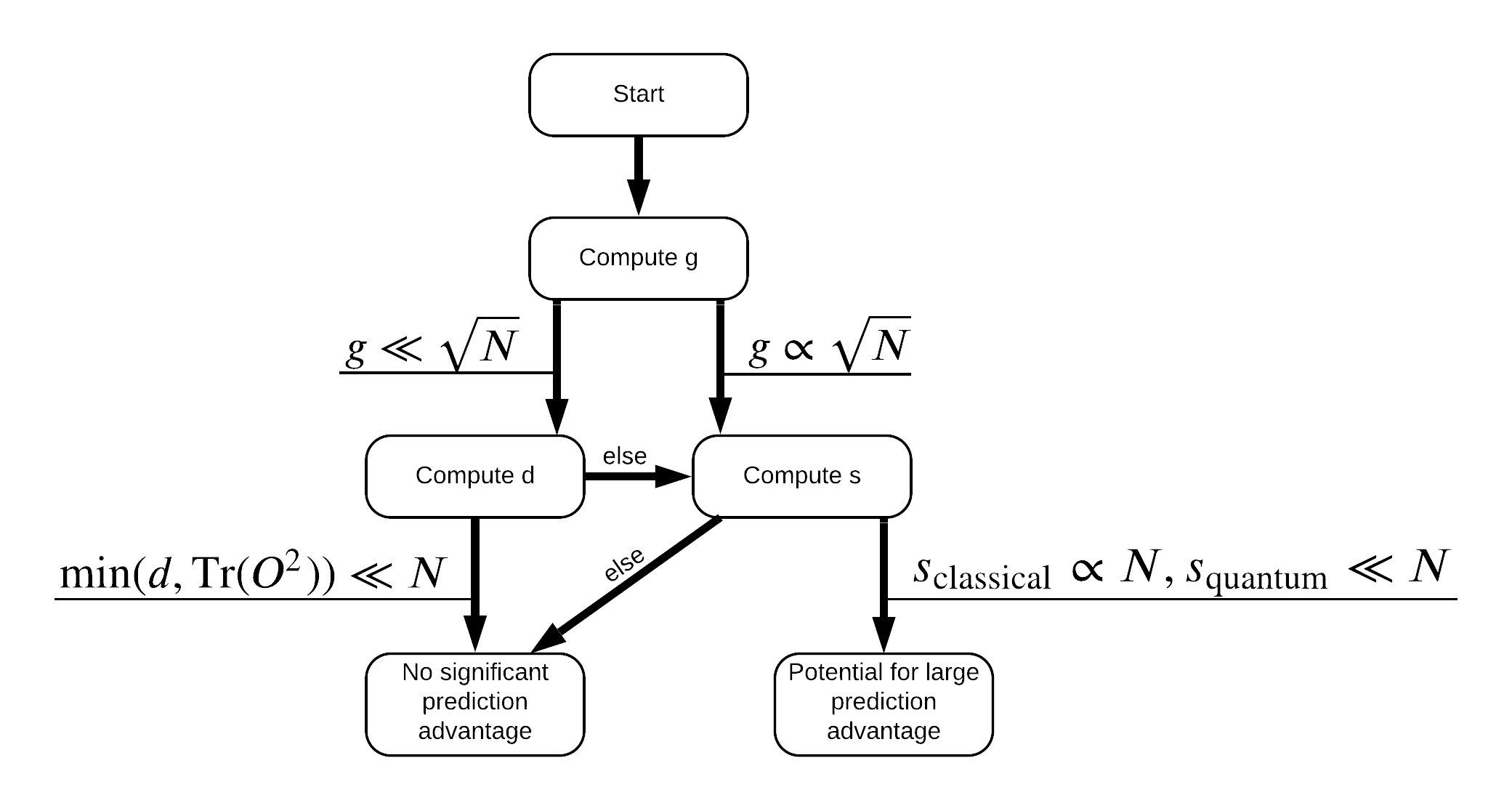
為了最大化量子模型和傳統模型之間的差異,您將嘗試最大化原始資料集和 PQK 特徵核心矩陣 \(g(K_1 || K_2) = \sqrt{ || \sqrt{K_2} K_1^{-1} \sqrt{K_2} || _\infty}\) 之間的幾何差異,使用 S_pqk, V_pqk 和 S_original, V_original。較大的 \(g\) 值可確保您最初在流程圖中向右移動,朝向量子案例中的預測優勢邁進。
def get_stilted_dataset(S, V, S_2, V_2, lambdav=1.1):
"""Prepare new labels that maximize geometric distance between kernels."""
S_diag = tf.linalg.diag(S ** 0.5)
S_2_diag = tf.linalg.diag(S_2 / (S_2 + lambdav) ** 2)
scaling = S_diag @ tf.transpose(V) @ \
V_2 @ S_2_diag @ tf.transpose(V_2) @ \
V @ S_diag
# Generate new lables using the largest eigenvector.
_, vecs = tf.linalg.eig(scaling)
new_labels = tf.math.real(
tf.einsum('ij,j->i', tf.cast(V @ S_diag, tf.complex64), vecs[-1])).numpy()
# Create new labels and add some small amount of noise.
final_y = new_labels > np.median(new_labels)
noisy_y = (final_y ^ (np.random.uniform(size=final_y.shape) > 0.95))
return noisy_y
y_relabel = get_stilted_dataset(S_pqk, V_pqk, S_original, V_original)
y_train_new, y_test_new = y_relabel[:N_TRAIN], y_relabel[N_TRAIN:]
3. 比較模型
現在您已準備好資料集,現在可以比較模型效能了。您將建立兩個小型前饋神經網路,並比較它們在取得 x_train_pqk 中找到的 PQK 特徵時的效能。
3.1 建立 PQK 增強模型
使用標準 tf.keras 程式庫功能,您現在可以建立並在 x_train_pqk 和 y_train_new 資料點上訓練模型
#docs_infra: no_execute
def create_pqk_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(32, activation='sigmoid', input_shape=[len(qubits) * 3,]))
model.add(tf.keras.layers.Dense(16, activation='sigmoid'))
model.add(tf.keras.layers.Dense(1))
return model
pqk_model = create_pqk_model()
pqk_model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.003),
metrics=['accuracy'])
pqk_model.summary()
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 32) 1088 _________________________________________________________________ dense_1 (Dense) (None, 16) 528 _________________________________________________________________ dense_2 (Dense) (None, 1) 17 ================================================================= Total params: 1,633 Trainable params: 1,633 Non-trainable params: 0 _________________________________________________________________
#docs_infra: no_execute
pqk_history = pqk_model.fit(tf.reshape(x_train_pqk, [N_TRAIN, -1]),
y_train_new,
batch_size=32,
epochs=1000,
verbose=0,
validation_data=(tf.reshape(x_test_pqk, [N_TEST, -1]), y_test_new))
3.2 建立傳統模型
與上述程式碼類似,您現在也可以建立無法存取矯揉造作資料集中 PQK 特徵的傳統模型。此模型可以使用 x_train 和 y_label_new 進行訓練。
#docs_infra: no_execute
def create_fair_classical_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(32, activation='sigmoid', input_shape=[DATASET_DIM,]))
model.add(tf.keras.layers.Dense(16, activation='sigmoid'))
model.add(tf.keras.layers.Dense(1))
return model
model = create_fair_classical_model()
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.03),
metrics=['accuracy'])
model.summary()
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_3 (Dense) (None, 32) 352 _________________________________________________________________ dense_4 (Dense) (None, 16) 528 _________________________________________________________________ dense_5 (Dense) (None, 1) 17 ================================================================= Total params: 897 Trainable params: 897 Non-trainable params: 0 _________________________________________________________________
#docs_infra: no_execute
classical_history = model.fit(x_train,
y_train_new,
batch_size=32,
epochs=1000,
verbose=0,
validation_data=(x_test, y_test_new))
3.3 比較效能
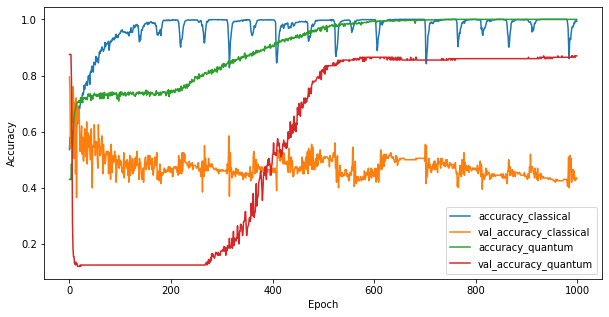
現在您已訓練這兩個模型,您可以快速繪製兩者之間驗證資料中效能差距的圖表。通常,這兩個模型都會在訓練資料上達到 > 0.9 的準確度。但是,在驗證資料中,顯然只有 PQK 特徵中找到的資訊足以讓模型良好地泛化到未見過的例項。
#docs_infra: no_execute
plt.figure(figsize=(10,5))
plt.plot(classical_history.history['accuracy'], label='accuracy_classical')
plt.plot(classical_history.history['val_accuracy'], label='val_accuracy_classical')
plt.plot(pqk_history.history['accuracy'], label='accuracy_quantum')
plt.plot(pqk_history.history['val_accuracy'], label='val_accuracy_quantum')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
<matplotlib.legend.Legend at 0x7f6d846ecee0>
4. 重要結論
您可以從這個實驗和 MNIST 實驗中得出幾個重要結論
今天的量子模型不太可能在傳統資料上擊敗傳統模型的效能。尤其是在今天可能有多達一百萬個資料點的傳統資料集上。
僅僅因為資料可能來自難以透過傳統方式模擬的量子電路,並不一定表示資料難以讓傳統模型學習。
對於量子模型來說易於學習,但對於傳統模型來說難以學習的資料集 (本質上最終是量子的) 確實存在,無論使用哪種模型架構或訓練演算法。