
模型訓練後量化是一種轉換技術,可縮減模型大小,同時改善 CPU 和硬體加速器延遲時間,且模型準確度幾乎不受影響。將已訓練的浮點 TensorFlow 模型轉換為 TensorFlow Lite 格式時,可以使用 TensorFlow Lite Converter 進行量化。
最佳化方法
有多種模型訓練後量化選項可供選擇。以下摘要表列出選項及其提供的優點
| 技術 | 優點 | 硬體 |
|---|---|---|
| 動態範圍量化 | 體積縮小 4 倍,速度提升 2 倍至 3 倍 | CPU |
| 完整整數量化 | 體積縮小 4 倍,速度提升 3 倍以上 | CPU、Edge TPU、微控制器 |
| Float16 量化 | 體積縮小 2 倍,GPU 加速 | CPU、GPU |
以下決策樹可協助您判斷哪種模型訓練後量化方法最適合您的使用案例
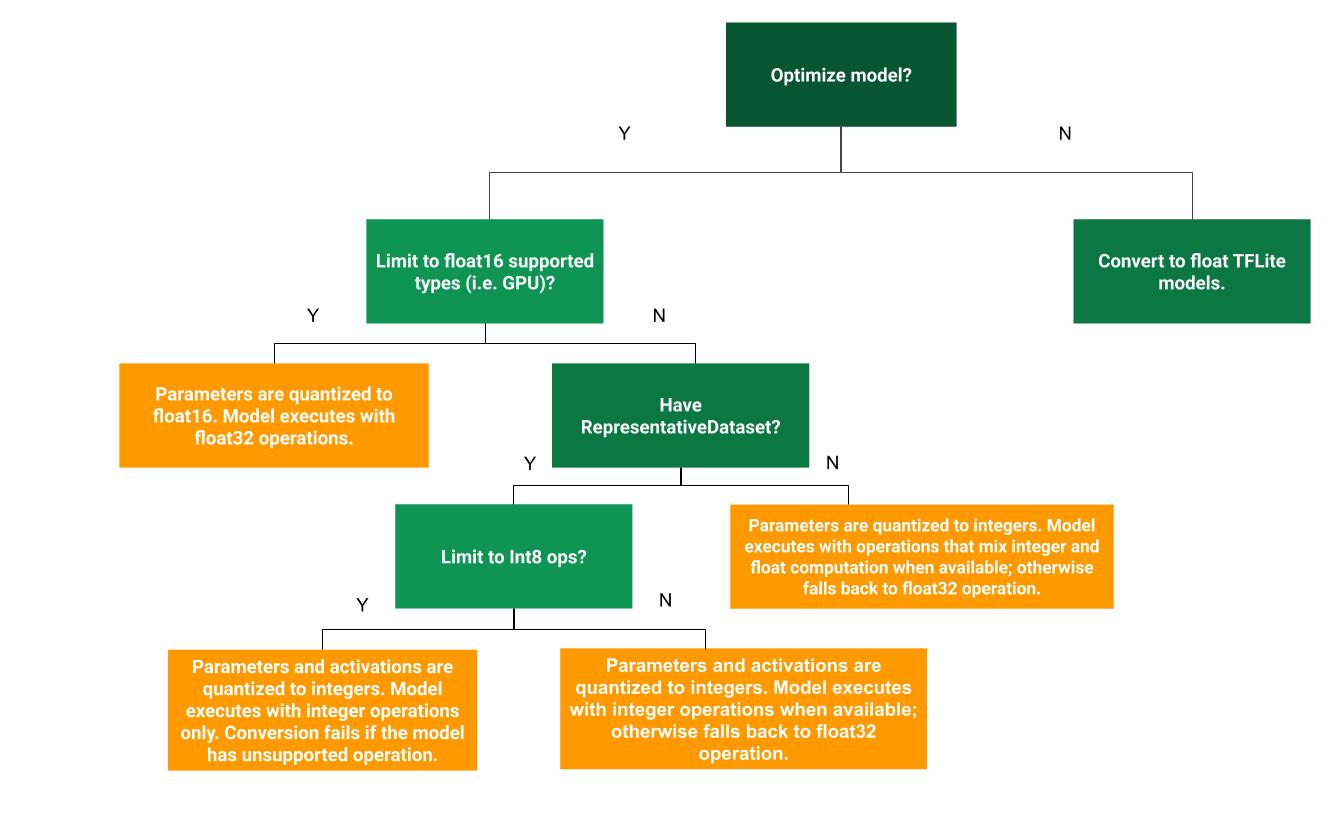
動態範圍量化
建議從動態範圍量化開始,因為它能減少記憶體用量並加快運算速度,而且您不必提供具代表性的校正資料集。這種量化類型僅在轉換時將權重從浮點靜態量化為整數,進而提供 8 位元的精確度
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
為了進一步縮短推論期間的延遲時間,「動態範圍」運算子會根據啟動範圍將啟動動態量化為 8 位元,並使用 8 位元權重和啟動執行運算。這種最佳化提供的延遲時間接近完全固定點推論。不過,輸出仍使用浮點儲存,因此動態範圍運算的加速效果不如完整固定點運算。
完整整數量化
為了進一步改善延遲時間、減少尖峰記憶體用量,並與僅限整數的硬體裝置或加速器相容,您可以確保所有模型數學運算都經過整數量化。
若要進行完整整數量化,您需要校正或估計模型中所有浮點張量的範圍,即 (最小值、最大值)。與權重和偏差等常數張量不同,除非我們執行幾個推論週期,否則模型輸入、啟動 (中繼層的輸出) 和模型輸出等變數張量無法校正。因此,轉換器需要具代表性的資料集來校正這些張量。這個資料集可以是訓練或驗證資料的一小部分子集 (約 100-500 個樣本)。請參閱下方的 representative_dataset() 函式。
從 TensorFlow 2.7 版本開始,您可以透過 簽名,將具代表性的資料集指定為以下範例
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
如果給定的 TensorFlow 模型中有多個簽名,您可以透過指定簽名金鑰來指定多個資料集
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
您可以透過提供輸入張量清單來產生具代表性的資料集
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
由於 TensorFlow 2.7 版本開始,我們建議使用以簽名為基礎的方法,而非以輸入張量清單為基礎的方法,因為輸入張量順序很容易翻轉。
為了測試目的,您可以使用虛擬資料集,如下所示
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
具有浮點備用方案的整數 (使用預設浮點輸入/輸出)
為了完整整數量化模型,但在沒有整數實作時使用浮點運算子 (以確保轉換順利進行),請使用下列步驟
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
僅限整數
建立僅限整數模型是 TensorFlow Lite for Microcontrollers 和 Coral Edge TPU 的常見使用案例。
此外,為了確保與僅限整數的裝置 (例如 8 位元微控制器) 和加速器 (例如 Coral Edge TPU) 相容,您可以針對所有運算強制執行完整整數量化,包括輸入和輸出,方法是使用下列步驟
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 量化
您可以將權重量化為 float16 (IEEE 標準 16 位元浮點數),以縮減浮點模型的大小。若要啟用權重的 float16 量化,請使用下列步驟
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 量化的優點如下:
- 它最多可將模型大小縮減一半 (因為所有權重都變成原始大小的一半)。
- 它造成的準確度損失極小。
- 它支援某些委派 (例如 GPU 委派),可以直接對 float16 資料進行運算,進而產生比 float32 運算更快的執行速度。
float16 量化的缺點如下:
- 它縮短延遲時間的效果不如量化為固定點數學運算。
- 根據預設,float16 量化模型在 CPU 上執行時,會將權重值「反量化」為 float32。(請注意,GPU 委派不會執行此反量化,因為它可以對 float16 資料進行運算。)
僅限整數:搭配 8 位元權重的 16 位元啟動 (實驗性)
這是實驗性量化方案。它與「僅限整數」方案類似,但啟動會根據其範圍量化為 16 位元,權重會量化為 8 位元整數,而偏差會量化為 64 位元整數。這進一步稱為 16x8 量化。
此量化的主要優點是它可以顯著提高準確度,但只會稍微增加模型大小。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
如果模型中的某些運算子不支援 16x8 量化,則模型仍然可以量化,但不受支援的運算子會保留為浮點。應將下列選項新增至 target_spec 以允許這樣做。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
此量化方案提供的準確度提升範例使用案例包括:
- 超高解析度、
- 音訊訊號處理,例如噪音消除和波束成形、
- 影像去噪、
- 從單一影像進行 HDR 重建。
此量化的缺點是
- 由於缺乏最佳化的核心實作,目前推論速度明顯慢於 8 位元完整整數。
- 目前它與現有的硬體加速 TFLite 委派不相容。
如需此量化模式的教學課程,請參閱這裡。
模型準確度
由於權重是在模型訓練後量化,因此可能會出現準確度損失,對於較小的網路而言尤其如此。預先訓練的完整量化模型在 TensorFlow Hub 上針對特定網路提供。務必檢查量化模型的準確度,以驗證準確度的任何降低是否在可接受的範圍內。有些工具可用於評估 TensorFlow Lite 模型準確度。
或者,如果準確度下降幅度過大,請考慮使用量化感知訓練。不過,這樣做需要在模型訓練期間修改以新增虛假量化節點,而本頁面上的模型訓練後量化技術則是使用現有的預先訓練模型。
量化張量的表示法
8 位元量化使用下列公式逼近浮點值。
\[real\_value = (int8\_value - zero\_point) \times scale\]
此表示法有兩個主要部分:
每個軸 (又稱為每個通道) 或每個張量權重,以 [-127, 127] 範圍內的 int8 二補數值表示,零點等於 0。
每個張量啟動/輸入,以 [-128, 127] 範圍內的 int8 二補數值表示,零點在 [-128, 127] 範圍內。
如需量化方案的詳細檢視,請參閱我們的量化規格。我們鼓勵想要插入 TensorFlow Lite 委派介面的硬體供應商實作其中描述的量化方案。