
基準測試工具
TensorFlow Lite 基準測試工具目前會測量及計算下列重要效能指標的統計資料
- 初始化時間
- 暖機狀態的推論時間
- 穩定狀態的推論時間
- 初始化時間期間的記憶體用量
- 整體記憶體用量
基準測試工具以 Android 和 iOS 適用的基準測試應用程式,以及原生命令列二進位檔的形式提供,而且全都共用相同的核心效能評估邏輯。請注意,由於執行階段環境的差異,可用的選項和輸出格式會略有不同。
Android 基準測試應用程式
透過 Android 使用基準測試工具有兩種選項。一種是原生基準測試二進位檔,另一種是 Android 基準測試應用程式,後者更能衡量模型在應用程式中的效能。無論是哪一種方式,基準測試工具的數字仍會與在實際應用程式中使用模型執行推論時略有不同。
這個 Android 基準測試應用程式沒有 UI。請使用 adb 命令安裝並執行,並使用 adb logcat 命令擷取結果。
下載或建構應用程式
使用以下連結下載每晚預先建構的 Android 基準測試應用程式
至於支援透過 Flex 委派使用 TF 運算子的 Android 基準測試應用程式,請使用以下連結
您也可以按照這些操作說明,從來源建構應用程式。
準備基準測試
在執行基準測試應用程式之前,請安裝應用程式並將模型檔案推送至裝置,如下所示
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
執行基準測試
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph 是必要參數。
graph:string
TFLite 模型檔案的路徑。
您可以指定更多選用參數來執行基準測試。
num_threads:int(預設值 = 1)
用於執行 TFLite 解譯器的執行緒數量。use_gpu:bool(預設值 = false)
使用 GPU 委派。use_nnapi:bool(預設值 = false)
使用 NNAPI 委派。use_xnnpack:bool(預設值 =false)
使用 XNNPACK 委派。use_hexagon:bool(預設值 =false)
使用 Hexagon 委派。
根據您使用的裝置,其中某些選項可能無法使用或沒有作用。如需您可以搭配基準測試應用程式執行的更多效能參數,請參閱參數。
使用 logcat 命令查看結果
adb logcat | grep "Inference timings"
基準測試結果會以以下形式回報
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
原生基準測試二進位檔
基準測試工具也以原生二進位檔 benchmark_model 的形式提供。您可以在 Linux、Mac、嵌入式裝置和 Android 裝置上從 Shell 命令列執行這個工具。
下載或建構二進位檔
按照以下連結下載每晚預先建構的原生命令列二進位檔
至於支援透過 Flex 委派使用 TF 運算子的每晚預先建構二進位檔,請使用以下連結
若要使用 TensorFlow Lite Hexagon 委派進行基準測試,我們也預先建構了必要的 libhexagon_interface.so 檔案 (詳情請參閱這裡)。從以下連結下載對應平台的檔案後,請將檔案重新命名為 libhexagon_interface.so。
您也可以從電腦上的來源建構原生基準測試二進位檔。
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
若要使用 Android NDK 工具鏈建構,您必須先按照這份指南設定建構環境,或使用這份指南中說明的 Docker 映像檔。
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
執行基準測試
若要在電腦上執行基準測試,請從 Shell 執行二進位檔。
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
您可以搭配原生命令列二進位檔使用與上述參數相同的一組參數。
分析模型運算
基準測試模型二進位檔也允許您分析模型運算,並取得每個運算子的執行時間。若要執行這項操作,請在叫用期間將標記 --enable_op_profiling=true 傳遞至 benchmark_model。詳情請參閱這裡。
在單次執行中適用於多個效能選項的原生基準測試二進位檔
也提供一個方便且簡單的 C++ 二進位檔,以便在單次執行中基準測試多個效能選項。這個二進位檔是根據上述每次只能基準測試單一效能選項的基準測試工具建構而成。它們共用相同的建構/安裝/執行程序,但這個二進位檔的 BUILD 目標名稱為 benchmark_model_performance_options,且需要一些額外參數。這個二進位檔的重要參數是
perf_options_list:string (預設值 = 'all')
要進行基準測試的 TFLite 效能選項逗號分隔清單。
您可以取得此工具每晚預先建構的二進位檔,如下所列
iOS 基準測試應用程式
若要在 iOS 裝置上執行基準測試,您需要從來源建構應用程式。將 TensorFlow Lite 模型檔案放入來源樹狀結構的 benchmark_data 目錄中,並修改 benchmark_params.json 檔案。這些檔案會封裝到應用程式中,而應用程式會從目錄讀取資料。請造訪 iOS 基準測試應用程式以取得詳細操作說明。
知名模型的效能基準測試
本節列出在某些 Android 和 iOS 裝置上執行知名模型時的 TensorFlow Lite 效能基準測試。
Android 效能基準測試
這些效能基準測試數字是使用原生基準測試二進位檔產生的。
對於 Android 基準測試,CPU 親和性設定為使用裝置上的大核心,以減少差異 (請參閱詳情)。
假設模型已下載並解壓縮至 /data/local/tmp/tflite_models 目錄。基準測試二進位檔是使用這些操作說明建構的,並假設位於 /data/local/tmp 目錄中。
執行基準測試的方式如下:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
若要使用 nnapi 委派執行,請設定 --use_nnapi=true。若要使用 GPU 委派執行,請設定 --use_gpu=true。
以下效能值是在 Android 10 上測量的。
| 模型名稱 | 裝置 | CPU,4 個執行緒 | GPU | NNAPI |
|---|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23.9 毫秒 | 6.45 毫秒 | 13.8 毫秒 |
| Pixel 4 | 14.0 毫秒 | 9.0 毫秒 | 14.8 毫秒 | |
| Mobilenet_1.0_224 (量化) | Pixel 3 | 13.4 毫秒 | --- | 6.0 毫秒 |
| Pixel 4 | 5.0 毫秒 | --- | 3.2 毫秒 | |
| NASNet mobile | Pixel 3 | 56 毫秒 | --- | 102 毫秒 |
| Pixel 4 | 34.5 毫秒 | --- | 99.0 毫秒 | |
| SqueezeNet | Pixel 3 | 35.8 毫秒 | 9.5 毫秒 | 18.5 毫秒 |
| Pixel 4 | 23.9 毫秒 | 11.1 毫秒 | 19.0 毫秒 | |
| Inception_ResNet_V2 | Pixel 3 | 422 毫秒 | 99.8 毫秒 | 201 毫秒 |
| Pixel 4 | 272.6 毫秒 | 87.2 毫秒 | 171.1 毫秒 | |
| Inception_V4 | Pixel 3 | 486 毫秒 | 93 毫秒 | 292 毫秒 |
| Pixel 4 | 324.1 毫秒 | 97.6 毫秒 | 186.9 毫秒 |
iOS 效能基準測試
這些效能基準測試數字是使用iOS 基準測試應用程式產生的。
若要執行 iOS 基準測試,已修改基準測試應用程式以納入適當的模型,並修改 benchmark_params.json 以將 num_threads 設定為 2。若要使用 GPU 委派,也將 "use_gpu" : "1" 和 "gpu_wait_type" : "aggressive" 選項新增至 benchmark_params.json。
| 模型名稱 | 裝置 | CPU,2 個執行緒 | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 毫秒 | 3.4 毫秒 |
| Mobilenet_1.0_224 (量化) | iPhone XS | 11 毫秒 | --- |
| NASNet mobile | iPhone XS | 30.4 毫秒 | --- |
| SqueezeNet | iPhone XS | 21.1 毫秒 | 15.5 毫秒 |
| Inception_ResNet_V2 | iPhone XS | 261.1 毫秒 | 45.7 毫秒 |
| Inception_V4 | iPhone XS | 309 毫秒 | 54.4 毫秒 |
追蹤 TensorFlow Lite 內部元件
在 Android 中追蹤 TensorFlow Lite 內部元件
Android 應用程式的 TensorFlow Lite 解譯器內部事件可以透過 Android 追蹤工具擷取。它們與 Android Trace API 的事件相同,因此從 Java/Kotlin 程式碼擷取的事件會與 TensorFlow Lite 內部事件一起顯示。
事件範例包括:
- 運算子叫用
- 委派修改圖表
- 張量配置
在不同的追蹤擷取選項中,本指南涵蓋 Android Studio CPU Profiler 和系統追蹤應用程式。如需其他選項,請參閱Perfetto 命令列工具或Systrace 命令列工具。
在 Java 程式碼中新增追蹤事件
以下是 Image Classification 範例應用程式中的程式碼片段。TensorFlow Lite 解譯器在 recognizeImage/runInference 區段中執行。這個步驟為選用步驟,但有助於注意推論呼叫的位置。
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
啟用 TensorFlow Lite 追蹤功能
若要啟用 TensorFlow Lite 追蹤功能,請在啟動 Android 應用程式之前,將 Android 系統屬性 debug.tflite.trace 設定為 1。
adb shell setprop debug.tflite.trace 1
如果在初始化 TensorFlow Lite 解譯器時已設定這個屬性,則會追蹤來自解譯器的重要事件 (例如,運算子叫用)。
在您擷取所有追蹤後,將屬性值設定為 0 以停用追蹤功能。
adb shell setprop debug.tflite.trace 0
Android Studio CPU Profiler
按照以下步驟使用 Android Studio CPU Profiler 擷取追蹤
從頂端選單中選取「執行」>「分析 '應用程式'」。
在 Profiler 視窗出現時,按一下 CPU 時間軸中的任何位置。
在 CPU 分析模式中選取「追蹤系統呼叫」。
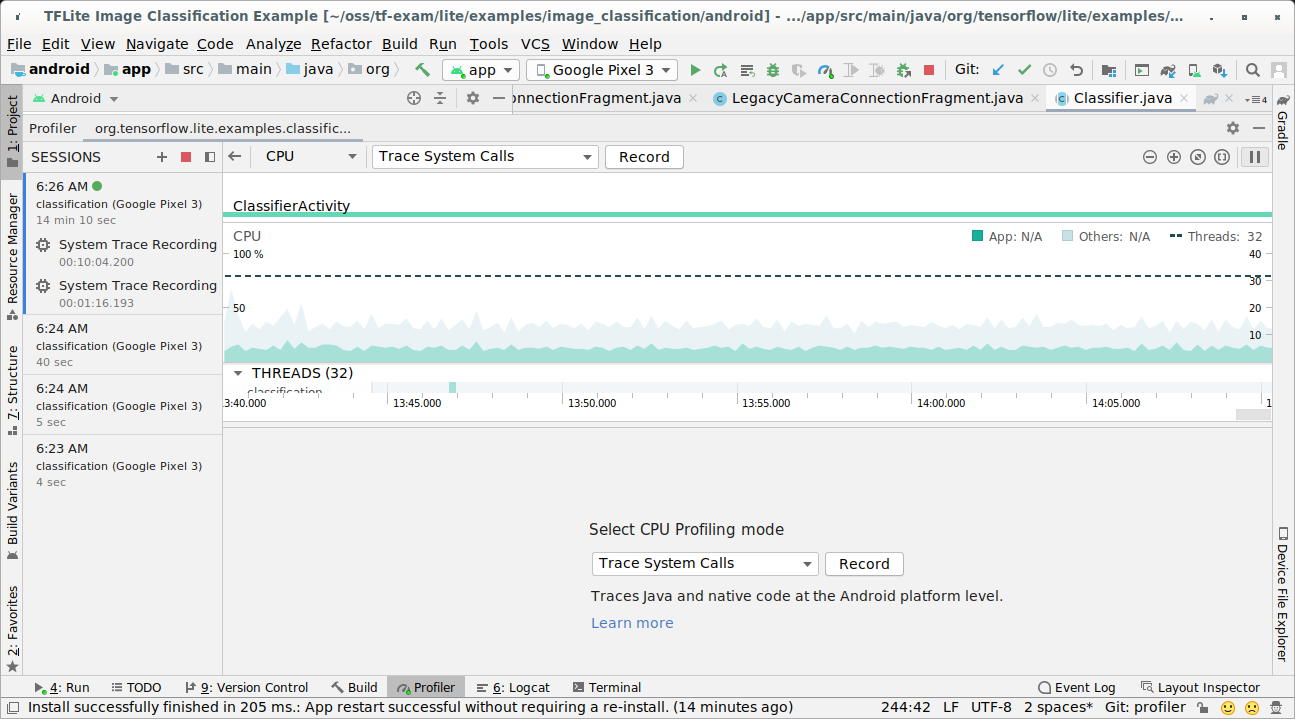
按下「錄製」按鈕。
按下「停止」按鈕。
調查追蹤結果。
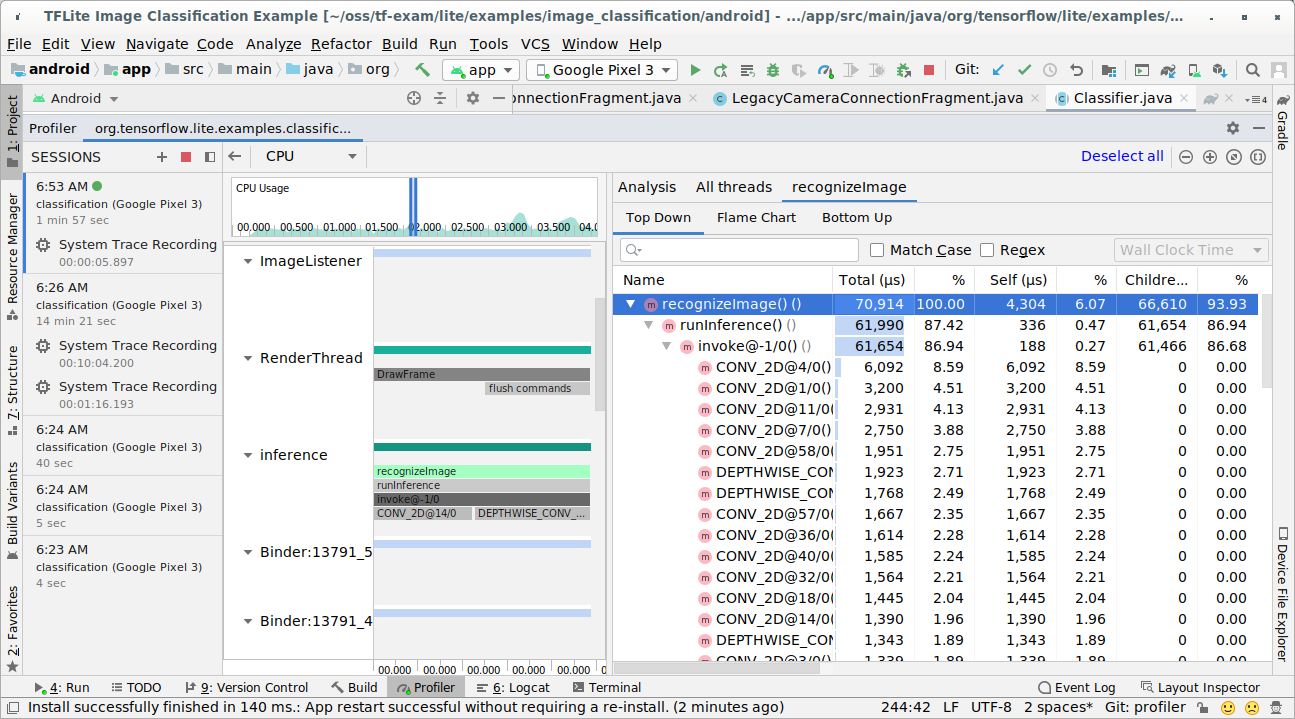
在這個範例中,您可以在執行緒中看到事件的階層和每個運算子時間的統計資料,也可以在執行緒之間看到整個應用程式的資料流程。
系統追蹤應用程式
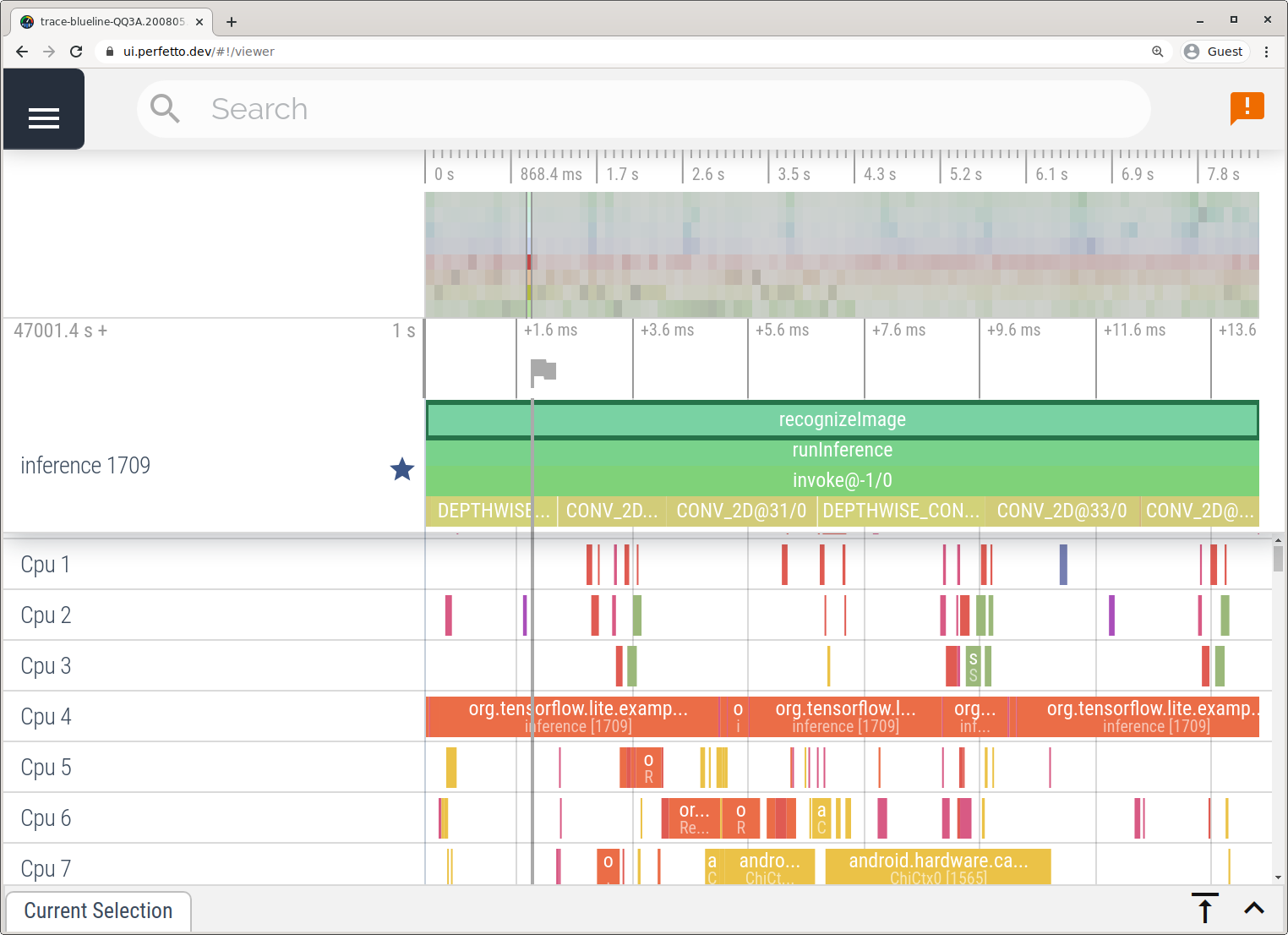
按照系統追蹤應用程式中詳述的步驟,在沒有 Android Studio 的情況下擷取追蹤。
在這個範例中,相同的 TFLite 事件會根據 Android 裝置的版本擷取並儲存為 Perfetto 或 Systrace 格式。擷取的追蹤檔案可以在 Perfetto UI 中開啟。
在 iOS 中追蹤 TensorFlow Lite 內部元件
iOS 應用程式的 TensorFlow Lite 解譯器內部事件可以透過 Xcode 隨附的 Instruments 工具擷取。它們是 iOS signpost 事件,因此從 Swift/Objective-C 程式碼擷取的事件會與 TensorFlow Lite 內部事件一起顯示。
事件範例包括:
- 運算子叫用
- 委派修改圖表
- 張量配置
啟用 TensorFlow Lite 追蹤功能
按照以下步驟設定環境變數 debug.tflite.trace
從 Xcode 的頂端選單中選取「Product (產品)」>「Scheme (配置)」>「Edit Scheme... (編輯配置...)」。
按一下左窗格中的「Profile (分析)」。
取消選取「Use the Run action's arguments and environment variables (使用 Run 動作的引數和環境變數)」核取方塊。
在「Environment Variables (環境變數)」區段下新增
debug.tflite.trace。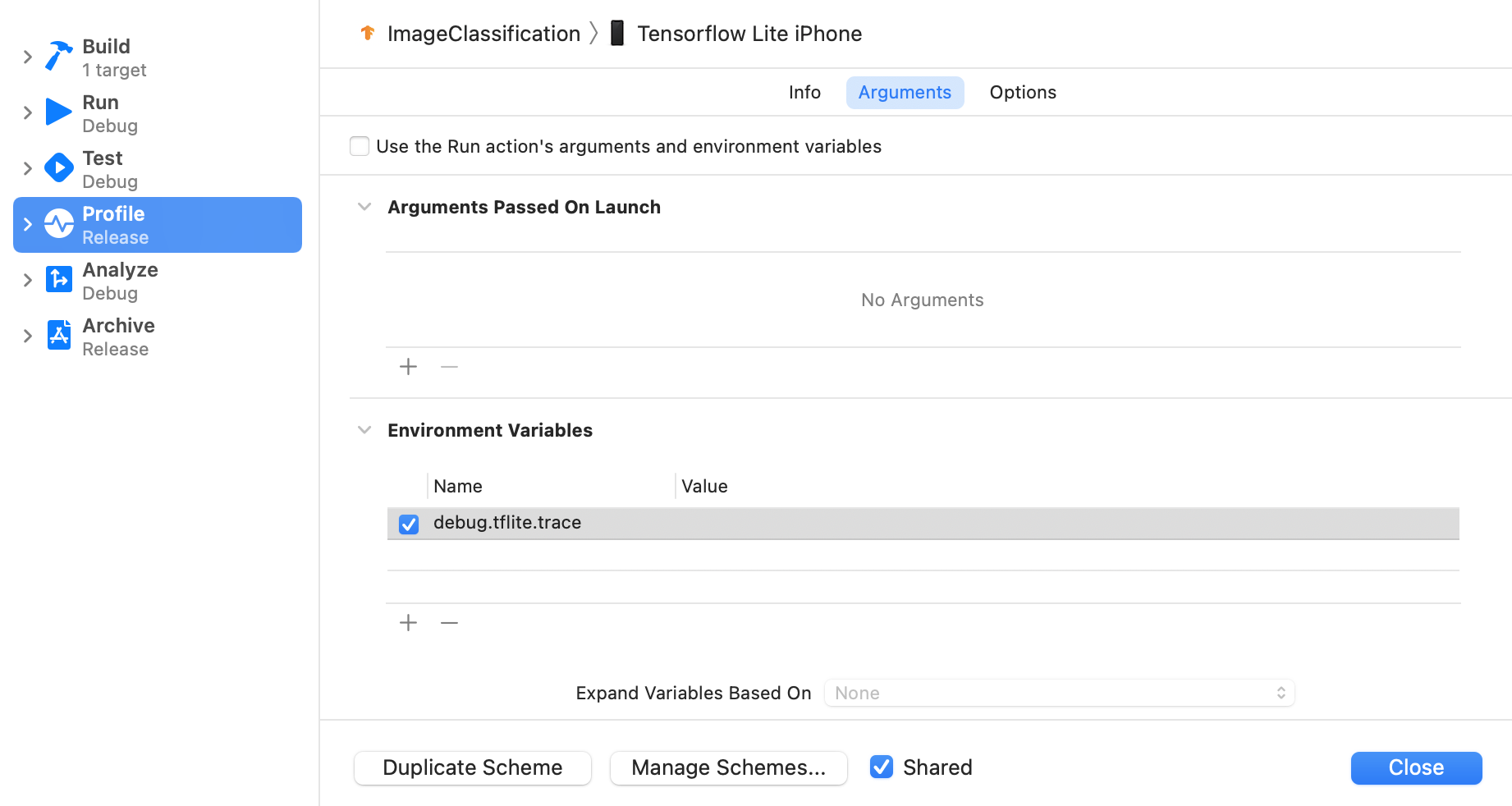
如果您想要在分析 iOS 應用程式時排除 TensorFlow Lite 事件,請移除環境變數以停用追蹤功能。
XCode Instruments
按照以下步驟擷取追蹤
從 Xcode 的頂端選單中選取「Product (產品)」>「Profile (分析)」。
當 Instruments 工具啟動時,按一下分析範本中的「Logging (記錄)」。
按下「Start (開始)」按鈕。
按下「停止」按鈕。
按一下「os_signpost」以展開 OS Logging 子系統項目。
按一下「org.tensorflow.lite」OS Logging 子系統。
調查追蹤結果。
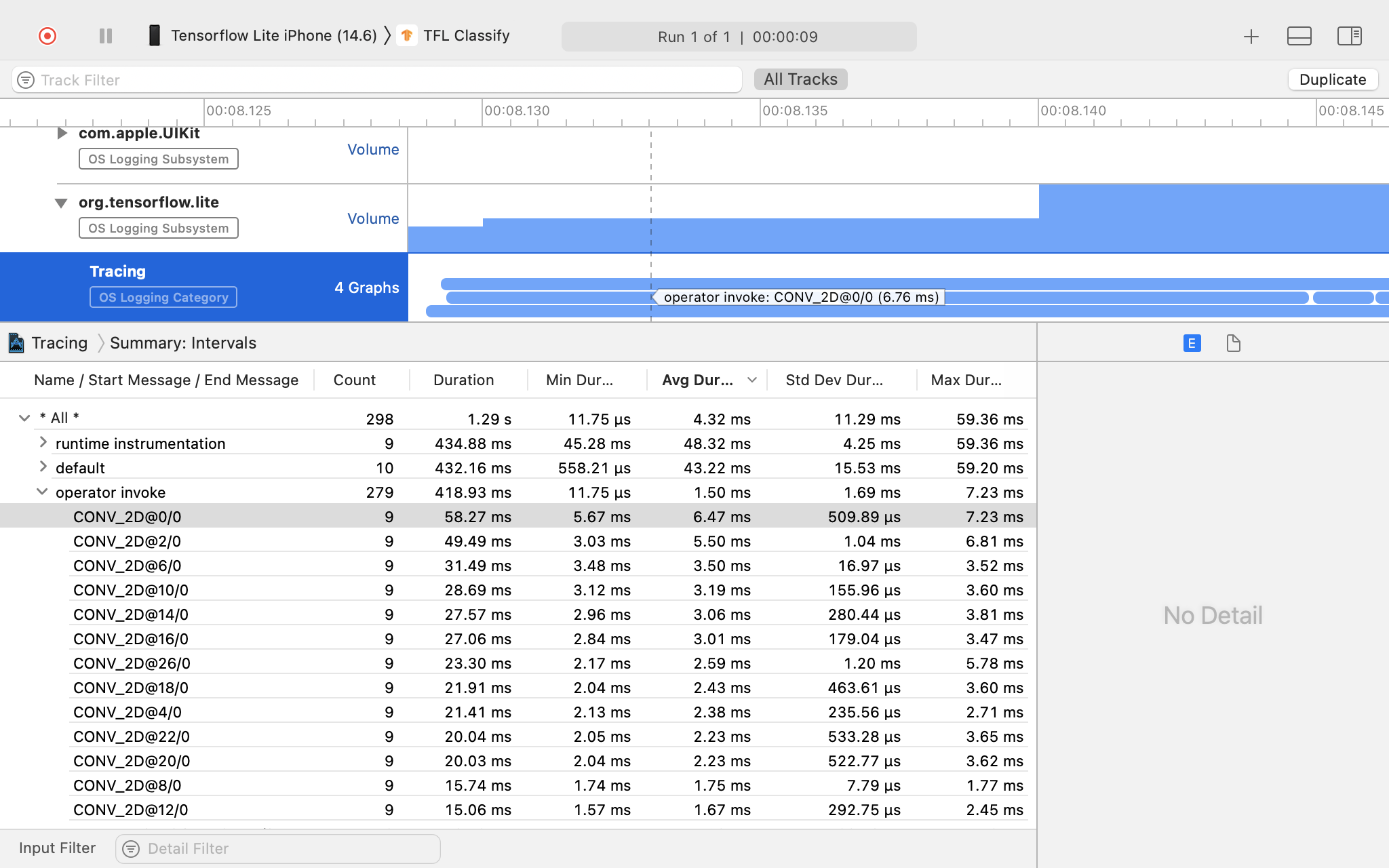
在這個範例中,您可以看到事件的階層和每個運算子時間的統計資料。
使用追蹤資料
追蹤資料可讓您找出效能瓶頸。
以下是您可以從效能分析器獲得的深入分析範例,以及改善效能的潛在解決方案
- 如果可用的 CPU 核心數量小於推論執行緒的數量,則 CPU 排程額外負荷可能會導致效能不佳。您可以重新排程應用程式中的其他 CPU 密集型工作,以避免與模型推論重疊,或調整解譯器執行緒的數量。
- 如果運算子未完全委派,則模型圖表的某些部分會在 CPU 而非預期的硬體加速器上執行。您可以將不受支援的運算子替換為類似的支援運算子。