
TensorFlow Lite metadata 為模型描述提供標準。Metadata 是關於模型功能及其輸入/輸出資訊的重要知識來源。Metadata 包含以下兩部分:
- 人工可讀部分,傳達使用模型的最佳實務做法,以及
- 機器可讀部分,可供程式碼產生器運用,例如 TensorFlow Lite Android 程式碼產生器和 Android Studio ML Binding 功能。
TensorFlow Hub 上發布的所有圖片模型都已填入 metadata。
具有 metadata 格式的模型
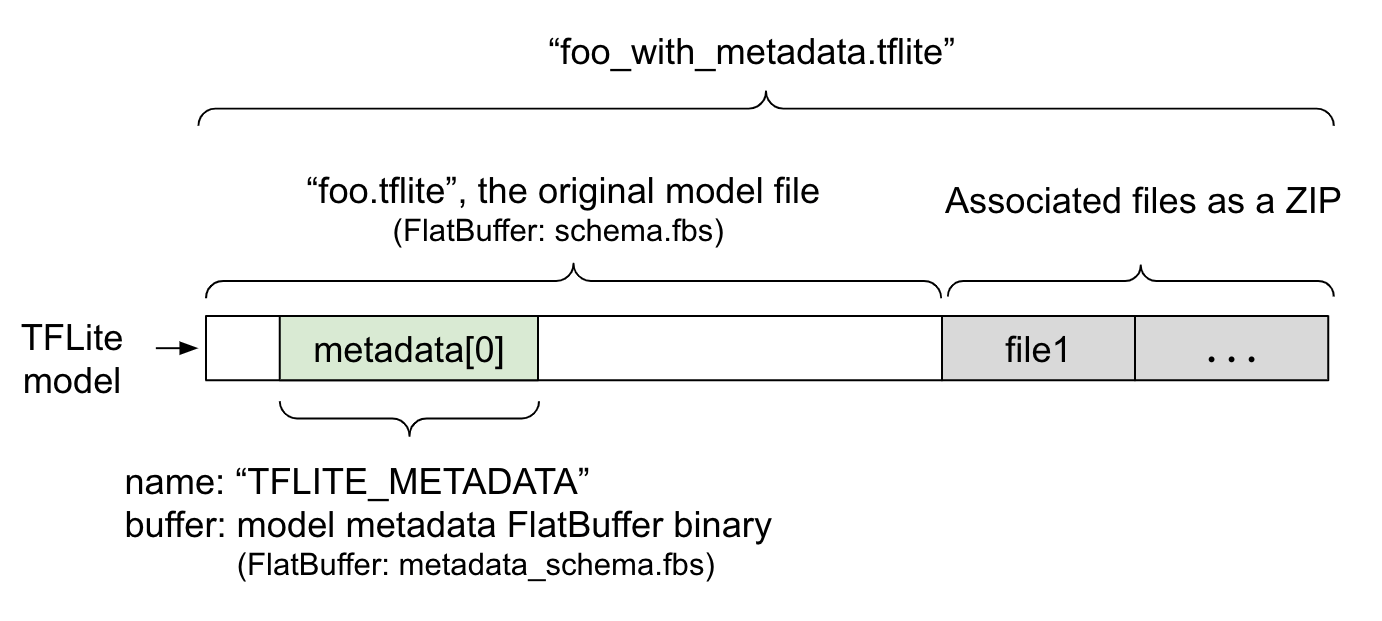
模型 metadata 定義於 metadata_schema.fbs (FlatBuffer 檔案) 中。如圖 1 所示,它儲存在 TFLite 模型結構描述的 metadata 欄位中,名稱為 "TFLITE_METADATA"。部分模型可能隨附相關檔案,例如 分類標籤檔案。這些檔案會使用 ZipFile 「append」模式 ('a' 模式) 串連到原始模型檔案的末尾,成為 ZIP 檔案。TFLite Interpreter 可以像以往一樣使用新的檔案格式。詳情請參閱「封裝相關檔案」。
請參閱以下關於如何填入、視覺化及讀取 metadata 的說明。
設定 metadata 工具
在將 metadata 新增至模型之前,您需要設定 Python 程式設計環境以執行 TensorFlow。如需設定方式的詳細指南,請參閱此處。
設定 Python 程式設計環境後,您需要安裝其他工具。
pip install tflite-support
TensorFlow Lite metadata 工具支援 Python 3。
使用 Flatbuffers Python API 新增 metadata
結構描述中的模型 metadata 分為三個部分:
- 模型資訊 - 模型的整體描述以及授權條款等項目。請參閱 ModelMetadata。
- 輸入資訊 - 輸入的描述以及所需的預先處理,例如正規化。請參閱 SubGraphMetadata.input_tensor_metadata。
- 輸出資訊 - 輸出的描述以及所需的後續處理,例如對應至標籤。請參閱 SubGraphMetadata.output_tensor_metadata。
由於 TensorFlow Lite 目前僅支援單一子圖,因此在顯示 metadata 和產生程式碼時,TensorFlow Lite 程式碼產生器和 Android Studio ML Binding 功能會使用 ModelMetadata.name 和 ModelMetadata.description,而非 SubGraphMetadata.name 和 SubGraphMetadata.description。
支援的輸入/輸出類型
輸入和輸出的 TensorFlow Lite metadata 並非針對特定模型類型設計,而是針對輸入和輸出類型設計。模型的功能為何並不重要,只要輸入和輸出類型包含以下類型或以下類型的組合,TensorFlow Lite metadata 就支援。
- 特徵 - 無正負號整數或 float32 數字。
- 圖片 - Metadata 目前支援 RGB 和灰階圖片。
- 邊界框 - 矩形邊界框。結構描述支援多種編號方案。
封裝相關檔案
TensorFlow Lite 模型可能隨附不同的相關檔案。例如,自然語言模型通常會有詞彙檔案,將字詞片段對應至字詞 ID;分類模型可能會有標籤檔案,指出物件類別。如果沒有相關檔案 (若有的話),模型將無法正常運作。
現在可以透過 metadata Python 程式庫將相關檔案與模型捆綁在一起。新的 TensorFlow Lite 模型會變成 zip 檔案,其中包含模型和相關檔案。可以使用常見的 zip 工具解壓縮。這種新的模型格式仍使用相同的檔案副檔名 .tflite。它與現有的 TFLite 框架和 Interpreter 相容。詳情請參閱「將 metadata 和相關檔案封裝到模型中」。
相關檔案資訊可以記錄在 metadata 中。根據檔案類型以及檔案附加的位置 (即 ModelMetadata、SubGraphMetadata 和 TensorMetadata),TensorFlow Lite Android 程式碼產生器可能會自動將對應的預先/後續處理套用至物件。詳情請參閱結構描述中每個相關檔案類型的「<Codegen usage>」章節。
正規化和量化參數
正規化是機器學習中常見的資料預先處理技術。正規化的目標是將值變更為通用比例,而不會扭曲值範圍的差異。
模型量化是一種技術,可針對儲存和運算減少權重的精確度表示法,以及選擇性的啟動。
就預先處理和後續處理而言,正規化和量化是兩個獨立的步驟。詳細資訊如下。
| 正規化 | 量化 | |
|---|---|---|
以下分別說明 MobileNet 中浮點模型和量化模型的輸入圖片參數值範例。 |
浮點模型: - 平均值:127.5 - 標準差:127.5 量化模型: - 平均值:127.5 - 標準差:127.5 |
浮點模型: - 零點:0 - 比例:1.0 量化模型: - 零點:128.0 - 比例:0.0078125f |
何時叫用? |
輸入:如果輸入資料在訓練時已正規化,則推論的輸入資料也需要據此正規化。 輸出:一般而言,輸出資料不會正規化。 |
浮點模型不需要量化。 量化模型在預先/後續處理中可能需要或不需要量化。這取決於輸入/輸出張量的資料類型。 - 浮點張量:預先/後續處理中不需要量化。量化運算和反量化運算已內建在模型圖表中。 - int8/uint8 張量:預先/後續處理中需要量化。 |
公式 |
正規化輸入 = (輸入 - 平均值) / 標準差 |
輸入量化:
q = f / 比例 + 零點 輸出反量化: f = (q - 零點) * 比例 |
參數在哪裡 |
由模型建立者填寫並儲存在模型 metadata 中,作為 NormalizationOptions |
由 TFLite 轉換器自動填寫,並儲存在 tflite 模型檔案中。 |
| 如何取得參數? | 透過 MetadataExtractor API [2] |
透過 TFLite Tensor API [1] 或 MetadataExtractor API [2] |
| 浮點模型和量化模型是否共用相同的值? | 是,浮點模型和量化模型具有相同的正規化參數 | 否,浮點模型不需要量化。 |
| TFLite Code 產生器或 Android Studio ML binding 是否在資料處理中自動產生? | 是 |
是 |
[1] TensorFlow Lite Java API 和 TensorFlow Lite C++ API。
[2] metadata 擷取器程式庫
在處理 uint8 模型的圖片資料時,有時會跳過正規化和量化。當像素值在 [0, 255] 範圍內時,這樣做是可以的。但一般而言,您應始終根據正規化和量化參數處理資料 (如適用)。
如果您在 metadata 中設定 NormalizationOptions,TensorFlow Lite Task Library 可以為您處理正規化。量化和反量化處理始終會封裝。
範例
您可以在此處找到關於應如何為不同類型的模型填入 metadata 的範例
圖片分類
在此處下載指令碼 here,此指令碼會將 metadata 填入 mobilenet_v1_0.75_160_quantized.tflite。像這樣執行指令碼
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
如要為其他圖片分類模型填入 metadata,請將模型規格 (如這個範例) 新增至指令碼中。本指南的其餘部分將重點介紹圖片分類範例中的部分重要章節,以說明重要元素。
深入探討圖片分類範例
模型資訊
Metadata 從建立新的模型資訊開始
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
輸入/輸出資訊
本節說明如何描述模型的輸入和輸出簽名。自動程式碼產生器可能會使用此 metadata 來建立預先處理和後續處理程式碼。如要建立關於張量的輸入或輸出資訊
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
圖片輸入
圖片是機器學習的常見輸入類型。TensorFlow Lite metadata 支援色彩空間等資訊,以及正規化等預先處理資訊。圖片的維度不需要手動指定,因為輸入張量的形狀已提供維度,且可自動推斷。
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
標籤輸出
標籤可以使用 TENSOR_AXIS_LABELS,透過相關檔案對應至輸出張量。
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
建立 metadata Flatbuffers
以下程式碼將模型資訊與輸入和輸出資訊結合
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
將 metadata 和相關檔案封裝到模型中
建立 metadata Flatbuffers 後,metadata 和標籤檔案會透過 populate 方法寫入 TFLite 檔案中
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
您可以透過 load_associated_files 將任意數量的相關檔案封裝到模型中。但是,至少必須封裝 metadata 中記錄的檔案。在本範例中,封裝標籤檔案是強制性的。
視覺化 metadata
您可以使用 Netron 視覺化您的 metadata,也可以使用 MetadataDisplayer 從 TensorFlow Lite 模型中讀取 metadata,並將其轉換為 json 格式
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio 也支援透過 Android Studio ML Binding 功能顯示 metadata。
Metadata 版本設定
metadata 結構描述會透過語意化版本號碼 (追蹤結構描述檔案的變更) 和 Flatbuffers 檔案識別碼 (指出真正的版本相容性) 進行版本設定。
語意化版本號碼
metadata 結構描述會透過語意化版本號碼 (例如 MAJOR.MINOR.PATCH) 進行版本設定。它會根據此處的規則追蹤結構描述變更。請參閱 1.0.0 版之後新增的欄位記錄。
Flatbuffers 檔案識別碼
如果遵循規則,語意化版本設定可保證相容性,但並不表示真正的不相容性。當主要版本號碼 (MAJOR number) 升高時,不一定表示回溯相容性已中斷。因此,我們使用 Flatbuffers 檔案識別碼 file_identifier 來表示 metadata 結構描述的真正相容性。檔案識別碼的長度正好是 4 個字元。它會固定為特定的 metadata 結構描述,且使用者無法變更。如果基於某些原因必須中斷 metadata 結構描述的回溯相容性,file_identifier 就會升高,例如從「M001」升至「M002」。File_identifier 預期變更的頻率會遠低於 metadata_version。
最低必要 metadata 剖析器版本
最低必要 metadata 剖析器版本是可以完整讀取 metadata Flatbuffers 的最低 metadata 剖析器版本 (Flatbuffers 產生的程式碼)。此版本實際上是所有已填入欄位的版本中最大的版本號碼,以及檔案識別碼指示的最小相容版本。當 metadata 填入 TFLite 模型時,最低必要 metadata 剖析器版本會由 MetadataPopulator 自動填入。如要進一步瞭解最低必要 metadata 剖析器版本的使用方式,請參閱 metadata 擷取器。
從模型讀取 metadata
Metadata Extractor 程式庫是便利的工具,可用於跨不同平台從模型讀取 metadata 和相關檔案 (請參閱 Java 版本和 C++ 版本)。您可以使用 Flatbuffers 程式庫以其他語言建構自己的 metadata 擷取器工具。
在 Java 中讀取 metadata
如要在 Android 應用程式中使用 Metadata Extractor 程式庫,建議使用 MavenCentral 上託管的 TensorFlow Lite Metadata AAR。其中包含 MetadataExtractor 類別,以及 metadata 結構描述和 模型結構描述的 FlatBuffers Java 繫結。
您可以在 build.gradle 依附元件中指定如下
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
如要使用每夜快照版本,請確認您已新增 Sonatype 快照版本存放區。
您可以使用指向模型的 ByteBuffer 初始化 MetadataExtractor 物件
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer 在 MetadataExtractor 物件的整個生命週期內都必須保持不變。如果模型 metadata 的 Flatbuffers 檔案識別碼與 metadata 剖析器的檔案識別碼不符,初始化可能會失敗。詳情請參閱 metadata 版本設定。
由於 Flatbuffers 的向前和回溯相容性機制,metadata 擷取器在檔案識別碼相符的情況下,將可成功讀取從所有過去和未來結構描述產生的 metadata。但是,較舊的 metadata 擷取器無法擷取未來結構描述中的欄位。metadata 的最低必要剖析器版本指出可完整讀取 metadata Flatbuffers 的最低 metadata 剖析器版本。您可以使用下列方法來驗證是否符合最低必要剖析器版本條件
public final boolean isMinimumParserVersionSatisfied();
允許傳入沒有 metadata 的模型。但是,叫用從 metadata 讀取的方法會導致執行階段錯誤。您可以透過叫用 hasMetadata 方法來檢查模型是否具有 metadata
public boolean hasMetadata();
MetadataExtractor 提供便利的功能,可讓您取得輸入/輸出張量的 metadata。例如:
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
雖然 TensorFlow Lite 模型結構描述支援多個子圖,但 TFLite Interpreter 目前僅支援單一子圖。因此,MetadataExtractor 在其方法中省略子圖索引作為輸入引數。
從模型讀取相關檔案
具有 metadata 和相關檔案的 TensorFlow Lite 模型基本上是 zip 檔案,可以使用常見的 zip 工具解壓縮,以取得相關檔案。例如,您可以解壓縮 mobilenet_v1_0.75_160_quantized 並擷取模型中的標籤檔案,如下所示
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
您也可以透過 Metadata Extractor 程式庫讀取相關檔案。
在 Java 中,將檔案名稱傳遞至 MetadataExtractor.getAssociatedFile 方法
public InputStream getAssociatedFile(String fileName);
同樣地,在 C++ 中,可以使用 ModelMetadataExtractor::GetAssociatedFile 方法來完成
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;