

影片分類是識別影片內容的機器學習任務。影片分類模型是在影片資料集上訓練,該資料集包含一組獨特的類別,例如不同的動作或移動。模型接收影片幀作為輸入,並輸出影片中每個類別的機率。
影片分類和影像分類模型都使用影像作為輸入,以預測這些影像屬於預定義類別的機率。但是,影片分類模型也會處理相鄰幀之間的時空關係,以識別影片中的動作。
例如,可以訓練影片動作辨識模型來識別人類動作,例如跑步、拍手和揮手。下圖顯示 Android 上影片分類模型的輸出。
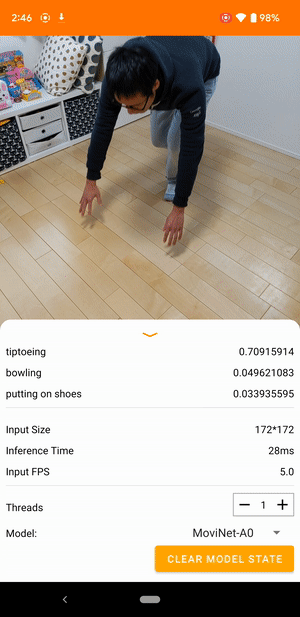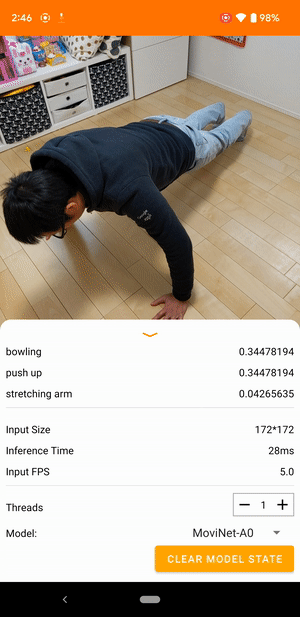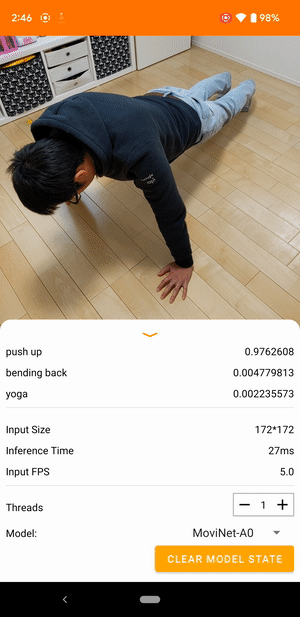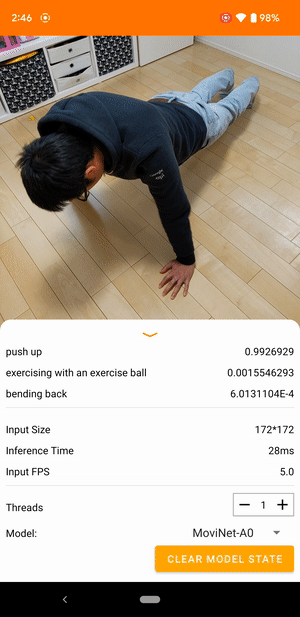
開始使用
如果您使用的平台不是 Android 或 Raspberry Pi,或者您已熟悉 TensorFlow Lite API,請下載初始影片分類模型和支援檔案。您也可以使用 TensorFlow Lite 支援函式庫,建構您自己的自訂推論管線。
如果您是 TensorFlow Lite 新手,並且正在使用 Android 或 Raspberry Pi,請探索下列範例應用程式以協助您開始使用。
Android
Android 應用程式使用裝置的後置鏡頭進行連續影片分類。推論是使用 TensorFlow Lite Java API 執行的。示範應用程式會分類幀並即時顯示預測的分類。
Raspberry Pi
Raspberry Pi 範例使用 TensorFlow Lite 和 Python 執行連續影片分類。將 Raspberry Pi 連接到攝影機 (例如 Pi Camera) 以執行即時影片分類。若要檢視攝影機的結果,請將螢幕連接到 Raspberry Pi,並使用 SSH 存取 Pi Shell (以避免將鍵盤連接到 Pi)。
開始之前,請設定您的 Raspberry Pi 並安裝 Raspberry Pi OS (最好更新至 Buster)。
模型說明
行動影片網路 (MoViNets) 是一系列針對行動裝置優化的高效影片分類模型。MoViNets 在多個大型影片動作辨識資料集上展示了最先進的準確性和效率,使其非常適合影片動作辨識任務。
TensorFlow Lite 的 MoviNet 模型有三種變體:MoviNet-A0、MoviNet-A1 和 MoviNet-A2。這些變體是使用 Kinetics-600 資料集訓練的,以識別 600 種不同的人類動作。MoviNet-A0 最小、最快且準確度最低。MoviNet-A2 最大、最慢且準確度最高。MoviNet-A1 是 A0 和 A2 之間的折衷方案。
運作方式
在訓練期間,會為影片分類模型提供影片及其相關標籤。每個標籤是模型將學習辨識的獨特概念或類別的名稱。對於影片動作辨識,影片將是人類動作,而標籤將是相關動作。
影片分類模型可以學習預測新影片是否屬於訓練期間提供的任何類別。這個過程稱為推論。您也可以使用 遷移學習,透過使用預先存在的模型來識別新類別的影片。
此模型是串流模型,可接收連續影片並即時回應。當模型接收影片串流時,它會識別影片中是否呈現訓練資料集中的任何類別。對於每個幀,模型都會傳回這些類別,以及影片代表該類別的機率。給定時間的範例輸出可能如下所示
| 動作 | 機率 |
|---|---|
| 廣場舞 | 0.02 |
| 穿針 | 0.08 |
| 撥弄手指 | 0.23 |
| 揮手 | 0.67 |
輸出中的每個動作都對應於訓練資料中的標籤。機率表示影片中顯示該動作的可能性。
模型輸入
模型接受 RGB 影片幀串流作為輸入。輸入影片的大小是彈性的,但理想情況下,它應符合模型訓練解析度和幀率
- MoviNet-A0:172 x 172,5 fps
- MoviNet-A1:172 x 172,5 fps
- MoviNet-A1:224 x 224,5 fps
輸入影片預期具有介於 0 到 1 之間的色彩值,遵循通用的 影像輸入慣例。
在內部,模型也會透過使用先前幀中收集的資訊來分析每個幀的上下文。這是透過從模型輸出中獲取內部狀態,並將其回饋到模型中以用於即將到來的幀來完成。
模型輸出
模型會傳回一系列標籤及其對應的分數。這些分數是 logit 值,代表每個類別的預測。這些分數可以使用 softmax 函數 (tf.nn.softmax) 轉換為機率。
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
在內部,模型輸出也包括來自模型的內部狀態,並將其回饋到模型中以用於即將到來的幀。
效能基準
效能基準數字是使用 基準測試工具 產生的。MoviNets 僅支援 CPU。
效能是根據模型在給定硬體上執行推論所需的時間來衡量的。時間越短表示模型速度越快。準確度是根據模型正確分類影片中類別的頻率來衡量的。
| 模型名稱 | 大小 | 準確度 * | 裝置 | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (整數量化) | 3.1 MB | 65% | Pixel 4 | 5 毫秒 |
| Pixel 3 | 11 毫秒 | |||
| MoviNet-A1 (整數量化) | 4.5 MB | 70% | Pixel 4 | 8 毫秒 |
| Pixel 3 | 19 毫秒 | |||
| MoviNet-A2 (整數量化) | 5.1 MB | 72% | Pixel 4 | 15 毫秒 |
| Pixel 3 | 36 毫秒 |
* 在 Kinetics-600 資料集上測量的 Top-1 準確度。
** 在 CPU 上以單執行緒執行時測量的延遲。
模型客製化
預先訓練的模型經過訓練,可辨識來自 Kinetics-600 資料集的 600 種人類動作。您也可以使用遷移學習重新訓練模型,以辨識原始集合中沒有的人類動作。若要執行此操作,您需要一組訓練影片,用於您想要併入模型中的每個新動作。
如需在自訂資料上微調模型的詳細資訊,請參閱 MoViNets 存放區和 MoViNets 教學課程。
延伸閱讀與資源
使用下列資源以深入瞭解本頁面討論的概念