
與代理人進行棋盤遊戲,該代理人使用強化學習進行訓練,並使用 TensorFlow Lite 部署。
開始使用
如果您是 TensorFlow Lite 新手,並且正在使用 Android,我們建議您探索以下範例應用程式,它可以幫助您開始使用。
如果您使用的平台不是 Android,或者您已經熟悉 TensorFlow Lite API,則可以下載我們訓練好的模型。
運作方式
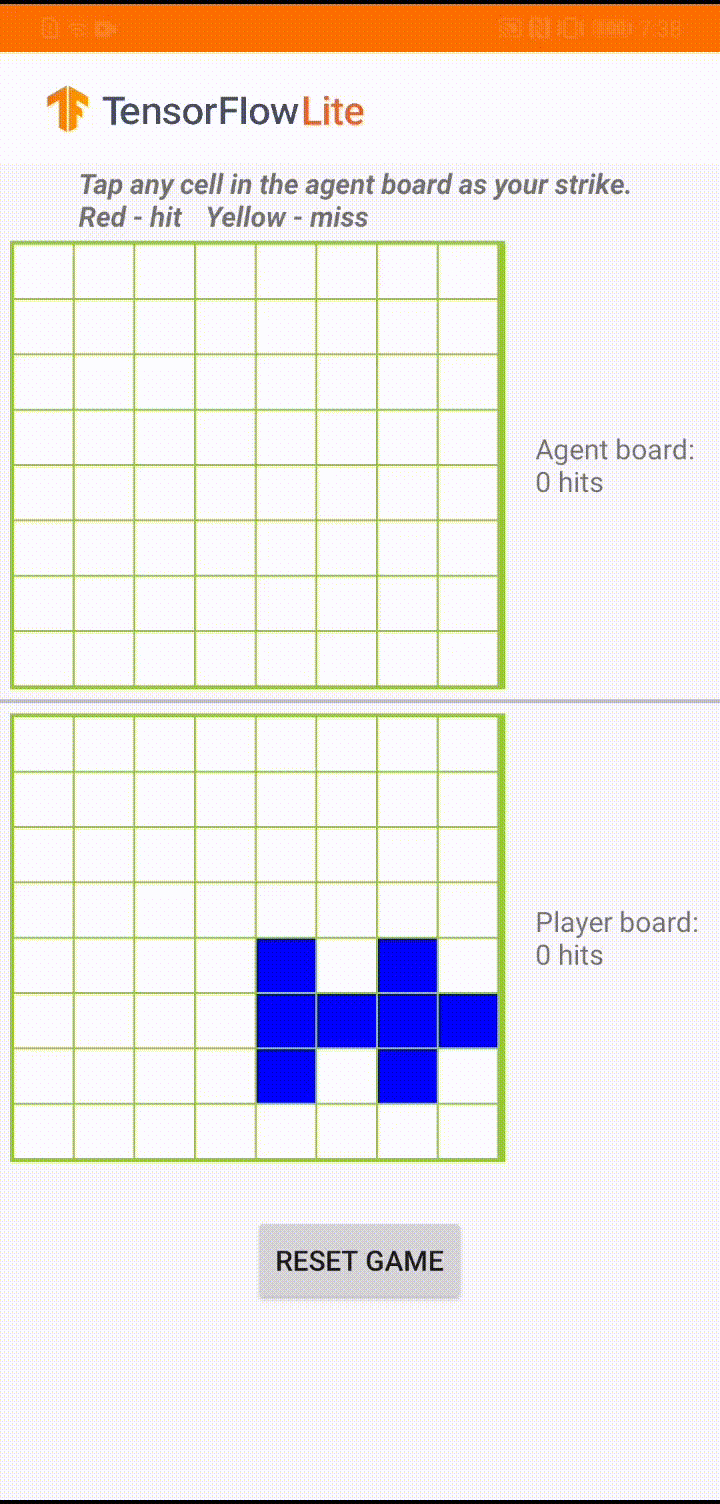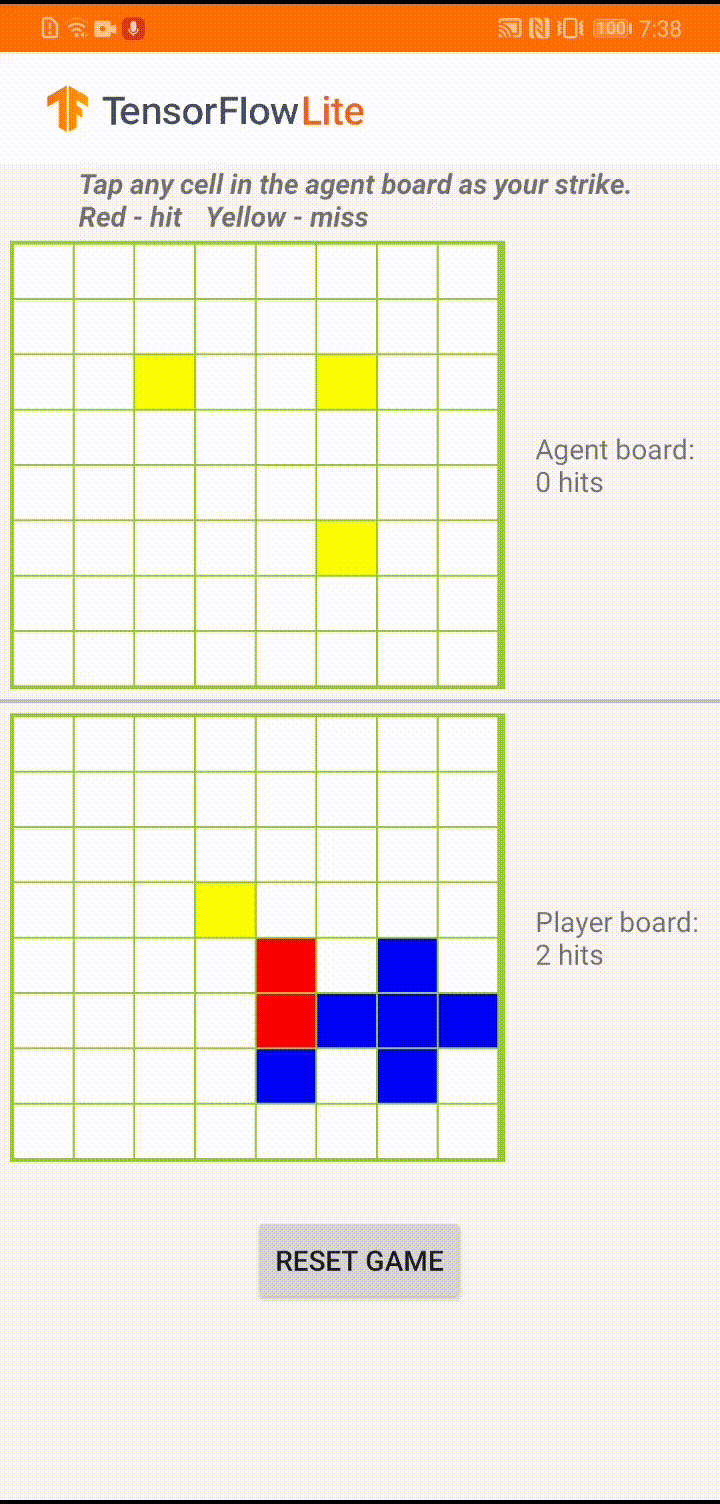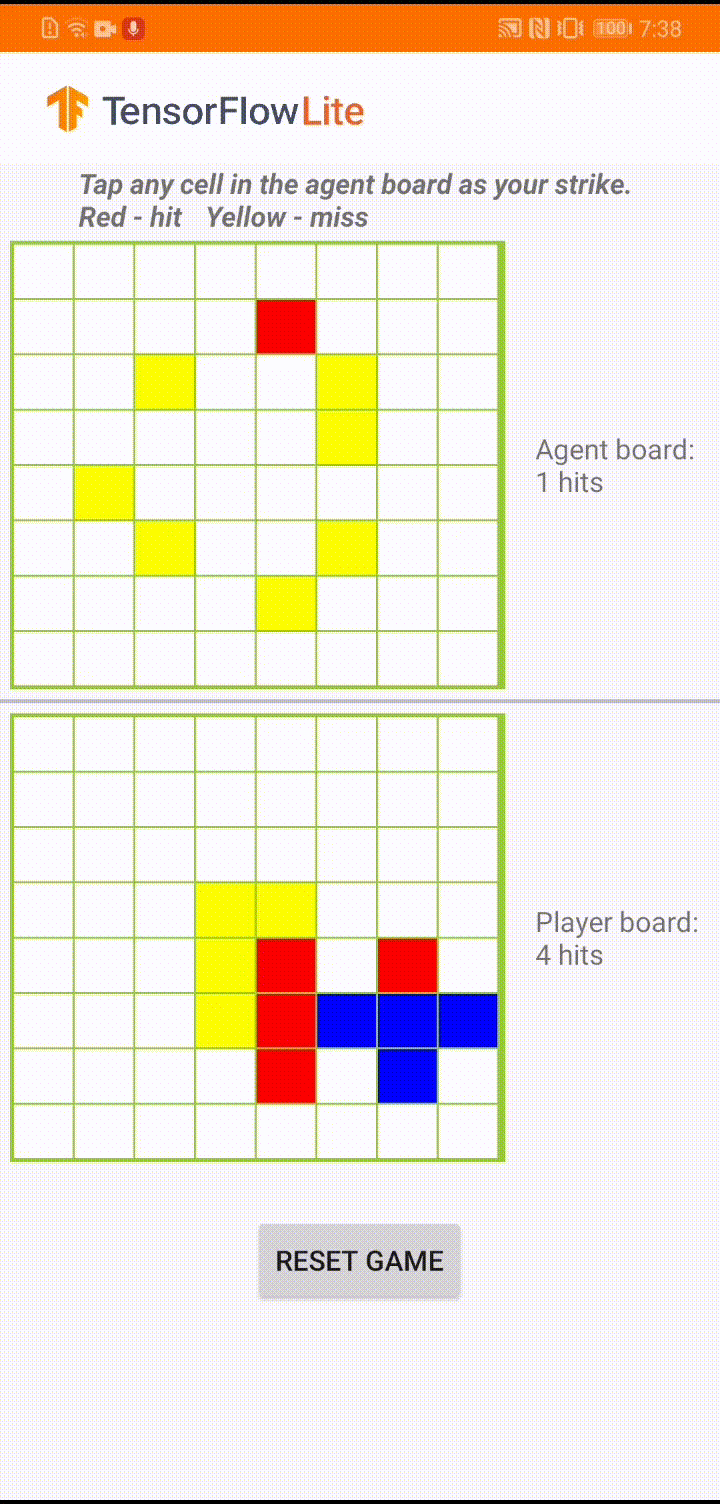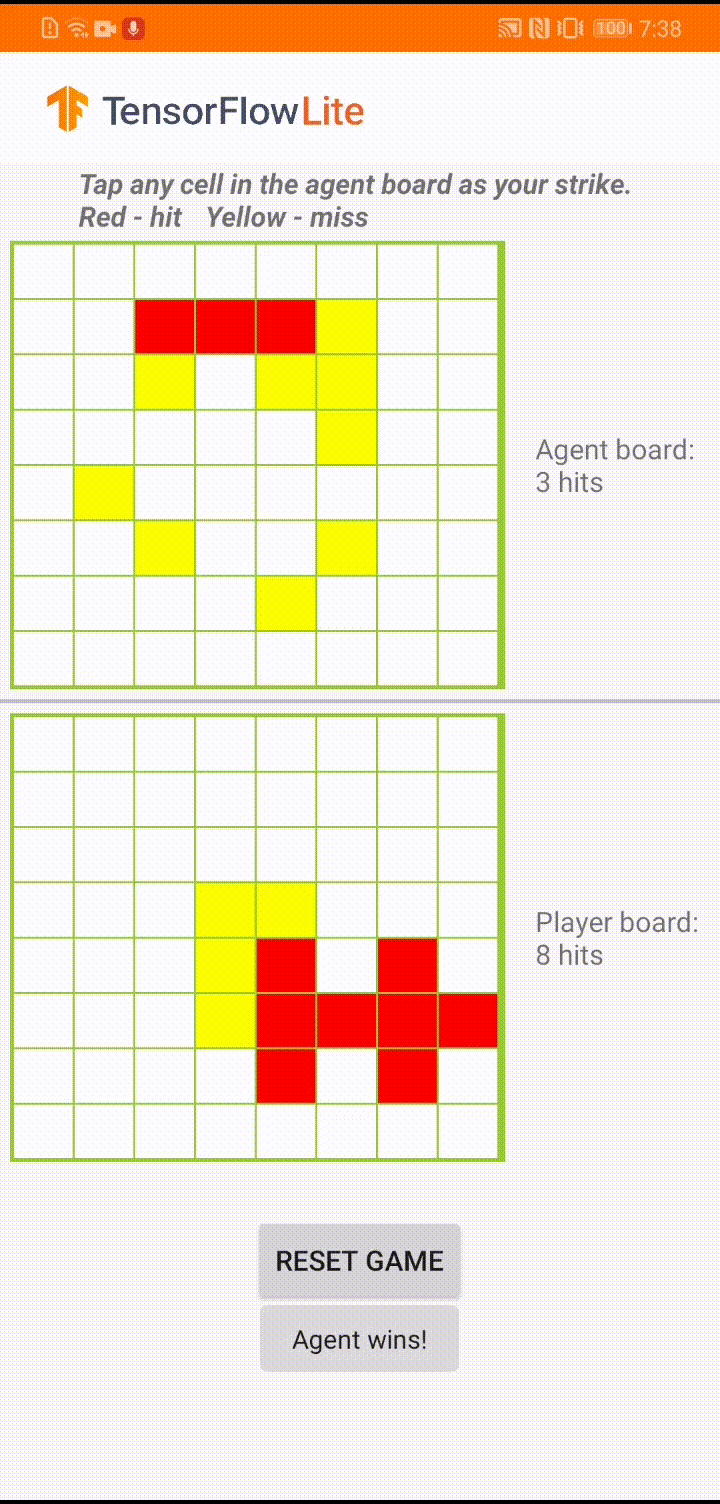
此模型是為遊戲代理人建構的,用於玩一款名為「Plane Strike」的小型棋盤遊戲。如需快速瞭解此遊戲及其規則,請參閱此 README。
在應用程式 UI 的底層,我們建構了一個與人類玩家對戰的代理人。該代理人是一個 3 層 MLP,它將棋盤狀態作為輸入,並輸出 64 個可能棋盤格中每個格子的預測分數。該模型使用策略梯度 (REINFORCE) 進行訓練,您可以在此處找到訓練程式碼。在訓練代理人後,我們將模型轉換為 TFLite 並將其部署在 Android 應用程式中。
在 Android 應用程式中的實際遊戲過程中,當輪到代理人採取行動時,代理人會查看人類玩家的棋盤狀態 (底部的棋盤),其中包含先前成功和不成功攻擊 (命中和未命中) 的相關資訊,並使用訓練好的模型來預測下一次攻擊的位置,以便在人類玩家完成遊戲之前結束遊戲。
效能基準
效能基準數字是使用 此處描述的工具產生的。
| 模型名稱 | 模型大小 | 裝置 | CPU |
|---|---|---|---|
| 策略梯度 | 84 Kb | Pixel 3 (Android 10) | 0.01 毫秒* |
| Pixel 4 (Android 10) | 0.01 毫秒* |
* 使用 1 個執行緒。
輸入
模型接受 3D float32 張量,形狀為 (1, 8, 8) 作為棋盤狀態。
輸出
模型傳回 2D float32 張量,形狀為 (1,64),作為 64 個可能攻擊位置中每個位置的預測分數。
訓練您自己的模型
您可以透過變更 訓練程式碼中的 BOARD_SIZE 參數,為較大/較小的棋盤訓練您自己的模型。