

識別音訊代表內容的工作稱為音訊分類。音訊分類模型經過訓練,可辨識各種音訊事件。例如,您可以訓練模型來辨識代表三種不同事件的事件:拍手、彈指和打字。TensorFlow Lite 提供經過最佳化的預先訓練模型,您可以在行動應用程式中部署這些模型。如要進一步瞭解如何使用 TensorFlow 進行音訊分類,請參閱這裡。
下圖顯示音訊分類模型在 Android 上的輸出。
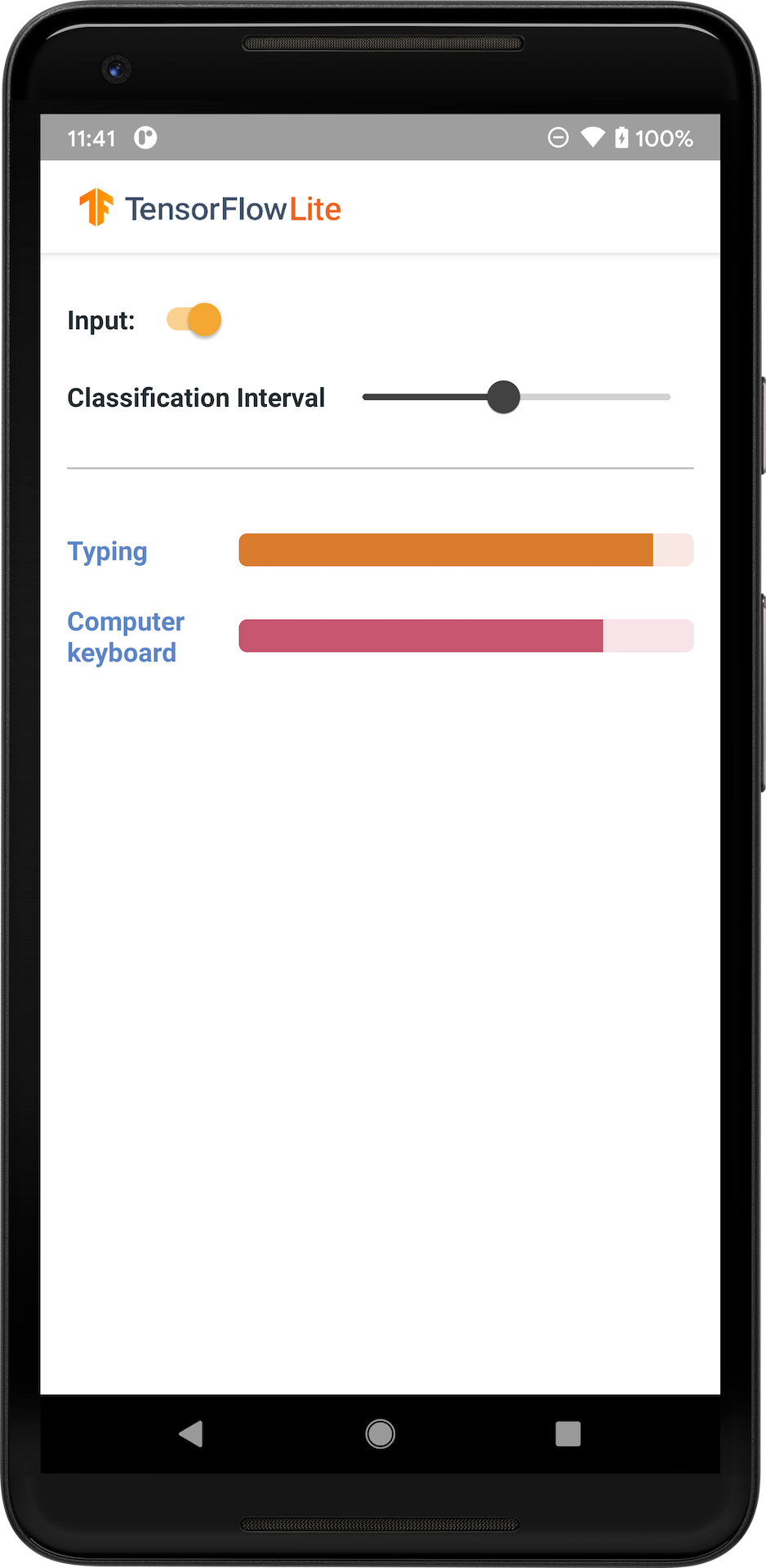
開始使用
如果您是 TensorFlow Lite 新手,且正在使用 Android,建議您探索下列範例應用程式,這些應用程式可協助您開始使用。
您可以運用 TensorFlow Lite Task Library 的現成 API,只需幾行程式碼即可整合音訊分類模型。您也可以使用 TensorFlow Lite Support Library 建構自己的自訂推論管道。
下方的 Android 範例示範如何使用 TFLite Task Library 實作
如果您使用的平台不是 Android/iOS,或者您已熟悉 TensorFlow Lite API,請下載入門模型和支援檔案 (如果適用)。
模型說明
YAMNet 是一個音訊事件分類器,可將音訊波形做為輸入,並針對 AudioSet 詞彙表中的 521 個音訊事件,獨立進行預測。此模型使用 MobileNet v1 架構,並使用 AudioSet 語料庫進行訓練。此模型最初在 TensorFlow Model Garden 中發布,其中包含模型原始碼、原始模型檢查點和更詳細的文件。
運作方式
有兩個版本的 YAMNet 模型已轉換為 TFLite
YAMNet 是原始音訊分類模型,具有動態輸入大小,適用於遷移學習、網路和行動部署。它也具有更複雜的輸出。
YAMNet/classification 是量化版本,具有更簡單的固定長度影格輸入 (15600 個樣本),並傳回 521 個音訊事件類別的單一分數向量。
輸入
此模型接受長度為 15600 的 1 維 float32 Tensor 或 NumPy 陣列,其中包含以 mono 16 kHz 樣本表示,範圍為 [-1.0, +1.0] 的 0.975 秒波形。
輸出
此模型會傳回形狀為 (1, 521) 的 2 維 float32 Tensor,其中包含 YAMNet 支援的 AudioSet 詞彙表中 521 個類別中每個類別的預測分數。分數張量的欄索引 (0-520) 會使用 YAMNet 類別對應 (以相關檔案 yamnet_label_list.txt 的形式封裝到模型檔案中) 對應至對應的 AudioSet 類別名稱。請參閱下方的用法。
適合用途
YAMNet 可用於
- 做為獨立音訊事件分類器,針對各種音訊事件提供合理的基準。
- 做為高階特徵擷取器:YAMNet 的 1024 維嵌入輸出可用做另一個模型的輸入特徵,然後可以針對特定工作在少量資料上訓練該模型。這樣做可以快速建立專門的音訊分類器,而無需大量標記資料,也無需端對端訓練大型模型。
- 做為暖啟動:YAMNet 模型參數可用於初始化較大型模型的一部分,以便更快進行微調和模型探索。
限制
- YAMNet 的分類器輸出尚未跨類別校正,因此您無法直接將輸出視為機率。對於任何給定的工作,您很可能需要使用工作專用資料執行校正,讓您可以指派適當的每個類別分數門檻和縮放比例。
- YAMNet 已在數百萬個 YouTube 影片上進行訓練,雖然這些影片非常多樣化,但平均 YouTube 影片與任何給定工作預期的音訊輸入之間,仍然可能存在網域不符的情況。您應該預期需要進行一定程度的微調和校正,才能讓 YAMNet 在您建構的任何系統中可用。
模型自訂
提供的預先訓練模型經過訓練,可偵測 521 種不同的音訊類別。如需類別的完整清單,請參閱模型存放區中的標籤檔案。
您可以使用稱為遷移學習的技術,重新訓練模型以辨識原始集合中沒有的類別。例如,您可以重新訓練模型以偵測多種鳥鳴聲。為此,您需要一組要訓練之每個新標籤的訓練音訊。建議的方式是使用 TensorFlow Lite Model Maker 程式庫,這可簡化使用自訂資料集訓練 TensorFlow Lite 模型 (只需幾行程式碼) 的流程。它使用遷移學習來減少所需的訓練資料量和時間。您也可以從音訊辨識的遷移學習中學習遷移學習的範例。
延伸閱讀和資源
使用下列資源進一步瞭解與音訊分類相關的概念