|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
總覽
本教學課程概述 TensorFlow Lattice (TFL) 程式庫提供的限制和正規化子。這裡我們在合成資料集上使用 TFL 預製模型,但請注意,本教學課程中的所有內容也可以使用 TFL Keras 層建構的模型來完成。
繼續之前,請確認您的執行階段已安裝所有必要的套件 (如下面的程式碼儲存格中匯入的套件)。
設定
安裝 TF Lattice 套件
pip install --pre -U tensorflow tf-keras tensorflow-lattice tensorflow_decision_forests pydot graphviz
匯入必要的套件
import tensorflow as tf
import tensorflow_lattice as tfl
import tensorflow_decision_forests as tfdf
from IPython.core.pylabtools import figsize
import functools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tempfile
logging.disable(sys.maxsize)
# Use Keras 2.
version_fn = getattr(tf.keras, "version", None)
if version_fn and version_fn().startswith("3."):
import tf_keras as keras
else:
keras = tf.keras
本指南中使用的預設值
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
餐廳評等訓練資料集
假設一個簡化的情境,我們想要判斷使用者是否會點擊餐廳搜尋結果。任務是根據輸入特徵預測點擊率 (CTR)
- 平均評分 (
avg_rating):數值特徵,值介於 [1,5] 範圍內。 - 評論數 (
num_reviews):數值特徵,值上限為 200,我們將其用作衡量趨勢的指標。 - 價格評級 (
dollar_rating):類別特徵,字串值位於集合 {"D", "DD", "DDD", "DDDD"} 中。
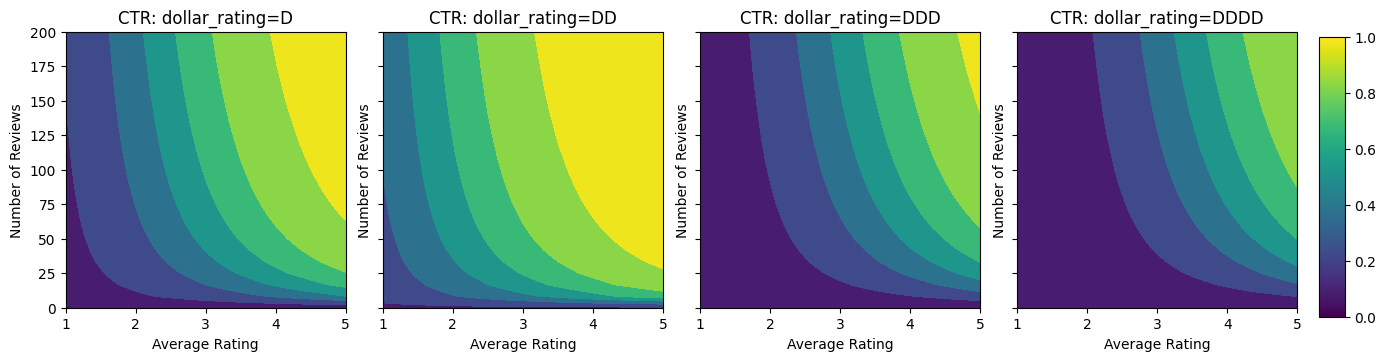
這裡我們建立一個合成資料集,其中真實 CTR 由以下公式給定
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
其中 \(b(\cdot)\) 將每個 dollar_rating 轉換為基準值
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
此公式反映典型的使用者模式。例如,在其他所有條件都相同的情況下,使用者偏好星級較高的餐廳,而「$$」餐廳的點擊次數會多於「$」,其次是「$$$」和「$$$$」。
dollar_ratings_vocab = ["D", "DD", "DDD", "DDDD"]
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
讓我們看看此 CTR 函數的等高線圖。
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
figsize(13, 3.5 * len(fns))
fig, axes = plt.subplots(
len(fns), len(dollar_ratings_vocab), sharey=True, layout="constrained"
)
axes = axes.flatten()
axes_index = 0
for fn_name, fn in fns:
for dollar_rating_split in dollar_ratings_vocab:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(), dollar_ratings)
title = "{}: dollar_rating={}".format(fn_name, dollar_rating_split)
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1,
)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
if len(fns) <= 2:
cax = fig.add_axes([
axes[-1].get_position().x1 + 0.11,
axes[-1].get_position().y0,
0.02,
0.8,
])
_ = fig.colorbar(color_bar(), cax=cax)
plot_fns([("CTR", click_through_rate)])
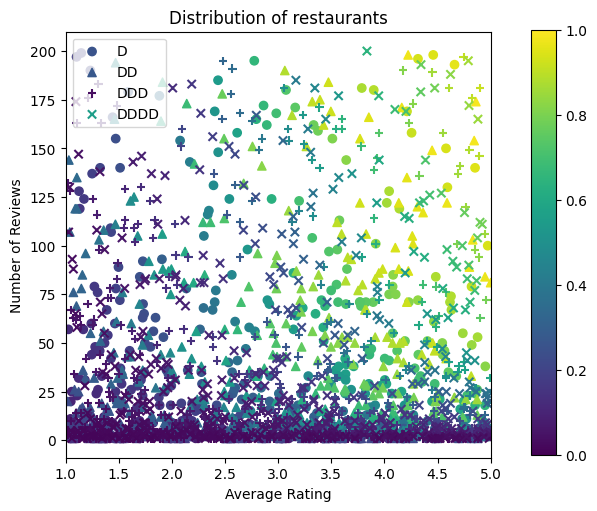
準備資料
我們現在需要建立我們的合成資料集。我們先產生餐廳及其特徵的模擬資料集。
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(dollar_ratings_vocab, n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, layout="constrained")
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([1.05, 0.1, 0.05, 0.85]))
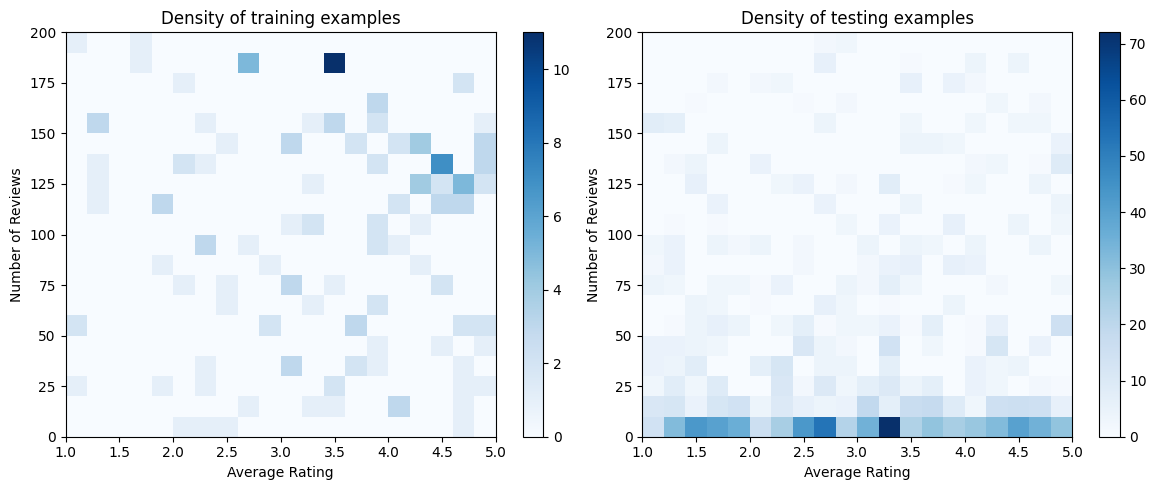
讓我們產生訓練、驗證和測試資料集。當餐廳在搜尋結果中被檢視時,我們可以將使用者的參與度 (點擊或未點擊) 記錄為一個樣本點。
在實務上,使用者通常不會瀏覽所有搜尋結果。這表示使用者可能只會看到目前使用的排名模型已視為「良好」的餐廳。因此,「良好」的餐廳更常被曝光,並且在訓練資料集中過度呈現。當使用更多特徵時,訓練資料集在特徵空間的「不良」部分可能存在很大的缺口。
當模型用於排名時,通常會針對所有相關結果進行評估,這些結果的分佈更均勻,但訓練資料集無法充分呈現。在這種情況下,彈性且複雜的模型可能會因過度擬合過度呈現的資料點而失敗,進而缺乏泛化能力。我們透過應用領域知識來新增形狀限制來處理此問題,以引導模型在無法從訓練資料集中取得預測值時做出合理的預測。
在本範例中,訓練資料集主要由使用者與良好且熱門餐廳的互動組成。測試資料集具有均勻分佈,以模擬上述討論的評估設定。請注意,在真實問題設定中,此類測試資料集將不可用。
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views)),
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
ds_train = tfdf.keras.pd_dataframe_to_tf_dataset(
data_train, label="clicked", batch_size=BATCH_SIZE
)
ds_val = tfdf.keras.pd_dataframe_to_tf_dataset(
data_val, label="clicked", batch_size=BATCH_SIZE
)
ds_test = tfdf.keras.pd_dataframe_to_tf_dataset(
data_test, label="clicked", batch_size=BATCH_SIZE
)
# feature_analysis_data is used to find quantiles of featurse.
feature_analysis_data = data_train.copy()
feature_analysis_data["dollar_rating"] = feature_analysis_data[
"dollar_rating"
].map({v: i for i, v in enumerate(dollar_ratings_vocab)})
feature_analysis_data = dict(feature_analysis_data)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [
(axs[0], data_train, "training"),
(axs[1], data_test, "testing"),
]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
2024-03-23 11:20:52.020222: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:282] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
擬合梯度提升樹
我們先建立幾個輔助函數,用於繪製圖表和計算驗證與測試指標。
def pred_fn(model, from_logits, avg_ratings, num_reviews, dollar_rating):
preds = model.predict(
tf.data.Dataset.from_tensor_slices({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}).batch(1),
verbose=0,
)
if from_logits:
preds = tf.math.sigmoid(preds)
return preds
def analyze_model(models, from_logits=False, print_metrics=True):
pred_fns = []
for model, name in models:
if print_metrics:
metric = model.evaluate(ds_val, return_dict=True, verbose=0)
print("Validation AUC: {}".format(metric["auc"]))
metric = model.evaluate(ds_test, return_dict=True, verbose=0)
print("Testing AUC: {}".format(metric["auc"]))
pred_fns.append(
("{} pCTR".format(name), functools.partial(pred_fn, model, from_logits))
)
pred_fns.append(("CTR", click_through_rate))
plot_fns(pred_fns)
我們可以在資料集上擬合 TensorFlow 梯度提升決策樹
gbt_model = tfdf.keras.GradientBoostedTreesModel(
features=[
tfdf.keras.FeatureUsage(name="num_reviews"),
tfdf.keras.FeatureUsage(name="avg_rating"),
tfdf.keras.FeatureUsage(name="dollar_rating"),
],
exclude_non_specified_features=True,
num_threads=1,
num_trees=32,
max_depth=6,
min_examples=10,
growing_strategy="BEST_FIRST_GLOBAL",
random_seed=42,
temp_directory=tempfile.mkdtemp(),
)
gbt_model.compile(metrics=[keras.metrics.AUC(name="auc")])
gbt_model.fit(ds_train, validation_data=ds_val, verbose=0)
analyze_model([(gbt_model, "GBT")])
[WARNING 24-03-23 11:20:53.0848 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS". [WARNING 24-03-23 11:20:53.0849 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS". [WARNING 24-03-23 11:20:53.0849 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB". Num validation examples: tf.Tensor(155, shape=(), dtype=int32) [INFO 24-03-23 11:20:56.9615 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpr9581nmh/model/ with prefix 2d8654c85f474a4e [INFO 24-03-23 11:20:56.9631 UTC quick_scorer_extended.cc:911] The binary was compiled without AVX2 support, but your CPU supports it. Enable it for faster model inference. [INFO 24-03-23 11:20:56.9632 UTC abstract_model.cc:1344] Engine "GradientBoostedTreesQuickScorerExtended" built [INFO 24-03-23 11:20:56.9632 UTC kernel.cc:1061] Use fast generic engine Validation AUC: 0.7145258188247681 Testing AUC: 0.8356180191040039
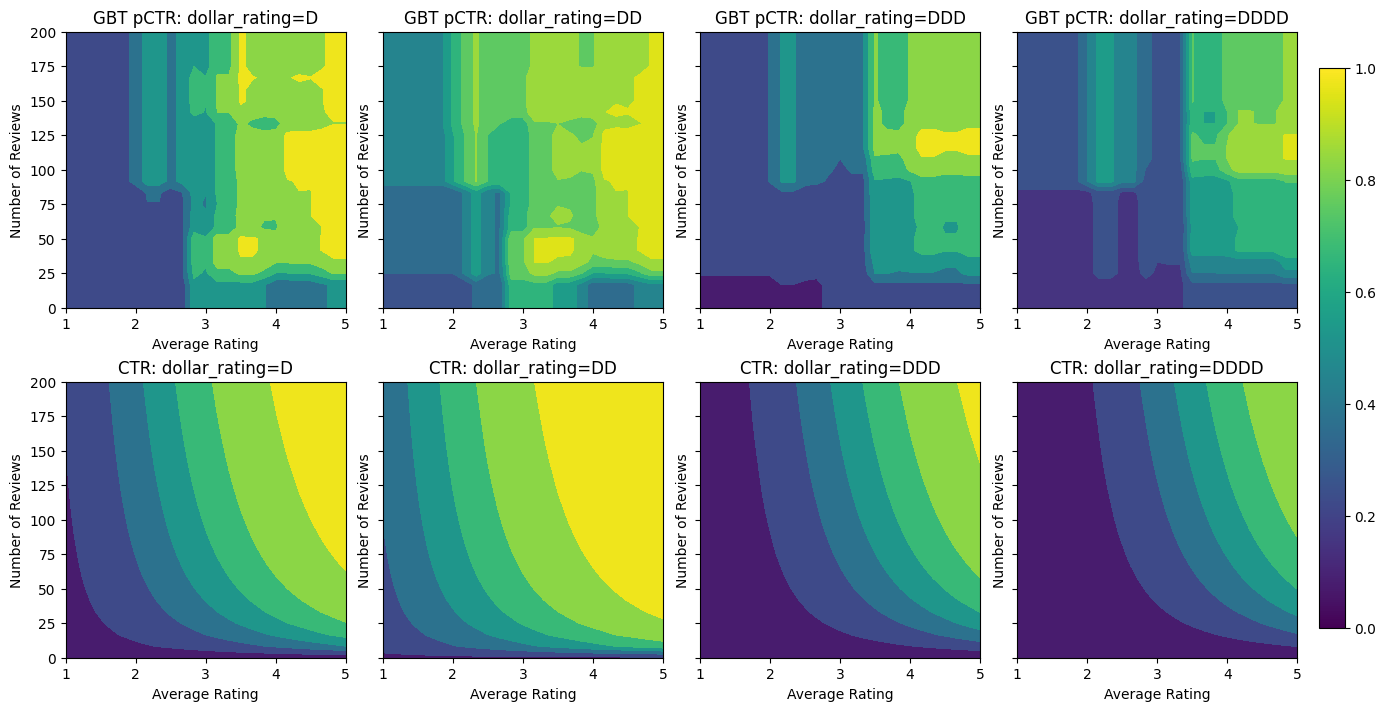
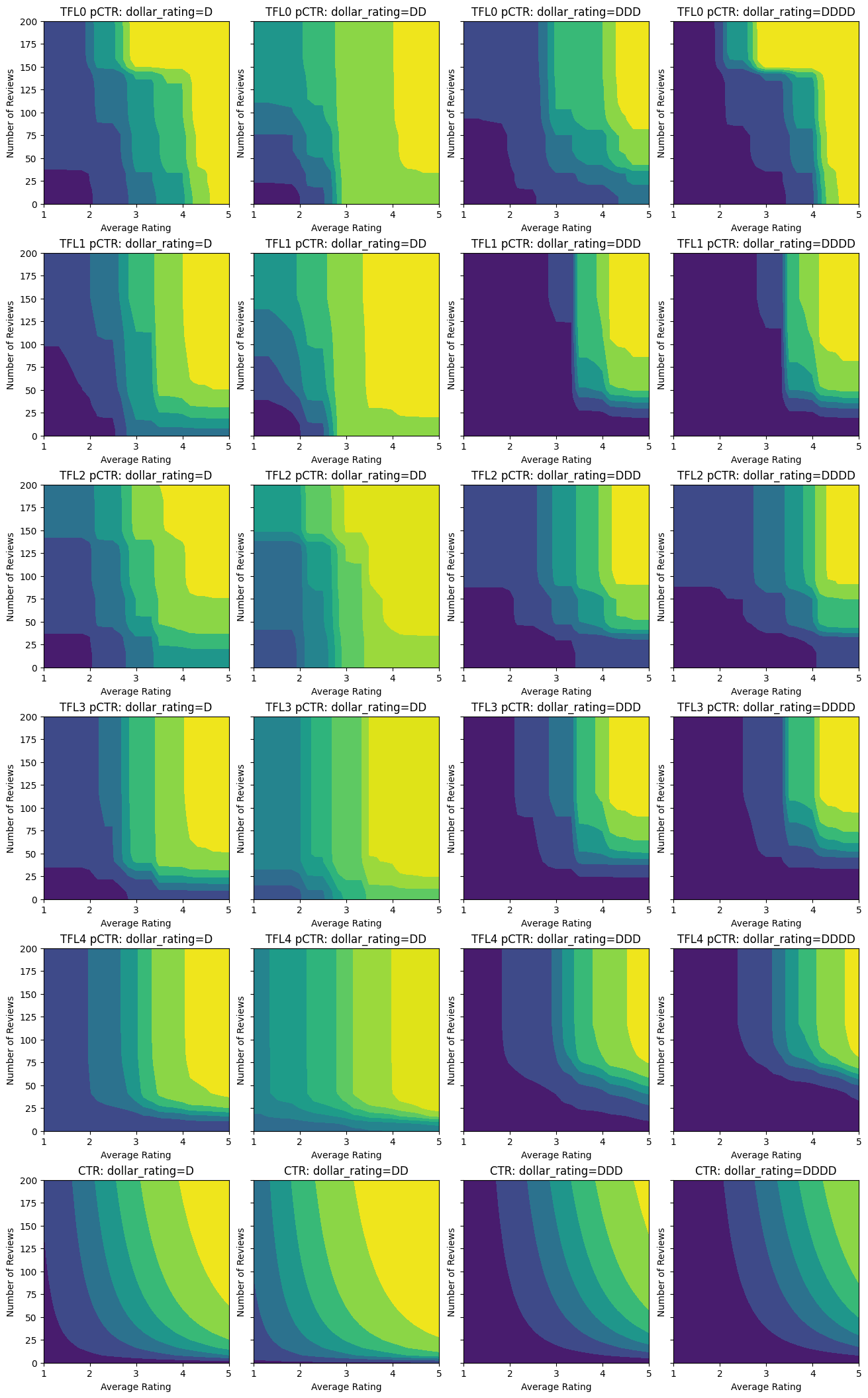
即使模型已捕捉到真實 CTR 的大致形狀,並且具有不錯的驗證指標,但在輸入空間的某些部分,它仍具有違反直覺的行為:估計的 CTR 會隨著平均評分或評論數的增加而降低。這是由於訓練資料集未充分涵蓋的區域缺少樣本點。模型根本無法僅從資料中推斷出正確的行為。
為了解決此問題,我們強制執行形狀限制,即模型必須輸出相對於平均評分和評論數單調遞增的值。稍後我們將看到如何在 TFL 中實作此功能。
擬合 DNN
我們可以對 DNN 分類器重複相同的步驟。我們可以觀察到類似的模式:評論數較少的樣本點不足會導致無意義的外插。
keras.utils.set_random_seed(42)
inputs = {
"num_reviews": keras.Input(shape=(1,), dtype=tf.float32),
"avg_rating": keras.Input(shape=(1), dtype=tf.float32),
"dollar_rating": keras.Input(shape=(1), dtype=tf.string),
}
inputs_flat = keras.layers.Concatenate()([
inputs["num_reviews"],
inputs["avg_rating"],
keras.layers.StringLookup(
vocabulary=dollar_ratings_vocab,
num_oov_indices=0,
output_mode="one_hot",
)(inputs["dollar_rating"]),
])
dense_layers = keras.Sequential(
[
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(1, activation=None),
],
name="dense_layers",
)
dnn_model = keras.Model(inputs=inputs, outputs=dense_layers(inputs_flat))
keras.utils.plot_model(
dnn_model, expand_nested=True, show_layer_names=False, rankdir="LR"
)

dnn_model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
dnn_model.fit(ds_train, epochs=200, verbose=0)
analyze_model([(dnn_model, "DNN")], from_logits=True)
Validation AUC: 0.7568147778511047 Testing AUC: 0.8183510899543762
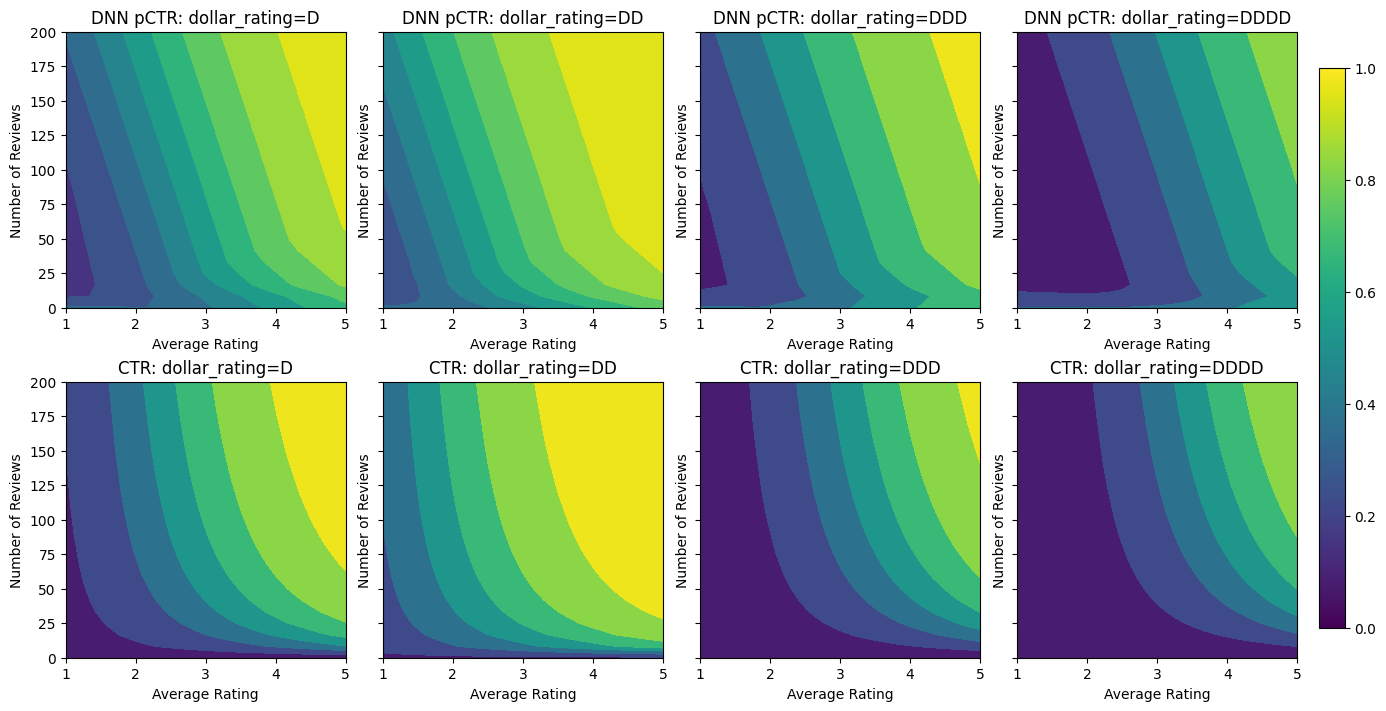
形狀限制
TensorFlow Lattice (TFL) 專注於強制執行形狀限制,以保護模型在訓練資料之外的行為。這些形狀限制會套用至 TFL Keras 層。其詳細資訊可在我們的 JMLR 論文中找到。
在本教學課程中,我們使用 TF 預製模型來涵蓋各種形狀限制,但請注意,所有這些步驟都可以使用從 TFL Keras 層建立的模型來完成。
使用 TFL 預製模型也需要
- 模型設定:定義模型架構以及每個特徵的形狀限制和正規化子。
- 特徵分析資料集:用於 TFL 初始化 (特徵分位數計算) 的資料集。
如需更詳盡的說明,請參閱預製模型或 API 文件。
單調性
我們先透過將單調性形狀限制新增至連續特徵來解決單調性問題。我們使用經過校正的格狀模型,並新增輸出校正:每個特徵都使用類別或分段線性校正器進行校正,然後饋送到格狀模型,接著是輸出分段線性校正器。
為了指示 TFL 強制執行形狀限制,我們在特徵設定中指定限制。以下程式碼顯示我們如何透過設定 monotonicity="increasing" 來要求輸出相對於 num_reviews 和 avg_rating 單調遞增。
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
我們現在使用 feature_analysis_data 來尋找和設定輸入特徵的分位數值。這些值可以預先計算,並根據訓練管線在特徵設定中明確設定。
feature_analysis_data = data_train.copy()
feature_analysis_data["dollar_rating"] = feature_analysis_data[
"dollar_rating"
].map({v: i for i, v in enumerate(dollar_ratings_vocab)})
feature_analysis_data = dict(feature_analysis_data)
feature_keypoints = tfl.premade_lib.compute_feature_keypoints(
feature_configs=model_config.feature_configs, features=feature_analysis_data
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
keras.utils.set_random_seed(42)
inputs = {
"num_reviews": keras.Input(shape=(1,), dtype=tf.float32),
"avg_rating": keras.Input(shape=(1), dtype=tf.float32),
"dollar_rating": keras.Input(shape=(1), dtype=tf.string),
}
ordered_inputs = [
inputs["num_reviews"],
inputs["avg_rating"],
keras.layers.StringLookup(
vocabulary=dollar_ratings_vocab,
num_oov_indices=0,
output_mode="int",
)(inputs["dollar_rating"]),
]
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_0 = keras.Model(inputs=inputs, outputs=outputs)
keras.utils.plot_model(
tfl_model_0, expand_nested=True, show_layer_names=False, rankdir="LR"
)
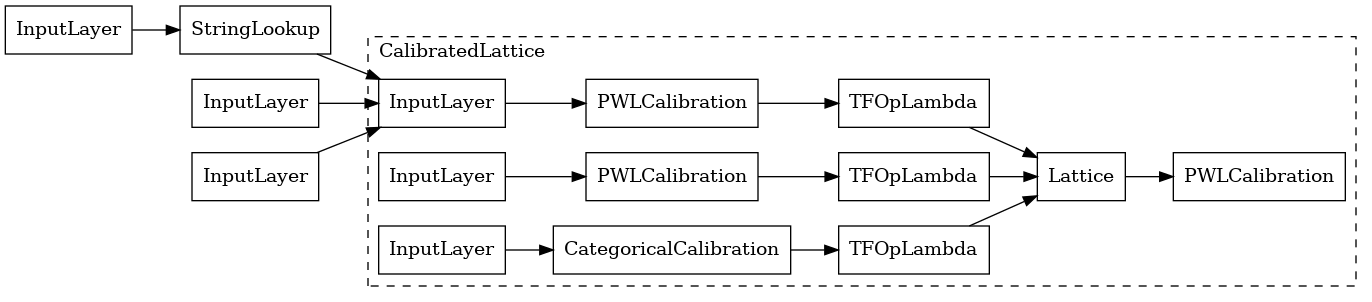
使用 CalibratedLatticeConfig 會建立一個預製分類器,該分類器首先將校正器套用至每個輸入 (數值特徵的分段線性函數),然後套用格狀層以非線性方式融合校正後的特徵。我們也啟用了輸出分段線性校正。
tfl_model_0.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_0.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_0, "TFL0")], from_logits=True)
Validation AUC: 0.7199402451515198 Testing AUC: 0.798313558101654
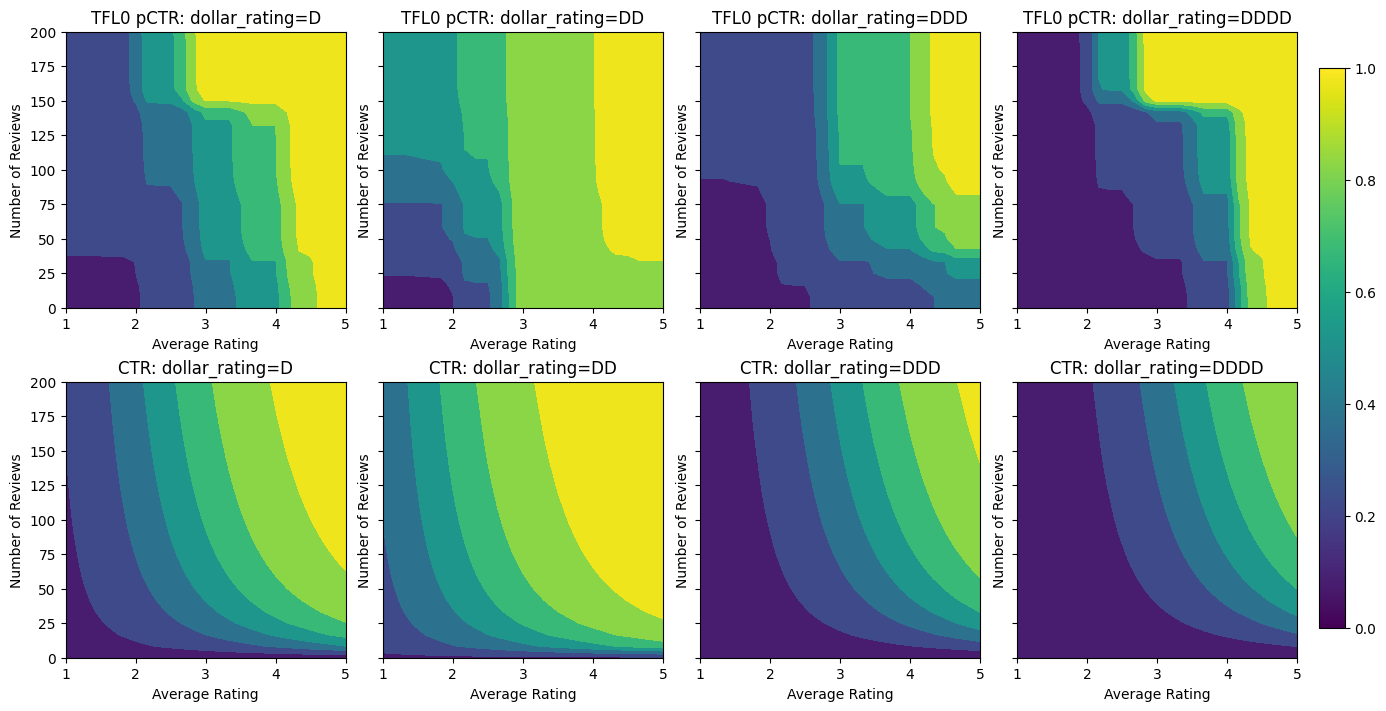
新增限制後,估計的 CTR 將始終隨著平均評分或評論數的增加而增加。這是透過確保校正器和格狀都是單調的來完成的。
類別校正的部分單調性
若要在第三個特徵 dollar_rating 上使用限制,我們應該回想一下,類別特徵在 TFL 中需要稍微不同的處理方式。在這裡,我們強制執行部分單調性限制,即當所有其他輸入都固定時,「DD」餐廳的輸出應大於「D」餐廳。這是透過使用特徵設定中的 monotonicity 設定來完成的。我們也需要使用 tfl.premade_lib.set_categorical_monotonicities 將字串值中指定的限制轉換為程式庫可理解的數值格式。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_1 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_1.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_1.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_1, "TFL1")], from_logits=True)
Validation AUC: 0.741411566734314 Testing AUC: 0.8500608205795288
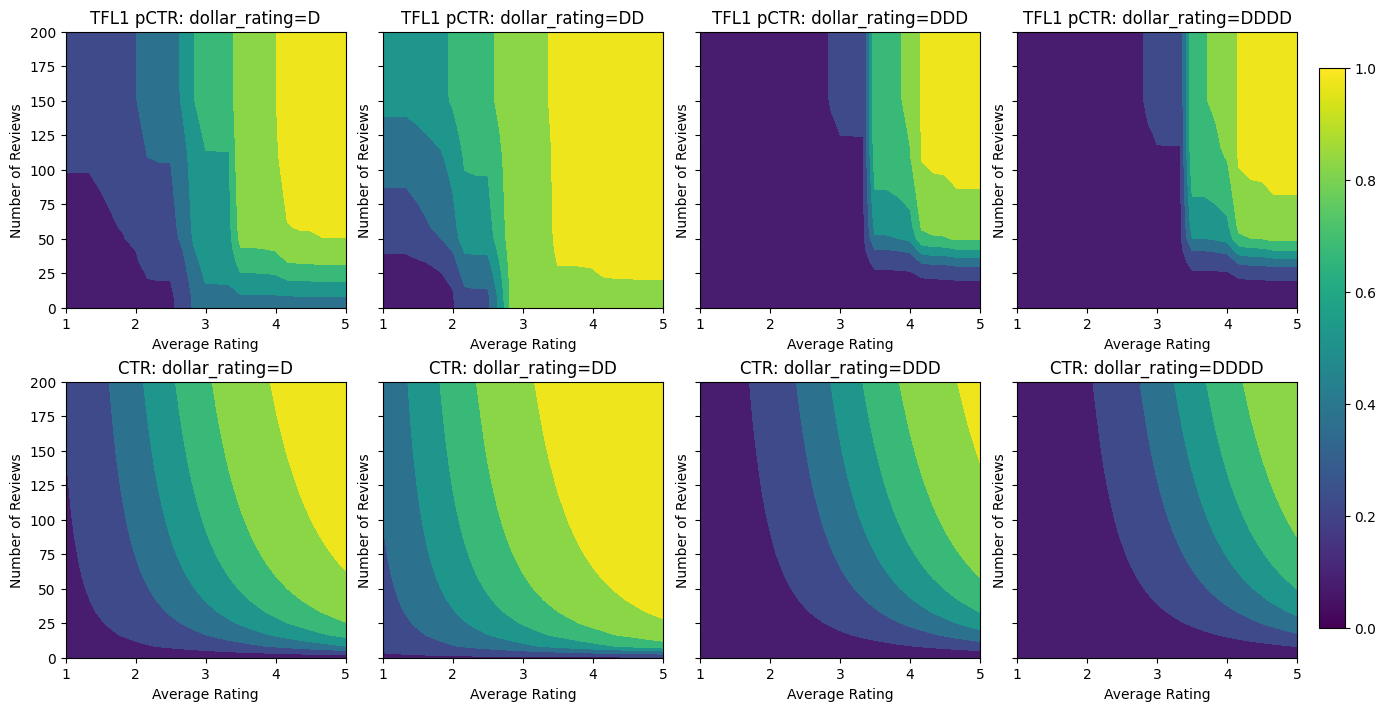
在這裡,我們也繪製了此模型在 dollar_rating 條件下的預測 CTR。請注意,我們要求的所有限制都在每個切片中都已實現。
2D 形狀限制:信任
對於只有一或兩個評論的餐廳,5 星評級可能是一個不可靠的評級 (餐廳實際上可能不好),而對於有數百個評論的餐廳,4 星評級則更可靠 (在這種情況下,餐廳可能很好)。我們可以看到,餐廳的評論數會影響我們對其平均評分的信任程度。
我們可以運用 TFL 信任限制來告知模型,一個特徵的較大 (或較小) 值表示對另一個特徵的更多依賴或信任。這是透過在特徵設定中設定 reflects_trust_in 設定來完成的。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"
),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_2 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_2.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_2.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_2, "TFL2")], from_logits=True)
Validation AUC: 0.774645209312439 Testing AUC: 0.8462862372398376
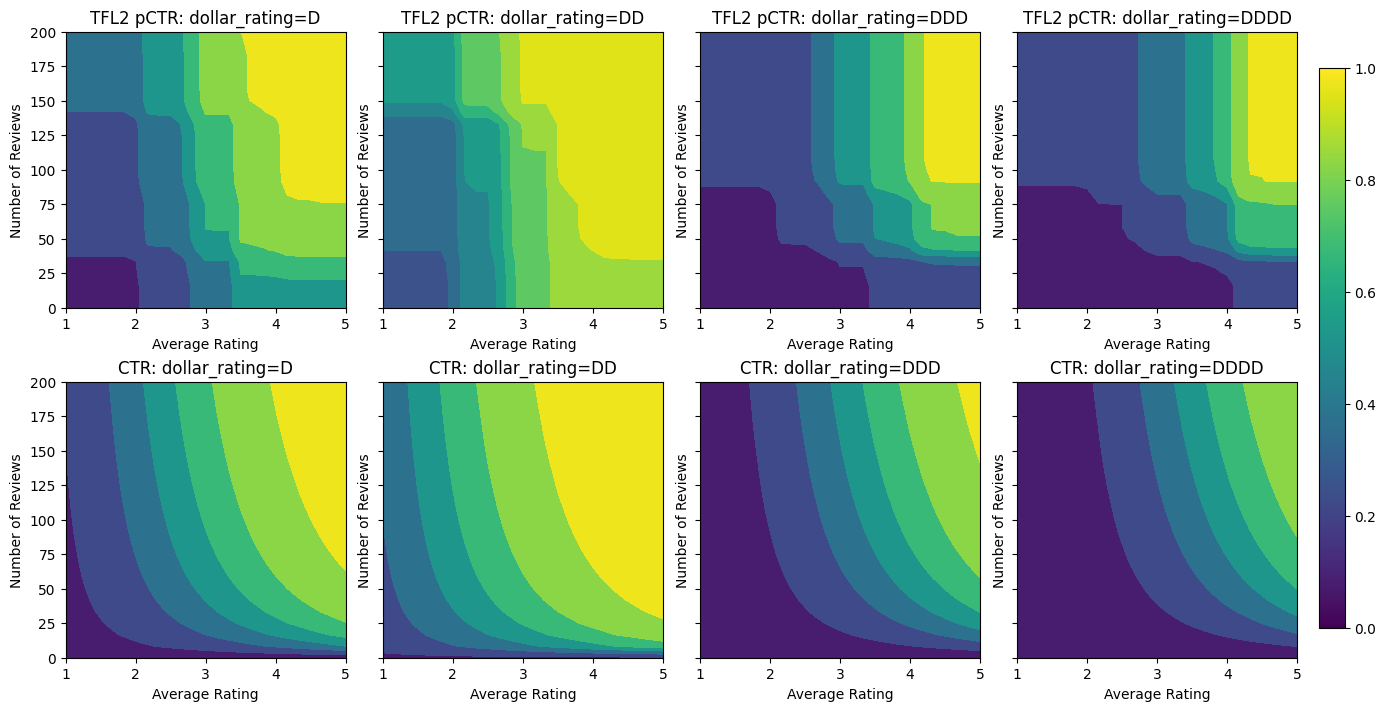
以下圖表呈現了經過訓練的格狀函數。由於信任限制,我們預期校正後的 num_reviews 的較大值會強制相對於校正後的 avg_rating 產生更高的斜率,從而在格狀輸出中產生更顯著的移動。
lattice_params = tfl_model_2.layers[-1].layers[-2].weights[0].numpy()
lat_mesh_x, lat_mesh_y = np.meshgrid(
np.linspace(0, 1, num=3),
np.linspace(0, 1, num=3),
)
lat_mesh_z = np.reshape(np.asarray(lattice_params[0::3]), (3, 3))
figure = plt.figure(figsize=(6, 6))
axes = figure.add_subplot(projection="3d")
axes.plot_wireframe(lat_mesh_x, lat_mesh_y, lat_mesh_z, color="dodgerblue")
plt.legend(["Lattice Lookup"])
plt.title("Trust")
plt.xlabel("Calibrated avg_rating")
plt.ylabel("Calibrated num_reviews")
plt.show()
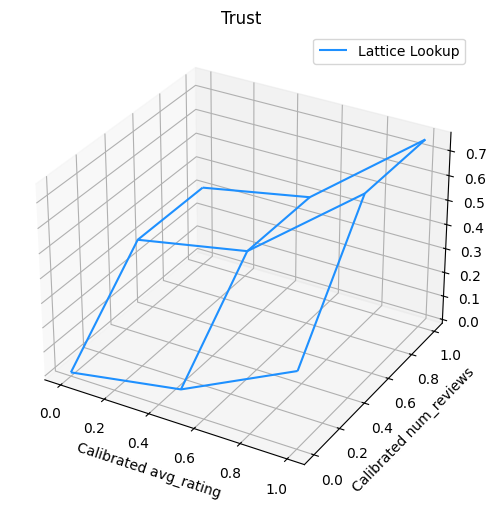
邊際效益遞減
邊際效益遞減表示,隨著我們增加值,增加某個特徵值的邊際收益將會減少。在我們的案例中,我們預期 num_reviews 特徵遵循此模式,因此我們可以相應地配置其校正器。請注意,我們可以將邊際效益遞減分解為兩個充分條件
- 校正器是單調遞增的,以及
- 校正器是凹函數 (設定
pwl_calibration_convexity="concave")。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=32,
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"
),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_3 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_3.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_3.fit(
ds_train,
epochs=100,
verbose=0
)
analyze_model([(tfl_model_3, "TFL3")], from_logits=True)
Validation AUC: 0.7506535053253174 Testing AUC: 0.8575603365898132
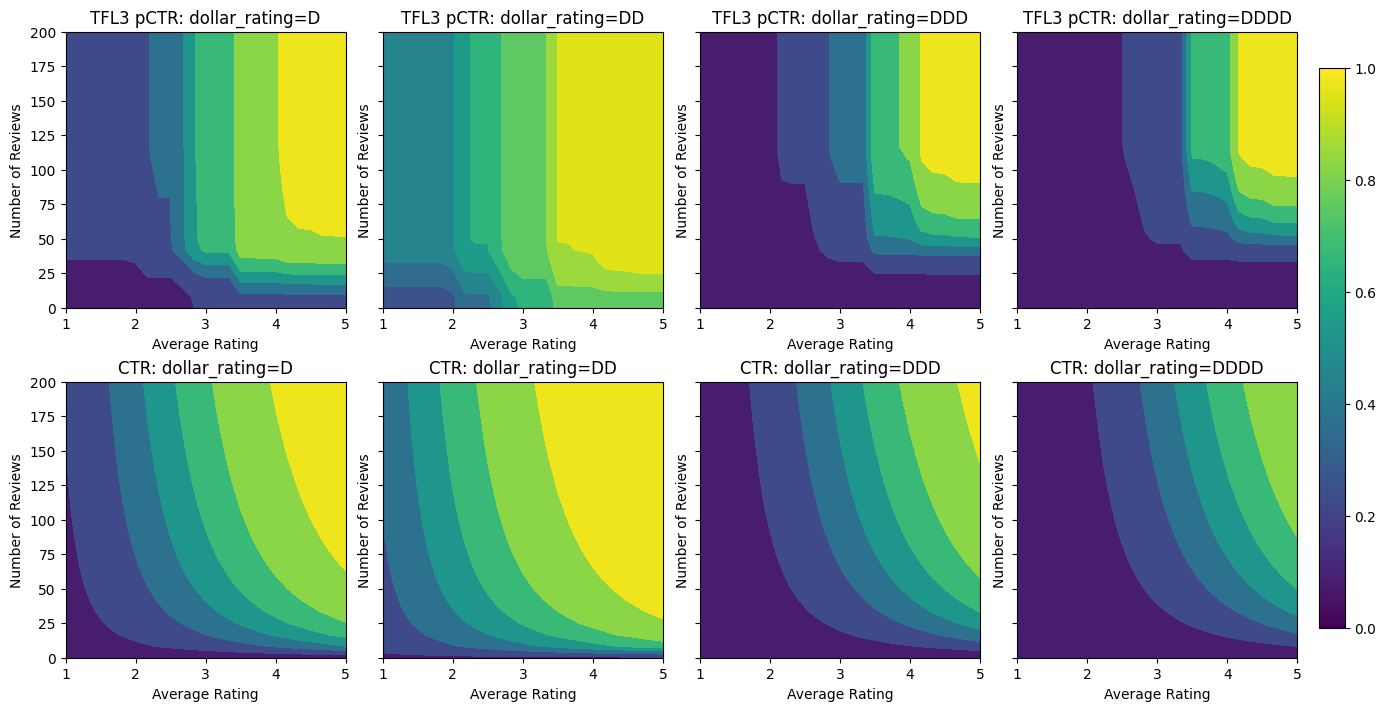
請注意,透過新增凹性限制,測試指標如何改善。預測圖也更符合實際情況。
平滑校正器
我們在上面的預測曲線中注意到,即使輸出在指定的特徵中是單調的,斜率的變化也很突然且難以解釋。這表示我們可能需要考慮使用 regularizer_configs 中的正規化子設定來平滑此校正器。
在這裡,我們套用 hessian 正規化子,使校正更線性。您也可以使用 laplacian 正規化子來展平校正器,並使用 wrinkle 正規化子來減少曲率的變化。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=32,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_hessian", l2=0.5),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"
),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_hessian", l2=0.5),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_hessian", l2=0.1),
],
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_4 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_4.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_4.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_4, "TFL4")], from_logits=True)
Validation AUC: 0.7562546730041504 Testing AUC: 0.8593733310699463
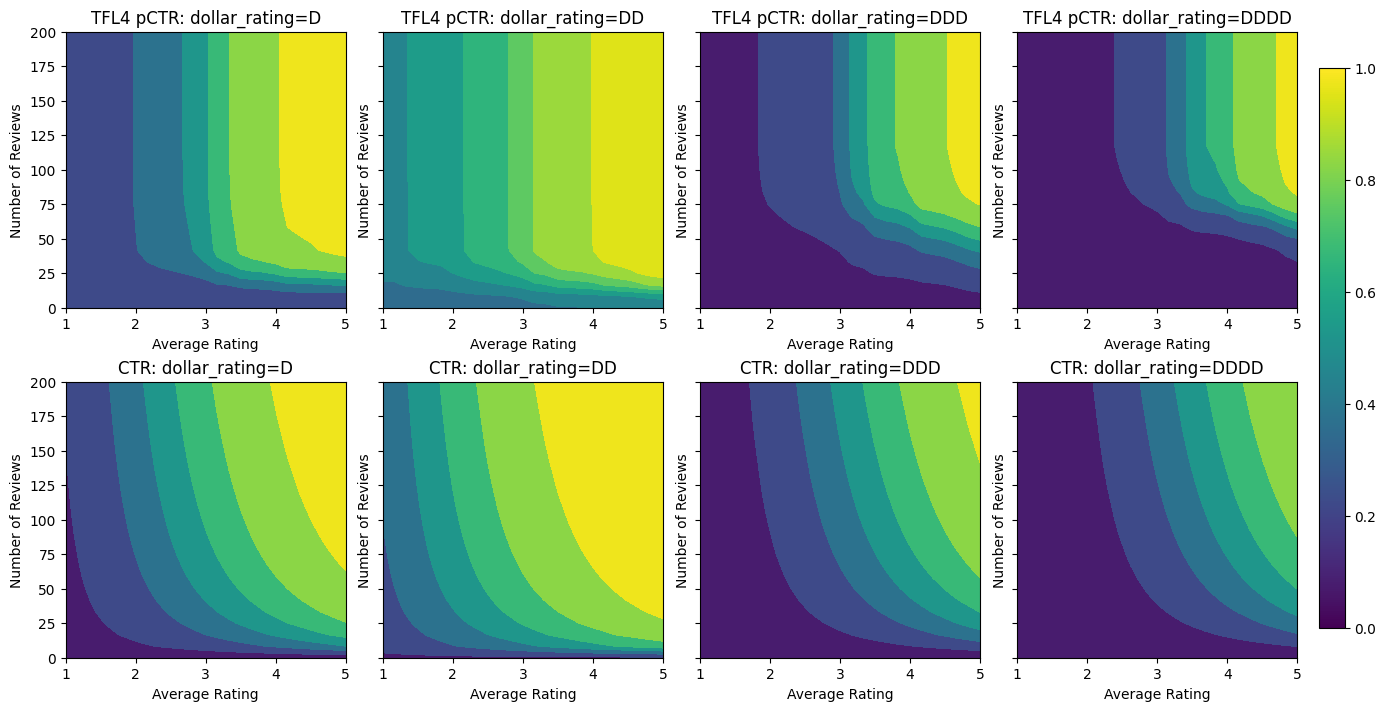
校正器現在已平滑,整體估計的 CTR 更符合實際情況。這反映在測試指標和等高線圖中。
在這裡,您可以看到我們將領域特定限制和正規化子新增至模型時,每個步驟的結果。
analyze_model(
[
(tfl_model_0, "TFL0"),
(tfl_model_1, "TFL1"),
(tfl_model_2, "TFL2"),
(tfl_model_3, "TFL3"),
(tfl_model_4, "TFL4"),
],
from_logits=True,
print_metrics=False,
)