
TensorFlow Lattice 是一個程式庫,實作彈性、可控制且可解譯的格狀模型。這個程式庫可讓您透過常識或政策驅動的形狀限制,將領域知識注入學習過程。這項作業是透過一組可滿足單調性、凸性和成對信任等限制的 Keras 層來完成。這個程式庫也提供易於設定的預製模型。
概念
本節是 Monotonic Calibrated Interpolated Look-Up Tables (JMLR 2016) 中描述的簡化版本。
格狀
格狀是經過內插的查閱表,可以用於逼近資料中任意的輸入輸出關係。它會在您的輸入空間上重疊規則格線,並學習格線頂點中輸出的值。對於測試點 \(x\),\(f(x)\) 是從 \(x\) 周圍的格狀值線性內插而來。
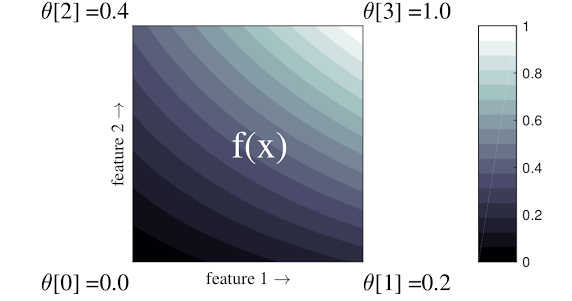
上面的簡單範例是具有 2 個輸入特徵和 4 個參數的函式:\(\theta=[0, 0.2, 0.4, 1]\),這些參數是輸入空間角落的函式值;函式的其餘部分是從這些參數內插而來。
函式 \(f(x)\) 可以擷取特徵之間的非線性互動。您可以將格狀參數想像成設置在規則格線地面上的桿子高度,而產生的函式就像是緊拉在四根桿子上的布。
使用 \(D\) 個特徵和沿著每個維度的 2 個頂點,規則格狀將有 \(2^D\) 個參數。若要擬合更彈性的函式,您可以指定在特徵空間上具有更精細格線的格狀,沿著每個維度具有更多頂點。格狀迴歸函式是連續且分段無限可微分的。
校正
假設先前的範例格狀代表已學習到的使用者滿意度,這是使用以下特徵計算出的建議當地咖啡店
- 咖啡價格,範圍為 0 到 20 美元
- 與使用者的距離,範圍為 0 到 30 公里
我們希望模型學習使用者對當地咖啡店建議的滿意度。TensorFlow Lattice 模型可以使用分段線性函式 (搭配 tfl.layers.PWLCalibration) 來校正和正規化輸入特徵,使其達到格狀可接受的範圍:在上述範例格狀中為 0.0 到 1.0。以下顯示具有 10 個關鍵點的範例校正函式
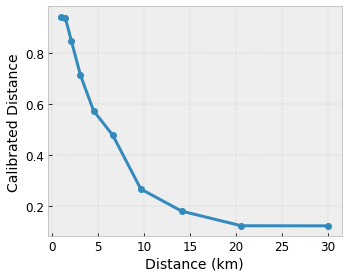
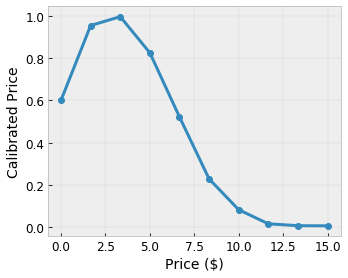
通常最好使用特徵的分位數做為輸入關鍵點。TensorFlow Lattice 預製模型可以自動將輸入關鍵點設定為特徵分位數。
對於類別特徵,TensorFlow Lattice 提供類別校正 (搭配 tfl.layers.CategoricalCalibration),其輸出邊界與饋入格狀的邊界類似。
集成
格狀層的參數數量會隨著輸入特徵的數量呈指數成長,因此無法良好擴展到非常高的維度。為了克服此限制,TensorFlow Lattice 提供格狀集成,它會結合 (平均) 數個微型格狀,讓模型能夠隨著特徵數量線性成長。
這個程式庫提供這些集成的兩種變化版本
隨機微型格狀 (RTL):每個子模型都使用特徵的隨機子集 (可重複取樣)。
晶體:晶體演算法首先訓練一個預先擬合模型,用於估計成對特徵互動。然後,它會排列最終集成,讓具有更多非線性互動的特徵位於相同的格狀中。
為何選擇 TensorFlow Lattice?
您可以在這篇 TF 部落格文章中找到 TensorFlow Lattice 的簡短介紹。
可解譯性
由於每一層的參數都是該層的輸出,因此很容易分析、理解和偵錯模型的每個部分。
準確且彈性的模型
使用精細格狀,您可以透過單一格狀層取得任意複雜的函式。在實務中,使用多層校正器和格狀通常效果良好,並且可以與大小相似的 DNN 模型相媲美或勝過它們。
常識形狀限制
真實世界的訓練資料可能無法充分代表執行階段資料。彈性 ML 解決方案 (例如 DNN 或樹系) 通常在訓練資料未涵蓋的輸入空間部分中表現出乎意料,甚至是極不穩定的行為。當政策或公平性限制可能遭到違反時,這種行為尤其成問題。
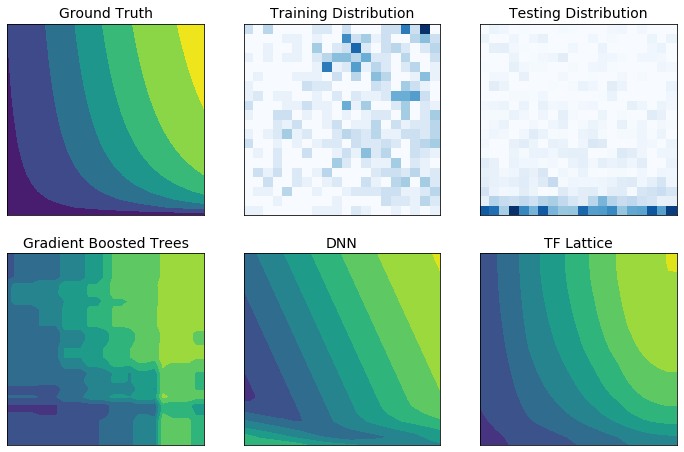
即使常見形式的正規化可以產生更合理的推斷,但標準正規化器也無法保證整個輸入空間 (尤其是在高維度輸入的情況下) 的合理模型行為。切換到行為更受控制且可預測的較簡單模型,可能會嚴重犧牲模型準確性。
TF Lattice 讓您可以繼續使用彈性模型,但提供多種選項,可透過語意上有意義的常識或政策驅動的形狀限制,將領域知識注入學習過程
- 單調性:您可以指定輸出應該僅針對輸入增加/減少。在我們的範例中,您可能會想要指定,與咖啡店的距離增加應該只會降低預測的使用者偏好。
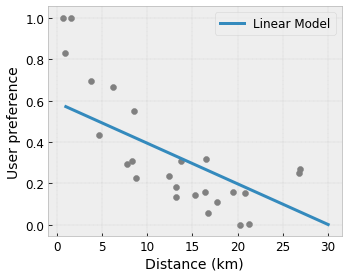
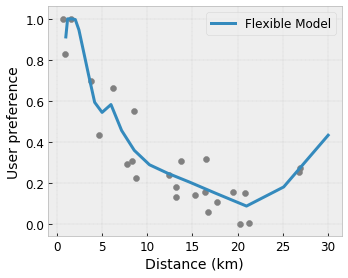
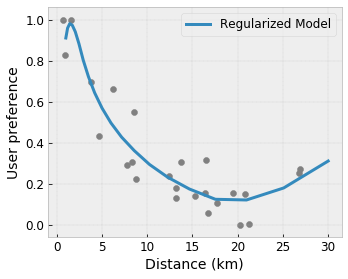
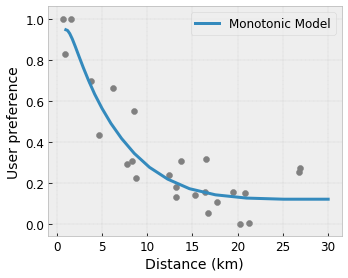
凸性/凹性:您可以指定函式形狀可以是凸形或凹形。與單調性混合使用時,這可以強制函式表示相對於給定特徵的報酬遞減。
單峰性:您可以指定函式應該具有唯一的峰值或唯一的谷值。這可讓您表示相對於特徵具有最佳點的函式。
成對信任:此限制適用於一對特徵,並表示一個輸入特徵在語意上反映對另一個特徵的信任。例如,較多的評論數量讓您對餐廳的平均星級評等更有信心。當評論數量較多時,模型對於星級評等的敏感度會更高 (亦即,相對於評等的斜率會更大)。
透過正規化器控制彈性
除了形狀限制之外,TensorFlow Lattice 還提供許多正規化器,可用於控制每一層函式的彈性和平滑度。
拉普拉斯正規化器:格狀/校正頂點/關鍵點的輸出會朝向其各自鄰近項的值正規化。這會產生更平坦的函式。
黑塞矩陣正規化器:這會懲罰 PWL 校正層的一階導數,使函式更線性。
皺紋正規化器:這會懲罰 PWL 校正層的二階導數,以避免曲率突然變化。它使函式更平滑。
扭力正規化器:格狀的輸出將會被正規化,以防止特徵之間產生扭力。換句話說,模型將被正規化,使其趨向於特徵貢獻之間的獨立性。
與其他 Keras 層混合搭配
您可以將 TF Lattice 層與其他 Keras 層結合使用,以建構部分受限或正規化的模型。例如,格狀或 PWL 校正層可以用於更深層網路的最後一層,其中包括嵌入或其他 Keras 層。
論文
- Deontological Ethics By Monotonicity Shape Constraints,Serena Wang、Maya Gupta,人工智慧與統計國際會議 (AISTATS),2020 年
- Shape Constraints for Set Functions,Andrew Cotter、Maya Gupta、H. Jiang、Erez Louidor、Jim Muller、Taman Narayan、Serena Wang、Tao Zhu。機器學習國際會議 (ICML),2019 年
- Diminishing Returns Shape Constraints for Interpretability and Regularization,Maya Gupta、Dara Bahri、Andrew Cotter、Kevin Canini,神經資訊處理系統進展 (NeurIPS),2018 年
- Deep Lattice Networks and Partial Monotonic Functions,Seungil You、Kevin Canini、David Ding、Jan Pfeifer、Maya R. Gupta,神經資訊處理系統進展 (NeurIPS),2017 年
- Fast and Flexible Monotonic Functions with Ensembles of Lattices,Mahdi Milani Fard、Kevin Canini、Andrew Cotter、Jan Pfeifer、Maya Gupta,神經資訊處理系統進展 (NeurIPS),2016 年
- Monotonic Calibrated Interpolated Look-Up Tables,Maya Gupta、Andrew Cotter、Jan Pfeifer、Konstantin Voevodski、Kevin Canini、Alexander Mangylov、Wojciech Moczydlowski、Alexander van Esbroeck,《機器學習研究期刊》(JMLR),2016 年
- Optimized Regression for Efficient Function Evaluation,Eric Garcia、Raman Arora、Maya R. Gupta,《IEEE 影像處理交易期刊》,2012 年
- Lattice Regression,Eric Garcia、Maya Gupta,神經資訊處理系統進展 (NeurIPS),2009 年
教學課程和 API 文件
對於常見的模型架構,您可以使用 Keras 預製模型。您也可以使用 TF Lattice Keras 層建立自訂模型,或與其他 Keras 層混合搭配。查看完整 API 文件以瞭解詳情。