
本教學課程說明如何使用 TensorFlow Lite 建構 Android 應用程式,以分類自然語言文字。此應用程式專為實體 Android 裝置設計,但也可以在裝置模擬器上執行。
範例應用程式使用 TensorFlow Lite 將文字分類為正面或負面,並使用自然語言 (NL) 工作程式庫來啟用文字分類機器學習模型的執行。
如果您要更新現有的專案,可以使用範例應用程式做為參考或範本。如需瞭解如何將文字分類新增至現有應用程式,請參閱更新和修改應用程式。
文字分類總覽
文字分類是一種機器學習工作,旨在將一組預先定義的類別指派給開放式文字。文字分類模型是在自然語言文字語料庫上訓練而成,其中字詞或詞組是手動分類的。
經過訓練的模型會接收文字做為輸入,並嘗試根據模型訓練分類的一組已知類別來分類文字。例如,本範例中的模型會接受一段文字,並判斷文字的情感是正面還是負面。針對每段文字,文字分類模型會輸出一個分數,指出文字正確分類為正面或負面的信心程度。
如需本教學課程中的模型產生方式的詳細資訊,請參閱使用 TensorFlow Lite Model Maker 進行文字分類教學課程。
模型和資料集
本教學課程使用使用 SST-2 (史丹佛情感樹庫) 資料集訓練的模型。SST-2 包含 67,349 則用於訓練的電影評論和 872 則用於測試的電影評論,每則評論都分類為正面或負面。本應用程式中使用的模型是使用 TensorFlow Lite Model Maker 工具訓練的。
範例應用程式使用下列預先訓練的模型
平均字詞向量 (
NLClassifier) - Task Library 的NLClassifier會將輸入文字分類為不同的類別,並且可以處理大多數文字分類模型。MobileBERT (
BertNLClassifier) - Task Library 的BertNLClassifier與 NLClassifier 類似,但專為需要圖外 Wordpiece 和 Sentencepiece 權杖化的案例量身打造。
設定並執行範例應用程式
若要設定文字分類應用程式,請從 GitHub 下載範例應用程式,並使用 Android Studio 執行。
系統需求
- Android Studio 2021.1.1 (Bumblebee) 或更高版本。
- Android SDK 31 或更高版本
- Android 裝置,最低作業系統版本為 SDK 21 (Android 7.0 - Nougat),且已啟用開發人員模式,或 Android 模擬器。
取得範例程式碼
建立範例程式碼的本機副本。您將使用此程式碼在 Android Studio 中建立專案,並執行範例應用程式。
複製並設定範例程式碼的方法
- 複製 git 存放區
git clone https://github.com/tensorflow/examples.git
- 或者,設定您的 git 執行個體以使用稀疏簽出,讓您只有文字分類範例應用程式的檔案
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
匯入並執行專案
從下載的範例程式碼建立專案、建構專案,然後執行專案。
匯入並建構範例程式碼專案的方法
- 啟動 Android Studio。
- 在 Android Studio 中,選取「File (檔案) > New (新增) > Import Project (匯入專案)」。
- 瀏覽至包含 build.gradle 檔案的範例程式碼目錄 (
.../examples/lite/examples/text_classification/android/build.gradle),然後選取該目錄。 - 如果 Android Studio 要求 Gradle 同步處理,請選擇「OK (確定)」。
- 確認您的 Android 裝置已連接到電腦且已啟用開發人員模式。按一下綠色的
Run (執行)箭頭。
如果您選取正確的目錄,Android Studio 會建立新專案並建構專案。此程序可能需要幾分鐘時間,具體取決於電腦的速度以及您是否已將 Android Studio 用於其他專案。建構完成後,Android Studio 會在「Build Output (建構輸出)」狀態面板中顯示 BUILD SUCCESSFUL (建構成功) 訊息。
執行專案的方法
- 在 Android Studio 中,依序選取「Run (執行) > Run… (執行…)」來執行專案。
- 選取已連結的 Android 裝置 (或模擬器) 以測試應用程式。
使用應用程式
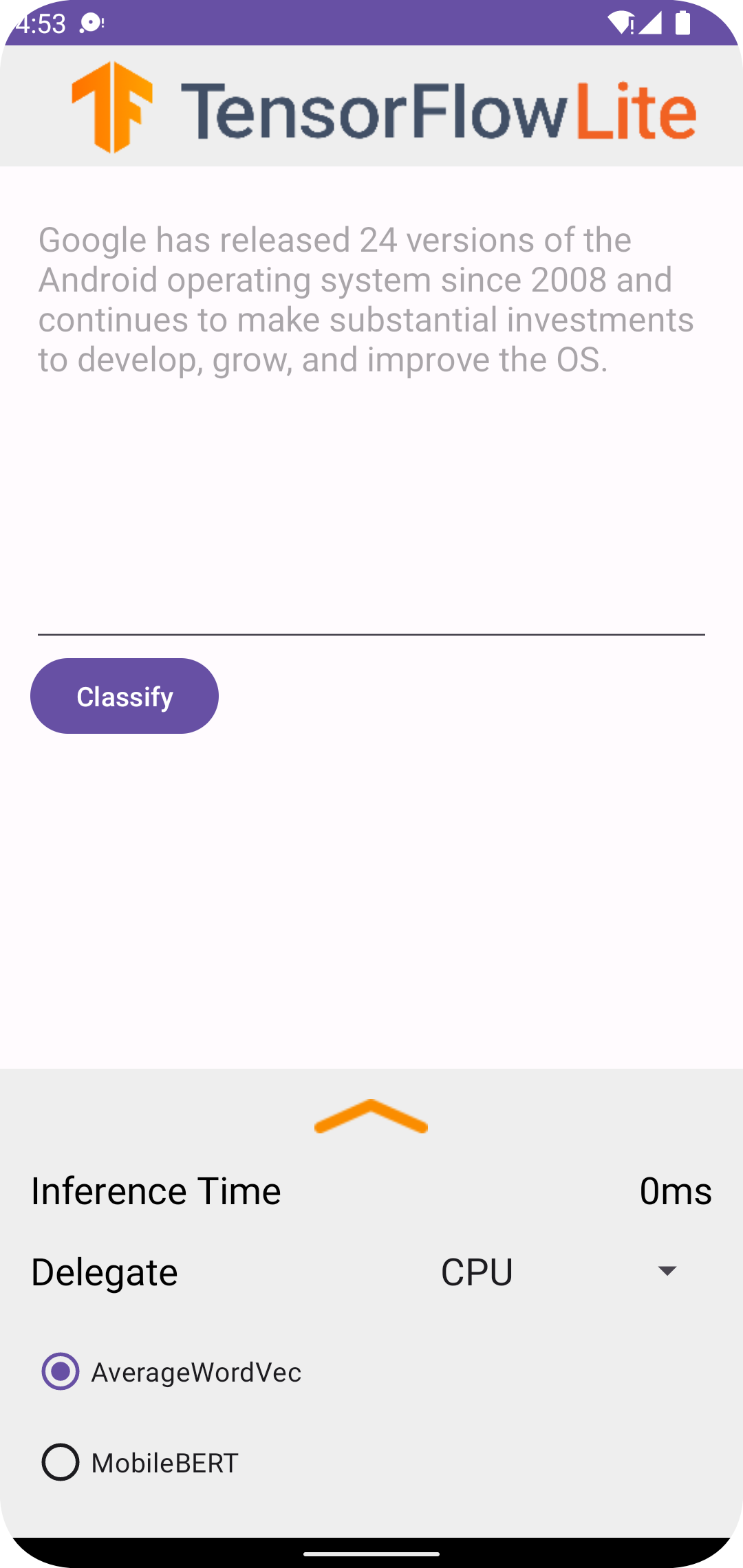
在 Android Studio 中執行專案後,應用程式會自動在連結的裝置或裝置模擬器上開啟。
使用文字分類器的方法
- 在文字方塊中輸入一段文字。
- 從「Delegate (委派)」下拉式選單中,選擇
CPU或NNAPI。 - 選擇
AverageWordVec或MobileBERT來指定模型。 - 選擇「Classify (分類)」。
應用程式會輸出正面分數和負面分數。這兩個分數總和為 1,並測量輸入文字的情感為正面或負面的可能性。數字越高表示信心程度越高。
您現在有一個可運作的文字分類應用程式。請使用以下章節來更深入瞭解範例應用程式的運作方式,以及如何在您的生產應用程式中實作文字分類功能
範例應用程式的運作方式
應用程式使用自然語言 (NL) 工作程式庫套件來實作文字分類模型。平均字詞向量和 MobileBERT 這兩個模型是使用 TensorFlow Lite Model Maker 訓練的。應用程式預設在 CPU 上執行,並可選擇使用 NNAPI 委派進行硬體加速。
下列檔案和目錄包含此文字分類應用程式的重要程式碼
- TextClassificationHelper.kt - 初始化文字分類器並處理模型和委派選取。
- MainActivity.kt - 實作應用程式,包括呼叫
TextClassificationHelper和ResultsAdapter。 - ResultsAdapter.kt - 處理和格式化結果。
修改應用程式
以下章節說明修改您自己的 Android 應用程式以執行範例應用程式中顯示之模型的關鍵步驟。這些說明使用範例應用程式做為參考點。您自己的應用程式所需的特定變更可能與範例應用程式不同。
開啟或建立 Android 專案
您需要在 Android Studio 中建立 Android 開發專案,才能繼續進行後續說明。請按照以下說明開啟現有專案或建立新專案。
開啟現有的 Android 開發專案的方法
- 在 Android Studio 中,依序選取「File (檔案) > Open (開啟)」,然後選取現有專案。
建立基本的 Android 開發專案的方法
- 按照 Android Studio 中的說明建立基本專案。
如需 Android Studio 使用方式的詳細資訊,請參閱Android Studio 文件。
新增專案依附元件
在您自己的應用程式中,您必須新增特定的專案依附元件,才能執行 TensorFlow Lite 機器學習模型,並存取將字串等資料轉換為張量資料格式 (可由您使用的模型處理) 的公用程式函式。
以下說明說明如何在您自己的 Android 應用程式專案中新增必要的專案和模組依附元件。
新增模組依附元件的方法
在使用 TensorFlow Lite 的模組中,更新模組的
build.gradle檔案以加入下列依附元件。在範例應用程式中,依附元件位於 app/build.gradle
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }專案必須包含文字工作程式庫 (
tensorflow-lite-task-text)。如果您想要修改此應用程式以在圖形處理單元 (GPU) 上執行,GPU 程式庫 (
tensorflow-lite-gpu-delegate-plugin) 會提供在 GPU 上執行應用程式的基礎架構,而 Delegate (tensorflow-lite-gpu) 則提供相容性清單。在本教學課程的範圍之外,不討論在 GPU 上執行此應用程式。在 Android Studio 中,依序選取「File (檔案) > Sync Project with Gradle Files (將專案與 Gradle 檔案同步處理)」,同步處理專案依附元件。
初始化 ML 模型
在您的 Android 應用程式中,您必須先使用參數初始化 TensorFlow Lite 機器學習模型,才能使用模型執行預測。
TensorFlow Lite 模型會儲存為 *.tflite 檔案。模型檔案包含預測邏輯,通常包含關於如何解譯預測結果 (例如預測類別名稱) 的中繼資料。模型檔案通常儲存在開發專案的 src/main/assets 目錄中,如程式碼範例所示
<project>/src/main/assets/mobilebert.tflite<project>/src/main/assets/wordvec.tflite
為了方便起見和程式碼可讀性,範例宣告了一個隨附物件,用於定義模型的設定。
在您的應用程式中初始化模型的方法
建立隨附物件以定義模型的設定。在範例應用程式中,此物件位於 TextClassificationHelper.kt
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }藉由建構分類器物件來建立模型的設定,並使用
BertNLClassifier或NLClassifier建構 TensorFlow Lite 物件。在範例應用程式中,這位於 TextClassificationHelper.kt 中的
initClassifier函式中fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }
啟用硬體加速 (選用)
在您的應用程式中初始化 TensorFlow Lite 模型時,您應考慮使用硬體加速功能來加快模型的預測計算速度。TensorFlow Lite 委派是軟體模組,可使用行動裝置上的專用處理硬體 (例如圖形處理單元 (GPU) 或張量處理單元 (TPU)) 加速機器學習模型的執行。
在您的應用程式中啟用硬體加速的方法
建立變數以定義應用程式將使用的委派。在範例應用程式中,此變數位於 TextClassificationHelper.kt 的開頭
var currentDelegate: Int = 0建立委派選取器。在範例應用程式中,委派選取器位於 TextClassificationHelper.kt 中的
initClassifier函式中val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
建議使用委派來執行 TensorFlow Lite 模型,但並非必要。如需瞭解如何搭配 TensorFlow Lite 使用委派的詳細資訊,請參閱TensorFlow Lite 委派。
準備模型的資料
在您的 Android 應用程式中,您的程式碼會藉由將現有資料 (例如原始文字) 轉換為 Tensor 資料格式 (可由您的模型處理) 來提供資料給模型以進行解譯。您傳遞至模型的 Tensor 中的資料必須具有特定的維度或形狀,才能與用於訓練模型的資料格式相符。
此文字分類應用程式接受 字串做為輸入,並且模型完全在英文語料庫上訓練。特殊字元和非英文字詞在推論期間會遭到忽略。
將文字資料提供給模型的方法
使用
init區塊呼叫initClassifier函式。在範例應用程式中,init位於 TextClassificationHelper.kt 中init { initClassifier() }
執行預測
在您的 Android 應用程式中,一旦您初始化 BertNLClassifier 或 NLClassifier 物件,您就可以開始饋送輸入文字,讓模型將其分類為「正面」或「負面」。
執行預測的方法
建立
classify函式,其使用選取的分類器 (currentModel) 並測量分類輸入文字所花費的時間 (inferenceTime)。在範例應用程式中,classify函式位於 TextClassificationHelper.kt 中fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }將
classify的結果傳遞至接聽器物件。fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
處理模型輸出
在您輸入一行文字後,模型會產生介於 0 和 1 之間的浮點數預測分數,用於「正面」和「負面」類別。
從模型取得預測結果的方法
為接聽器物件建立
onResult函式以處理輸出。在範例應用程式中,接聽器物件位於 MainActivity.kt 中private val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }為接聽器物件新增
onError函式以處理錯誤private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
模型傳回一組預測結果後,您的應用程式可以透過向使用者呈現結果或執行其他邏輯來根據這些預測採取行動。範例應用程式會在使用者介面中列出預測分數。
後續步驟
- 透過使用 TensorFlow Lite Model Maker 進行文字分類教學課程,從頭開始訓練和實作模型。
- 探索更多TensorFlow 文字處理工具。
- 在 TensorFlow Hub 上下載其他 BERT 模型。
- 在範例中探索 TensorFlow Lite 的各種用途。
- 在模型章節中,進一步瞭解如何搭配 TensorFlow Lite 使用機器學習模型。
- 在TensorFlow Lite 開發人員指南中,進一步瞭解如何在行動應用程式中實作機器學習。