
近年來,可插入神經網路架構的新型可微分圖形層技術興起。從空間轉換器到可微分圖形渲染器,這些新層利用多年來在電腦視覺和圖形研究中獲得的知識,建構出更有效率的新型網路架構。將幾何先驗知識和限制明確建模到神經網路中,為可以穩健、有效率地訓練,更重要的是,以自我監督方式訓練的架構開啟了大門。
從高階來看,電腦圖形管線需要 3D 物件的表示法及其在場景中的絕對定位、物件材質的描述、光源和相機。然後,渲染器會解譯此場景描述,以產生合成渲染。
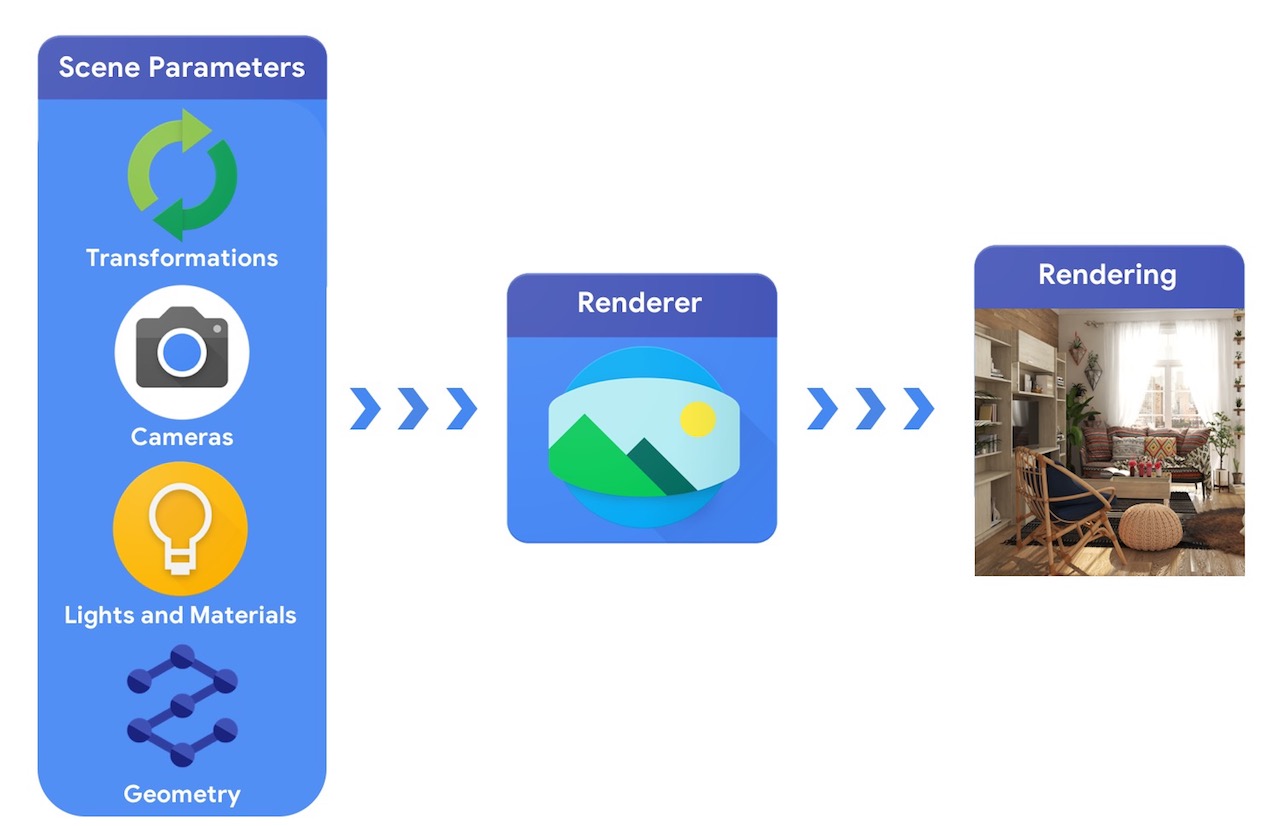
相較之下,電腦視覺系統會從影像開始,嘗試推斷場景的參數。這樣可以預測場景中有哪些物件、物件是由什麼材質製成,以及物件的 3D 位置和方向。
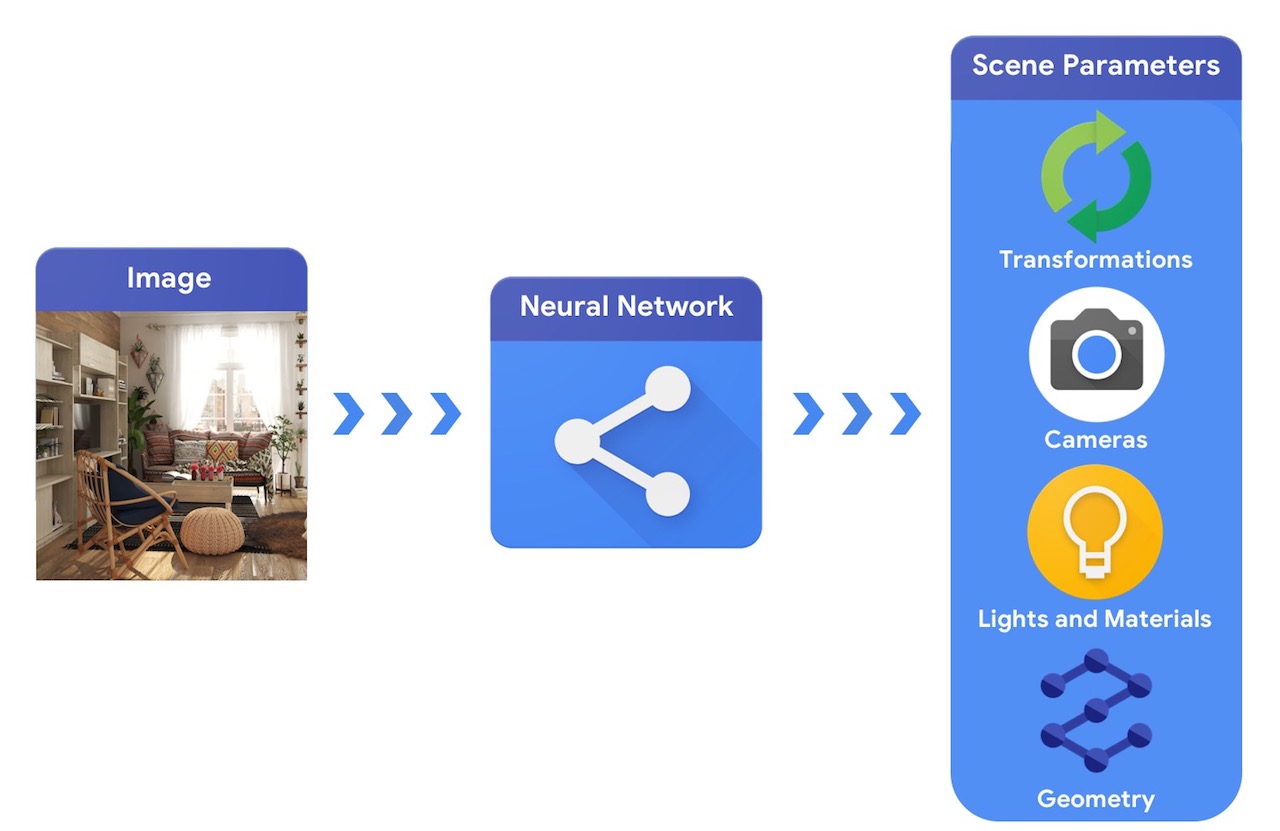
訓練能夠解決這些複雜 3D 視覺工作的機器學習系統通常需要大量資料。由於標記資料是既昂貴又複雜的流程,因此務必建立機制來設計機器學習模型,讓模型能夠理解 3D 世界,同時在沒有太多監督的情況下接受訓練。結合電腦視覺和電腦圖形技術提供獨特的機會,可以充分利用大量現成的未標記資料。如下圖所示,舉例來說,這可以使用綜合分析來達成,其中視覺系統會擷取場景參數,而圖形系統會根據這些參數渲染回影像。如果渲染結果與原始影像相符,則表示視覺系統已準確擷取場景參數。在此設定中,電腦視覺和電腦圖形相輔相成,形成類似自動編碼器的單一機器學習系統,可以自我監督方式進行訓練。
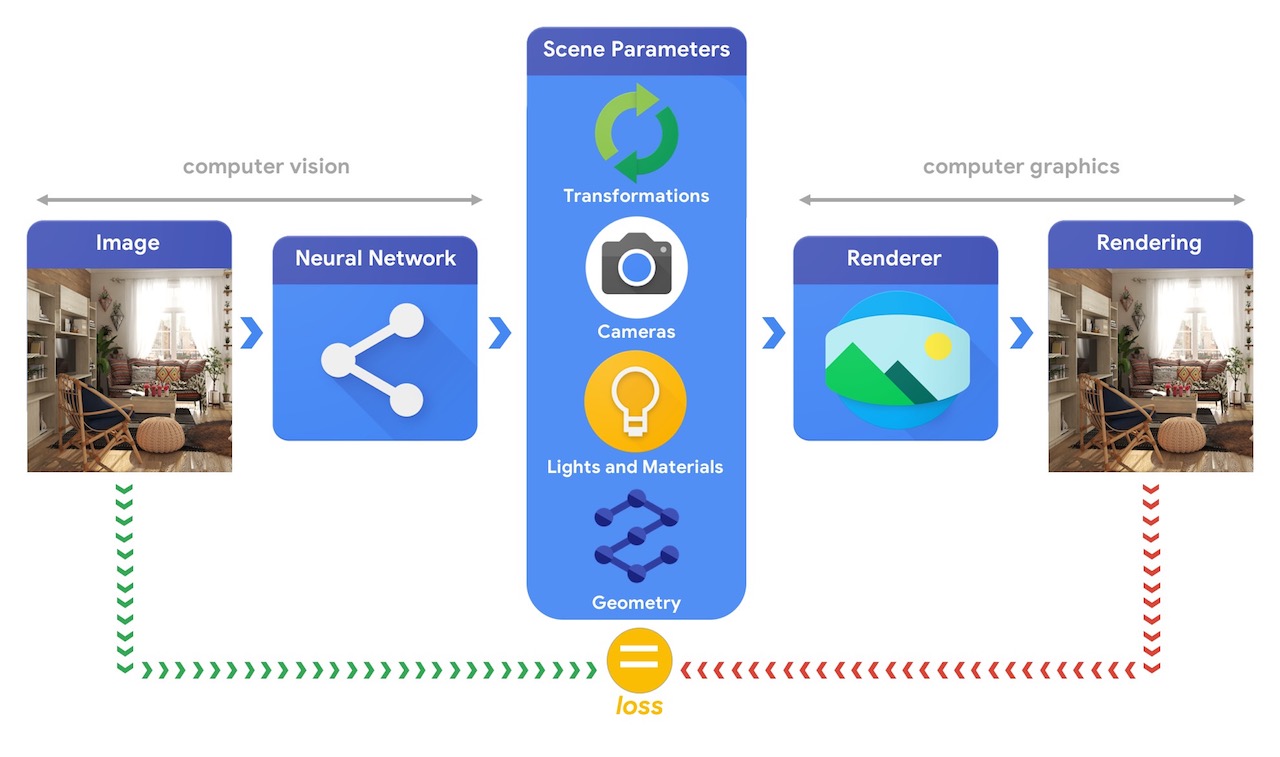
Tensorflow Graphics 的開發旨在協助應對這些類型的挑戰,為此,它提供了一組可微分的圖形和幾何圖層 (例如相機、反射率模型、空間轉換、網格卷積) 和 3D 檢視器功能 (例如 3D TensorBoard),可用於訓練和偵錯您選擇的機器學習模型。