
|
|
|
 在 GitHub 上檢視原始碼 在 GitHub 上檢視原始碼
|
|
本教學課程將示範使用 Tensorflow Federated 以使用者層級差分隱私訓練模型的建議最佳實務。我們將使用 Abadi 等人,「具有差分隱私的深度學習」 的 DP-SGD 演算法,並針對 McMahan 等人,「以差分隱私學習遞迴語言模型」 中聯邦環境中的使用者層級 DP 進行修改。
差分隱私 (DP) 是一種廣泛使用的方法,用於在執行學習任務時限制和量化敏感資料的隱私洩漏。使用使用者層級 DP 訓練模型可保證模型不太可能學習到任何關於任何個人資料的重大資訊,但仍然 (希望!) 可以學習到許多用戶端資料中存在的模式。
我們將在聯邦 EMNIST 資料集上訓練模型。實用性和隱私之間存在固有的權衡,並且可能難以訓練具有高隱私的模型,使其效能與最先進的非私有模型一樣好。為了在本教學課程中權宜之計,我們將僅訓練 100 輪,犧牲一些品質,以便示範如何以高隱私進行訓練。如果我們使用更多訓練輪數,我們當然可以獲得準確度稍高的私有模型,但不會像在沒有 DP 的情況下訓練的模型那麼高。
開始之前
首先,讓我們確保筆記本已連線到已編譯相關元件的後端。
pip install --quiet --upgrade dp-accountingpip install --quiet --upgrade tensorflow-federated
本教學課程需要的一些匯入項目。我們將使用 tensorflow_federated,這是一個用於在分散式資料上進行機器學習和其他運算的開放原始碼架構,以及 dp_accounting,這是一個用於分析差分隱私演算法的開放原始碼程式庫。
import collections
import dp_accounting
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
執行以下「Hello World」範例,以確保 TFF 環境已正確設定。如果無法運作,請參閱 安裝 指南以取得指示。
@tff.federated_computation
def hello_world():
return 'Hello, World!'
hello_world()
b'Hello, World!'
下載並預先處理聯邦 EMNIST 資料集。
def get_emnist_dataset():
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data(
only_digits=True)
def element_fn(element):
return collections.OrderedDict(
x=tf.expand_dims(element['pixels'], -1), y=element['label'])
def preprocess_train_dataset(dataset):
# Use buffer_size same as the maximum client dataset size,
# 418 for Federated EMNIST
return (dataset.map(element_fn)
.shuffle(buffer_size=418)
.repeat(1)
.batch(32, drop_remainder=False))
def preprocess_test_dataset(dataset):
return dataset.map(element_fn).batch(128, drop_remainder=False)
emnist_train = emnist_train.preprocess(preprocess_train_dataset)
emnist_test = preprocess_test_dataset(
emnist_test.create_tf_dataset_from_all_clients())
return emnist_train, emnist_test
train_data, test_data = get_emnist_dataset()
定義我們的模型。
def my_model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Reshape(input_shape=(28, 28, 1), target_shape=(28 * 28,)),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(10)])
return tff.learning.models.from_keras_model(
keras_model=model,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
input_spec=test_data.element_spec,
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
判斷模型的雜訊敏感度。
為了獲得使用者層級 DP 保證,我們必須以兩種方式變更基本聯邦平均演算法。首先,用戶端的模型更新必須在傳輸到伺服器之前進行剪裁,以限制任何一個用戶端的最大影響。其次,伺服器必須在平均之前向使用者更新總和新增足夠的雜訊,以掩蓋最壞情況下的用戶端影響。
對於剪裁,我們使用 Andrew 等人,2021 年,「具有自適應剪裁的差分隱私學習」 的自適應剪裁方法,因此無需明確設定剪裁範數。
新增雜訊通常會降低模型的實用性,但我們可以透過兩個旋鈕控制每輪平均更新中的雜訊量:新增至總和的高斯雜訊標準差,以及平均值中的用戶端數量。我們的策略是首先確定模型在每輪用戶端數量相對較少的情況下可以容忍多少雜訊,而模型實用性損失是可以接受的。然後,為了訓練最終模型,我們可以增加總和中的雜訊量,同時按比例放大每輪用戶端的數量 (假設資料集足夠大以支援每輪那麼多用戶端)。這不太可能顯著影響模型品質,因為唯一的效果是降低由於用戶端取樣造成的變異數 (實際上,我們將驗證在我們的案例中確實如此)。
為此,我們首先訓練一系列模型,每輪 50 個用戶端,雜訊量逐漸增加。具體來說,我們增加「noise_multiplier」,它是雜訊標準差與剪裁範數的比率。由於我們使用自適應剪裁,這表示雜訊的實際幅度會逐輪變更。
total_clients = len(train_data.client_ids)
def train(rounds, noise_multiplier, clients_per_round, data_frame):
# Using the `dp_aggregator` here turns on differential privacy with adaptive
# clipping.
aggregation_factory = tff.learning.model_update_aggregator.dp_aggregator(
noise_multiplier, clients_per_round)
# We use Poisson subsampling which gives slightly tighter privacy guarantees
# compared to having a fixed number of clients per round. The actual number of
# clients per round is stochastic with mean clients_per_round.
sampling_prob = clients_per_round / total_clients
# Build a federated averaging process.
# Typically a non-adaptive server optimizer is used because the noise in the
# updates can cause the second moment accumulators to become very large
# prematurely.
learning_process = tff.learning.algorithms.build_unweighted_fed_avg(
my_model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0, momentum=0.9),
model_aggregator=aggregation_factory)
eval_process = tff.learning.build_federated_evaluation(my_model_fn)
# Training loop.
state = learning_process.initialize()
for round in range(rounds):
if round % 5 == 0:
model_weights = learning_process.get_model_weights(state)
metrics = eval_process(model_weights, [test_data])['eval']
if round < 25 or round % 25 == 0:
print(f'Round {round:3d}: {metrics}')
data_frame = data_frame.append({'Round': round,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
# Sample clients for a round. Note that if your dataset is large and
# sampling_prob is small, it would be faster to use gap sampling.
x = np.random.uniform(size=total_clients)
sampled_clients = [
train_data.client_ids[i] for i in range(total_clients)
if x[i] < sampling_prob]
sampled_train_data = [
train_data.create_tf_dataset_for_client(client)
for client in sampled_clients]
# Use selected clients for update.
result = learning_process.next(state, sampled_train_data)
state = result.state
metrics = result.metrics
model_weights = learning_process.get_model_weights(state)
metrics = eval_process(model_weights, [test_data])['eval']
print(f'Round {rounds:3d}: {metrics}')
data_frame = data_frame.append({'Round': rounds,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
return data_frame
data_frame = pd.DataFrame()
rounds = 100
clients_per_round = 50
for noise_multiplier in [0.0, 0.5, 0.75, 1.0]:
print(f'Starting training with noise multiplier: {noise_multiplier}')
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
print()
Starting training with noise multiplier: 0.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.112289384), ('loss', 2.5190482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.19075724), ('loss', 2.2449977)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.18115693), ('loss', 2.163907)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49970612), ('loss', 2.01017)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5333317), ('loss', 1.8350543)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.5828517), ('loss', 1.6551636)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7352077), ('loss', 0.8700141)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7769152), ('loss', 0.6992781)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.8049814), ('loss', 0.62453026)])
Starting training with noise multiplier: 0.5
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.09526841), ('loss', 2.4332638)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.20128821), ('loss', 2.2664592)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.35472178), ('loss', 2.130336)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.5480995), ('loss', 1.9713942)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.42246276), ('loss', 1.8045483)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.624902), ('loss', 1.4785467)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7265625), ('loss', 0.85801566)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.77720904), ('loss', 0.70615387)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7702537), ('loss', 0.72331005)])
Starting training with noise multiplier: 0.75
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.098672606), ('loss', 2.422002)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.11794671), ('loss', 2.2227976)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.3208513), ('loss', 2.083766)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49752644), ('loss', 1.8728142)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5816761), ('loss', 1.6084186)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.62896746), ('loss', 1.378527)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.73153406), ('loss', 0.8705139)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7789724), ('loss', 0.7113147)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.70944357), ('loss', 0.89495045)])
Starting training with noise multiplier: 1.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.12002841), ('loss', 2.60482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.104574844), ('loss', 2.3388205)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.29966694), ('loss', 2.089262)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.4067398), ('loss', 1.9109797)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5123677), ('loss', 1.6472703)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.56416535), ('loss', 1.4362282)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.62323666), ('loss', 1.1682972)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.55968356), ('loss', 1.4779186)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.382837), ('loss', 1.9680436)])
現在我們可以視覺化這些執行結果的評估集準確度和損失。
import matplotlib.pyplot as plt
import seaborn as sns
def make_plot(data_frame):
plt.figure(figsize=(15, 5))
dff = data_frame.rename(
columns={'sparse_categorical_accuracy': 'Accuracy', 'loss': 'Loss'})
plt.subplot(121)
sns.lineplot(data=dff, x='Round', y='Accuracy', hue='NoiseMultiplier', palette='dark')
plt.subplot(122)
sns.lineplot(data=dff, x='Round', y='Loss', hue='NoiseMultiplier', palette='dark')
make_plot(data_frame)
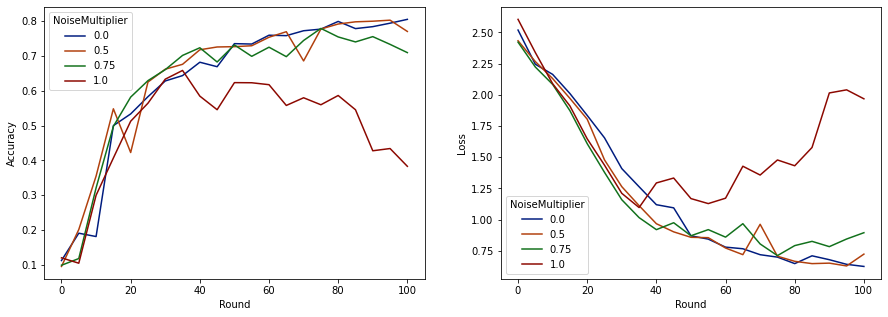
看來在每輪預期有 50 個用戶端的情況下,此模型可以容忍高達 0.5 的雜訊乘數,而不會降低模型品質。雜訊乘數為 0.75 時,模型似乎會稍微退化,而 1.0 會使模型發散。
模型品質和隱私之間通常存在權衡。我們使用的雜訊越高,在相同的訓練時間和用戶端數量下,我們可以獲得的隱私就越多。相反地,如果雜訊較少,我們可能會獲得更準確的模型,但我們必須使用更多每輪用戶端進行訓練,才能達到我們的目標隱私層級。
透過上述實驗,我們可能會決定為了更快地訓練最終模型,0.75 時模型略微劣化是可以接受的,但假設我們想要符合 0.5 雜訊乘數模型的效能。
現在我們可以使用 dp_accounting 函數來判斷我們每輪需要多少預期用戶端才能獲得可接受的隱私。標準做法是選擇 delta 略小於資料集中記錄數量的倒數。此資料集總共有 3383 位訓練使用者,因此我們的目標是 (2, 1e-5)-DP。
我們使用 dp_accounting.calibrate_dp_mechanism 來搜尋每輪用戶端的數量。我們用來估計給定 dp_accounting.DpEvent 的隱私權會計師 (RdpAccountant) 是基於 Wang 等人 (2018) 和 Mironov 等人 (2019)。
total_clients = 3383
noise_to_clients_ratio = 0.01
target_delta = 1e-5
target_eps = 2
# Initialize arguments to dp_accounting.calibrate_dp_mechanism.
# No-arg callable that returns a fresh accountant.
make_fresh_accountant = dp_accounting.rdp.RdpAccountant
# Create function that takes expected clients per round and returns a
# dp_accounting.DpEvent representing the full training process.
def make_event_from_param(clients_per_round):
q = clients_per_round / total_clients
noise_multiplier = clients_per_round * noise_to_clients_ratio
gaussian_event = dp_accounting.GaussianDpEvent(noise_multiplier)
sampled_event = dp_accounting.PoissonSampledDpEvent(q, gaussian_event)
composed_event = dp_accounting.SelfComposedDpEvent(sampled_event, rounds)
return composed_event
# Create object representing the search range [1, 3383].
bracket_interval = dp_accounting.ExplicitBracketInterval(1, total_clients)
# Perform search for smallest clients_per_round achieving the target privacy.
clients_per_round = dp_accounting.calibrate_dp_mechanism(
make_fresh_accountant, make_event_from_param, target_eps, target_delta,
bracket_interval, discrete=True
)
noise_multiplier = clients_per_round * noise_to_clients_ratio
print(f'To get ({target_eps}, {target_delta})-DP, use {clients_per_round} '
f'clients with noise multiplier {noise_multiplier}.')
To get (2, 1e-05)-DP, use 120 clients with noise multiplier 1.2.
現在我們可以訓練我們最終發布的私有模型。
rounds = 100
noise_multiplier = 1.2
clients_per_round = 120
data_frame = pd.DataFrame()
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
make_plot(data_frame)
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.08260678), ('loss', 2.6334999)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.1492212), ('loss', 2.259542)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.28847474), ('loss', 2.155699)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.3989518), ('loss', 2.0156953)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5086697), ('loss', 1.8261365)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.6204692), ('loss', 1.5602393)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.70008814), ('loss', 0.91155165)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.78421336), ('loss', 0.6820159)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7955525), ('loss', 0.6585961)])
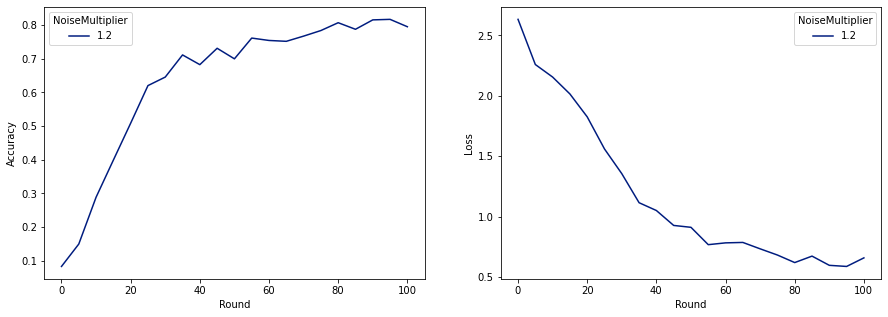
正如我們所見,最終模型的損失和準確度與未經雜訊訓練的模型相似,但此模型滿足 (2, 1e-5)-DP。